---
license: apache-2.0
pipeline_tag: video-to-video
---
# ⚡ FlashVSR
**Towards Real-Time Diffusion-Based Streaming Video Super-Resolution**
**Authors:** Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, Tianfan Xue




 **Your star means a lot for us to develop this project!** :star:
**Your star means a lot for us to develop this project!** :star:
 ---
### 🌟 Abstract
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
---
### 📰 News
- **Release Date:** October 2025 — Inference code and model weights are available now! 🎉
- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
---
### 📋 TODO
- ✅ Release inference code and model weights
- ⬜ Release dataset (VSR-120K)
---
### 🚀 Getting Started
Follow these steps to set up and run **FlashVSR** on your local machine:
#### 1️⃣ Clone the Repository
```bash
git clone https://github.com/OpenImagingLab/FlashVSR
cd FlashVSR
````
#### 2️⃣ Set Up the Python Environment
Create and activate the environment (**Python 3.11.13**):
```bash
conda create -n flashvsr python=3.11.13
conda activate flashvsr
```
Install project dependencies:
```bash
pip install -e .
pip install -r requirements.txt
```
#### 3️⃣ Install Block-Sparse Attention (Required)
FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
```bash
git clone https://github.com/mit-han-lab/Block-Sparse-Attention
cd Block-Sparse-Attention
pip install packaging
pip install ninja
python setup.py install
```
**⚠️ Note:** The Block-Sparse Attention backend currently achieves ideal acceleration only on NVIDIA A100 or A800 GPUs (Ampere architecture). On H100/H800 (Hopper) GPUs, due to differences in hardware scheduling and sparse kernel behavior, the expected speedup may not be realized, and in some cases performance can even be slower than dense attention.
#### 4️⃣ Download Model Weights from Hugging Face
Weights are hosted on **Hugging Face** via **Git LFS**. Please install Git LFS first:
```bash
# From the repo root
cd examples/WanVSR
# Install Git LFS (once per machine)
git lfs install
# Clone the model repository into examples/WanVSR
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR
```
After cloning, you should have:
```
./examples/WanVSR/FlashVSR/
│
├── LQ_proj_in.ckpt
├── TCDecoder.ckpt
├── Wan2.1_VAE.pth
├── diffusion_pytorch_model_streaming_dmd.safetensors
└── README.md
```
> The inference scripts will load weights from `./examples/WanVSR/FlashVSR/` by default.
#### 5️⃣ Run Inference
```bash
# From the repo root
cd examples/WanVSR
python infer_flashvsr_full.py # Full model
# or
python infer_flashvsr_tiny.py # Tiny model
```
---
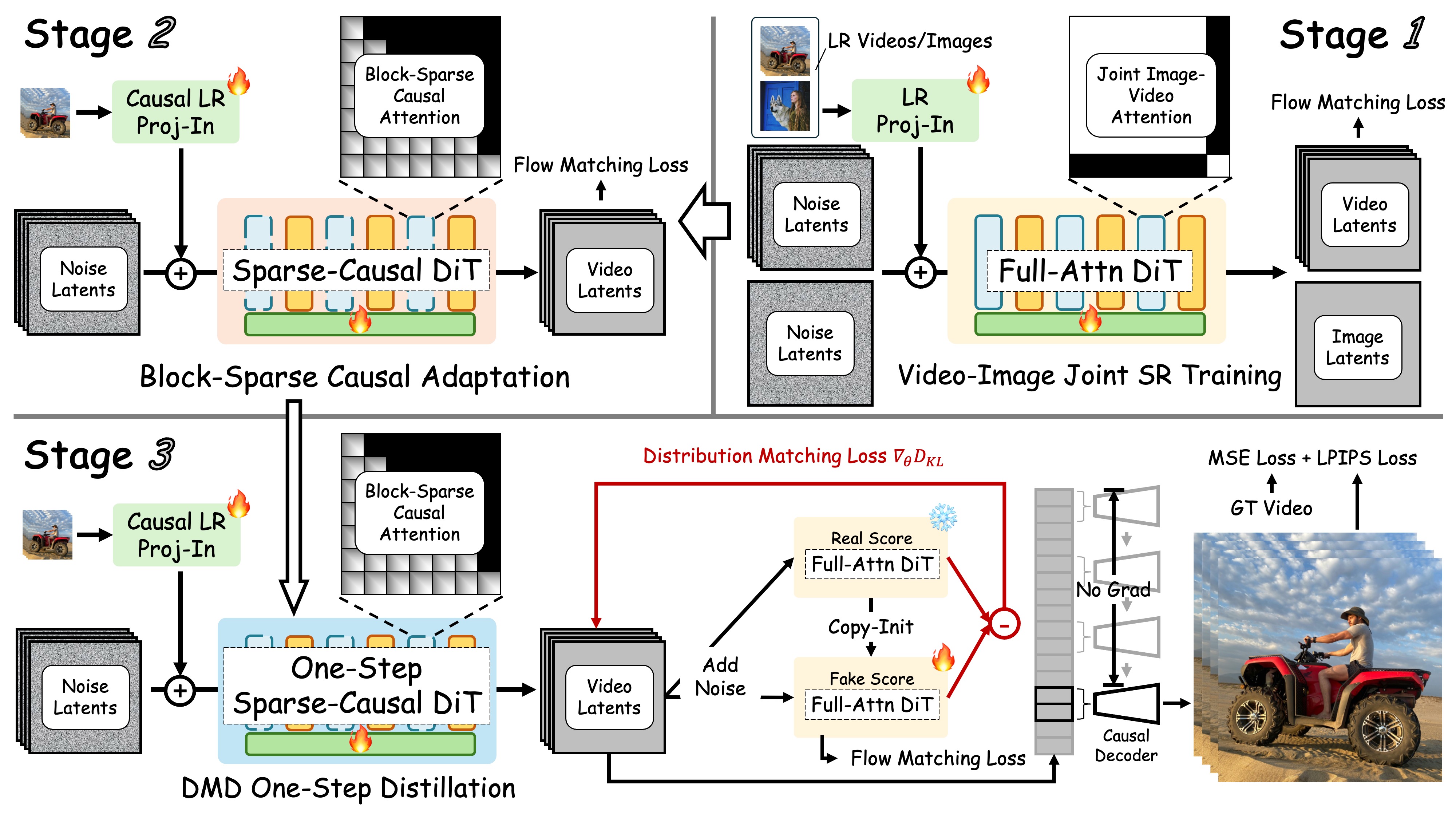
### 🛠️ Method
The overview of **FlashVSR**. This framework features:
* **Three-Stage Distillation Pipeline** for streaming VSR training.
* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
---
### 🌟 Abstract
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
---
### 📰 News
- **Release Date:** October 2025 — Inference code and model weights are available now! 🎉
- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
---
### 📋 TODO
- ✅ Release inference code and model weights
- ⬜ Release dataset (VSR-120K)
---
### 🚀 Getting Started
Follow these steps to set up and run **FlashVSR** on your local machine:
#### 1️⃣ Clone the Repository
```bash
git clone https://github.com/OpenImagingLab/FlashVSR
cd FlashVSR
````
#### 2️⃣ Set Up the Python Environment
Create and activate the environment (**Python 3.11.13**):
```bash
conda create -n flashvsr python=3.11.13
conda activate flashvsr
```
Install project dependencies:
```bash
pip install -e .
pip install -r requirements.txt
```
#### 3️⃣ Install Block-Sparse Attention (Required)
FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
```bash
git clone https://github.com/mit-han-lab/Block-Sparse-Attention
cd Block-Sparse-Attention
pip install packaging
pip install ninja
python setup.py install
```
**⚠️ Note:** The Block-Sparse Attention backend currently achieves ideal acceleration only on NVIDIA A100 or A800 GPUs (Ampere architecture). On H100/H800 (Hopper) GPUs, due to differences in hardware scheduling and sparse kernel behavior, the expected speedup may not be realized, and in some cases performance can even be slower than dense attention.
#### 4️⃣ Download Model Weights from Hugging Face
Weights are hosted on **Hugging Face** via **Git LFS**. Please install Git LFS first:
```bash
# From the repo root
cd examples/WanVSR
# Install Git LFS (once per machine)
git lfs install
# Clone the model repository into examples/WanVSR
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR
```
After cloning, you should have:
```
./examples/WanVSR/FlashVSR/
│
├── LQ_proj_in.ckpt
├── TCDecoder.ckpt
├── Wan2.1_VAE.pth
├── diffusion_pytorch_model_streaming_dmd.safetensors
└── README.md
```
> The inference scripts will load weights from `./examples/WanVSR/FlashVSR/` by default.
#### 5️⃣ Run Inference
```bash
# From the repo root
cd examples/WanVSR
python infer_flashvsr_full.py # Full model
# or
python infer_flashvsr_tiny.py # Tiny model
```
---
### 🛠️ Method
The overview of **FlashVSR**. This framework features:
* **Three-Stage Distillation Pipeline** for streaming VSR training.
* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
 ---
### 🤗 Feedback & Support
We welcome feedback and issues. Thank you for trying **FlashVSR**!
---
### 📄 Acknowledgments
We gratefully acknowledge the following open-source projects:
* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
---
### 📞 Contact
* **Junhao Zhuang**
Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
---
### 📜 Citation
```bibtex
@misc{zhuang2025flashvsrrealtimediffusionbasedstreaming,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Junhao Zhuang and Shi Guo and Xin Cai and Xiaohui Li and Yihao Liu and Chun Yuan and Tianfan Xue},
year={2025},
eprint={2510.12747},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.12747},
}
```
---
### 🤗 Feedback & Support
We welcome feedback and issues. Thank you for trying **FlashVSR**!
---
### 📄 Acknowledgments
We gratefully acknowledge the following open-source projects:
* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
---
### 📞 Contact
* **Junhao Zhuang**
Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
---
### 📜 Citation
```bibtex
@misc{zhuang2025flashvsrrealtimediffusionbasedstreaming,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Junhao Zhuang and Shi Guo and Xin Cai and Xiaohui Li and Yihao Liu and Chun Yuan and Tianfan Xue},
year={2025},
eprint={2510.12747},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.12747},
}
```