---
license: apache-2.0
pipeline_tag: video-to-video
---
# ⚡ FlashVSR
**Towards Real-Time Diffusion-Based Streaming Video Super-Resolution**
**Authors:** Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, Tianfan Xue


-blue)
-blue)

 **Your star means a lot for us to develop this project!** :star:
**Your star means a lot for us to develop this project!** :star:
 ---
### 🌟 Abstract
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
---
### 📰 News
- **Nov 2025 — 🎉 [FlashVSR v1.1](https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1) released:** enhanced stability + fidelity
- **Oct 2025 — [FlashVSR v1](https://huggingface.co/JunhaoZhuang/FlashVSR) (initial release)**: Inference code and model weights are available now! 🎉
- **Bug Fix (October 21, 2025):** Fixed `local_attention_mask` update logic to prevent artifacts when switching between different aspect ratios during continuous inference.
- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
---
### 📢 Important Quality Note (ComfyUI & other third-party implementations)
First of all, huge thanks to the community for the fast adoption, feedback, and contributions to FlashVSR! 🙌
During community testing, we noticed that some third-party implementations of FlashVSR (e.g. early ComfyUI versions) do **not include our Locality-Constrained Sparse Attention (LCSA)** module and instead fall back to **dense attention**. This may lead to **noticeable quality degradation**, especially at higher resolutions.
Community discussion: https://github.com/kijai/ComfyUI-WanVideoWrapper/issues/1441
Below is a comparison example provided by a community member:
| Fig.1 – LR Input Video | Fig.2 – 3rd-party (no LCSA) | Fig.3 – Official FlashVSR |
|------------------|-----------------------------------------------|--------------------------------------|
| | | |
✅ The **official FlashVSR pipeline (this repository)**:
- **Better preserves fine structures and details**
- **Effectively avoids texture aliasing and visual artifacts**
We are also working on a **version that does not rely on the Block-Sparse Attention library** while keeping **the same output quality**; this alternative may run slower than the optimized original implementation.
Thanks again to the community for actively testing and helping improve FlashVSR together! 🚀
---
### 📋 TODO
- ✅ Release inference code and model weights
- ⬜ Release dataset (VSR-120K)
---
### 🚀 Getting Started
Follow these steps to set up and run **FlashVSR** on your local machine:
> ⚠️ **Note:** This project is primarily designed and optimized for **4× video super-resolution**.
> We **strongly recommend** using the **4× SR setting** to achieve better results and stability. ✅
#### 1️⃣ Clone the Repository
```bash
git clone https://github.com/OpenImagingLab/FlashVSR
cd FlashVSR
````
#### 2️⃣ Set Up the Python Environment
Create and activate the environment (**Python 3.11.13**):
```bash
conda create -n flashvsr python=3.11.13
conda activate flashvsr
```
Install project dependencies:
```bash
pip install -e .
pip install -r requirements.txt
```
#### 3️⃣ Install Block-Sparse Attention (Required)
FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
> **⚠️ Note:**
>
> * The Block-Sparse Attention build process can be memory-intensive, especially when compiling in parallel with multiple `ninja` jobs. It is recommended to keep sufficient memory available during compilation to avoid OOM errors. Once the build is complete, runtime memory usage is stable and not an issue.
> * Based on our testing, the Block-Sparse Attention backend works correctly on **NVIDIA A100 and A800** (Ampere) with **ideal acceleration performance**, and it also runs correctly on **H200** (Hopper) but the acceleration is limited due to hardware scheduling differences and sparse kernel behavior. **Compatibility and performance on other GPUs (e.g., RTX 40/50 series or H800) are currently unknown**. For more details, please refer to the official documentation: https://github.com/mit-han-lab/Block-Sparse-Attention
```bash
# ✅ Recommended: clone and install in a separate clean folder (outside the FlashVSR repo)
git clone https://github.com/mit-han-lab/Block-Sparse-Attention
cd Block-Sparse-Attention
pip install packaging
pip install ninja
python setup.py install
```
#### 4️⃣ Download Model Weights from Hugging Face
FlashVSR provides both **v1** and **v1.1** model weights on Hugging Face (via **Git LFS**).
Please install Git LFS first:
```bash
# From the repo root
cd examples/WanVSR
# Install Git LFS (once per machine)
git lfs install
# Clone v1 (original) or v1.1 (recommended)
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR # v1
# or
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1 # v1.1
```
After cloning, you should have one of the following folders:
```
./examples/WanVSR/FlashVSR/ # v1
./examples/WanVSR/FlashVSR-v1.1/ # v1.1
│
├── LQ_proj_in.ckpt
├── TCDecoder.ckpt
├── Wan2.1_VAE.pth
├── diffusion_pytorch_model_streaming_dmd.safetensors
└── README.md
```
> Inference scripts automatically load weights from the corresponding folder.
---
#### 5️⃣ Run Inference
```bash
# From the repo root
cd examples/WanVSR
# v1 (original)
python infer_flashvsr_full.py
# or
python infer_flashvsr_tiny.py
# or
python infer_flashvsr_tiny_long_video.py
# v1.1 (recommended)
python infer_flashvsr_v1.1_full.py
# or
python infer_flashvsr_v1.1_tiny.py
# or
python infer_flashvsr_v1.1_tiny_long_video.py
```
---
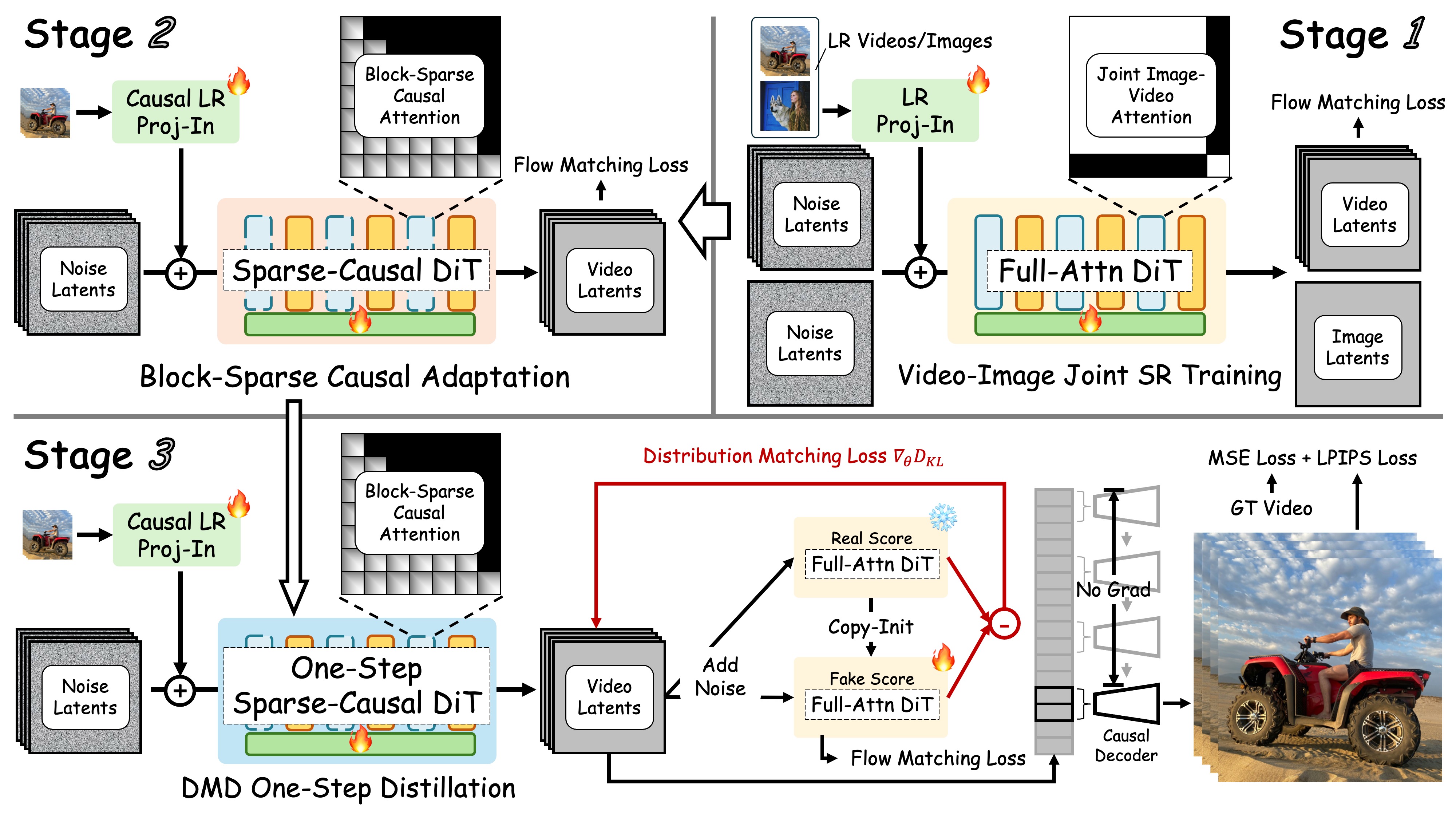
### 🛠️ Method
The overview of **FlashVSR**. This framework features:
* **Three-Stage Distillation Pipeline** for streaming VSR training.
* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
---
### 🌟 Abstract
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
---
### 📰 News
- **Nov 2025 — 🎉 [FlashVSR v1.1](https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1) released:** enhanced stability + fidelity
- **Oct 2025 — [FlashVSR v1](https://huggingface.co/JunhaoZhuang/FlashVSR) (initial release)**: Inference code and model weights are available now! 🎉
- **Bug Fix (October 21, 2025):** Fixed `local_attention_mask` update logic to prevent artifacts when switching between different aspect ratios during continuous inference.
- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
---
### 📢 Important Quality Note (ComfyUI & other third-party implementations)
First of all, huge thanks to the community for the fast adoption, feedback, and contributions to FlashVSR! 🙌
During community testing, we noticed that some third-party implementations of FlashVSR (e.g. early ComfyUI versions) do **not include our Locality-Constrained Sparse Attention (LCSA)** module and instead fall back to **dense attention**. This may lead to **noticeable quality degradation**, especially at higher resolutions.
Community discussion: https://github.com/kijai/ComfyUI-WanVideoWrapper/issues/1441
Below is a comparison example provided by a community member:
| Fig.1 – LR Input Video | Fig.2 – 3rd-party (no LCSA) | Fig.3 – Official FlashVSR |
|------------------|-----------------------------------------------|--------------------------------------|
| | | |
✅ The **official FlashVSR pipeline (this repository)**:
- **Better preserves fine structures and details**
- **Effectively avoids texture aliasing and visual artifacts**
We are also working on a **version that does not rely on the Block-Sparse Attention library** while keeping **the same output quality**; this alternative may run slower than the optimized original implementation.
Thanks again to the community for actively testing and helping improve FlashVSR together! 🚀
---
### 📋 TODO
- ✅ Release inference code and model weights
- ⬜ Release dataset (VSR-120K)
---
### 🚀 Getting Started
Follow these steps to set up and run **FlashVSR** on your local machine:
> ⚠️ **Note:** This project is primarily designed and optimized for **4× video super-resolution**.
> We **strongly recommend** using the **4× SR setting** to achieve better results and stability. ✅
#### 1️⃣ Clone the Repository
```bash
git clone https://github.com/OpenImagingLab/FlashVSR
cd FlashVSR
````
#### 2️⃣ Set Up the Python Environment
Create and activate the environment (**Python 3.11.13**):
```bash
conda create -n flashvsr python=3.11.13
conda activate flashvsr
```
Install project dependencies:
```bash
pip install -e .
pip install -r requirements.txt
```
#### 3️⃣ Install Block-Sparse Attention (Required)
FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
> **⚠️ Note:**
>
> * The Block-Sparse Attention build process can be memory-intensive, especially when compiling in parallel with multiple `ninja` jobs. It is recommended to keep sufficient memory available during compilation to avoid OOM errors. Once the build is complete, runtime memory usage is stable and not an issue.
> * Based on our testing, the Block-Sparse Attention backend works correctly on **NVIDIA A100 and A800** (Ampere) with **ideal acceleration performance**, and it also runs correctly on **H200** (Hopper) but the acceleration is limited due to hardware scheduling differences and sparse kernel behavior. **Compatibility and performance on other GPUs (e.g., RTX 40/50 series or H800) are currently unknown**. For more details, please refer to the official documentation: https://github.com/mit-han-lab/Block-Sparse-Attention
```bash
# ✅ Recommended: clone and install in a separate clean folder (outside the FlashVSR repo)
git clone https://github.com/mit-han-lab/Block-Sparse-Attention
cd Block-Sparse-Attention
pip install packaging
pip install ninja
python setup.py install
```
#### 4️⃣ Download Model Weights from Hugging Face
FlashVSR provides both **v1** and **v1.1** model weights on Hugging Face (via **Git LFS**).
Please install Git LFS first:
```bash
# From the repo root
cd examples/WanVSR
# Install Git LFS (once per machine)
git lfs install
# Clone v1 (original) or v1.1 (recommended)
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR # v1
# or
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1 # v1.1
```
After cloning, you should have one of the following folders:
```
./examples/WanVSR/FlashVSR/ # v1
./examples/WanVSR/FlashVSR-v1.1/ # v1.1
│
├── LQ_proj_in.ckpt
├── TCDecoder.ckpt
├── Wan2.1_VAE.pth
├── diffusion_pytorch_model_streaming_dmd.safetensors
└── README.md
```
> Inference scripts automatically load weights from the corresponding folder.
---
#### 5️⃣ Run Inference
```bash
# From the repo root
cd examples/WanVSR
# v1 (original)
python infer_flashvsr_full.py
# or
python infer_flashvsr_tiny.py
# or
python infer_flashvsr_tiny_long_video.py
# v1.1 (recommended)
python infer_flashvsr_v1.1_full.py
# or
python infer_flashvsr_v1.1_tiny.py
# or
python infer_flashvsr_v1.1_tiny_long_video.py
```
---
### 🛠️ Method
The overview of **FlashVSR**. This framework features:
* **Three-Stage Distillation Pipeline** for streaming VSR training.
* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
 ---
### 🤗 Feedback & Support
We welcome feedback and issues. Thank you for trying **FlashVSR**!
---
### 📄 Acknowledgments
We gratefully acknowledge the following open-source projects:
* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
---
### 📞 Contact
* **Junhao Zhuang**
Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
---
### 📜 Citation
```bibtex
@article{zhuang2025flashvsr,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Zhuang, Junhao and Guo, Shi and Cai, Xin and Li, Xiaohui and Liu, Yihao and Yuan, Chun and Xue, Tianfan},
journal={arXiv preprint arXiv:2510.12747},
year={2025}
}
```
---
### 🤗 Feedback & Support
We welcome feedback and issues. Thank you for trying **FlashVSR**!
---
### 📄 Acknowledgments
We gratefully acknowledge the following open-source projects:
* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
---
### 📞 Contact
* **Junhao Zhuang**
Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
---
### 📜 Citation
```bibtex
@article{zhuang2025flashvsr,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Zhuang, Junhao and Guo, Shi and Cai, Xin and Li, Xiaohui and Liu, Yihao and Yuan, Chun and Xue, Tianfan},
journal={arXiv preprint arXiv:2510.12747},
year={2025}
}
```