

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .ipynb_checkpoints/README-checkpoint.md +239 -0
- .mdl +0 -0
- .msc +0 -0
- .mv +1 -0
- LICENSE +57 -0
- README.md +239 -0
- added_tokens.json +32 -0
- chat_template.jinja +88 -0
- config.json +36 -0
- configuration.json +1 -0
- generation_config.json +12 -0
- merges.txt +0 -0
- model-00001-of-00005.safetensors +3 -0
- model-00002-of-00005.safetensors +3 -0
- model-00003-of-00005.safetensors +3 -0
- model-00004-of-00005.safetensors +3 -0
- model-00005-of-00005.safetensors +3 -0
- model.safetensors.index.json +0 -0
- tokenizer.json +3 -0
- tokenizer_config.json +272 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
.ipynb_checkpoints/README-checkpoint.md
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507/blob/main/LICENSE
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
tags:
|
| 6 |
+
- AWQ
|
| 7 |
+
- 量化修复
|
| 8 |
+
- vLLM
|
| 9 |
+
base_model:
|
| 10 |
+
- Kwaipilot/KAT-V1-40B
|
| 11 |
+
base_model_relation: quantized
|
| 12 |
+
---
|
| 13 |
+
# KAT-V1-40B-AWQ
|
| 14 |
+
Base model: [Kwaipilot/KAT-V1-40B](https://huggingface.co/Kwaipilot/KAT-V1-40B)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
### 【vLLM Single Node with 4 GPUs Startup Command】
|
| 18 |
+
```
|
| 19 |
+
CONTEXT_LENGTH=32768
|
| 20 |
+
|
| 21 |
+
vllm serve \
|
| 22 |
+
QuantTrio/KAT-V1-40B-AWQ \
|
| 23 |
+
--served-model-name KAT-V1-40B-AWQ \
|
| 24 |
+
--swap-space 16 \
|
| 25 |
+
--max-num-seqs 512 \
|
| 26 |
+
--max-model-len $CONTEXT_LENGTH \
|
| 27 |
+
--max-seq-len-to-capture $CONTEXT_LENGTH \
|
| 28 |
+
--gpu-memory-utilization 0.9 \
|
| 29 |
+
--tensor-parallel-size 4 \
|
| 30 |
+
--trust-remote-code \
|
| 31 |
+
--disable-log-requests \
|
| 32 |
+
--host 0.0.0.0 \
|
| 33 |
+
--port 8000
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
### 【Dependencies】
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
vllm==0.10.0
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
### 【Model Update Date】
|
| 43 |
+
```
|
| 44 |
+
2025-07-31
|
| 45 |
+
1. fast commit
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
### 【Model Files】
|
| 49 |
+
| File Size | Last Updated |
|
| 50 |
+
|--------|--------------|
|
| 51 |
+
| `22GB` | `2025-07-31` |
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### 【Model Download】
|
| 55 |
+
|
| 56 |
+
```python
|
| 57 |
+
from huggingface_hub import snapshot_download
|
| 58 |
+
snapshot_download('QuantTrio/KAT-V1-40B-AWQ', cache_dir="your_local_path")
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
### 【Overview】
|
| 62 |
+
<div align="center">
|
| 63 |
+
<img src="https://raw.githubusercontent.com/Anditty/OASIS/refs/heads/main/Group.svg" width="60%" alt="Kwaipilot" />
|
| 64 |
+
</div>
|
| 65 |
+
|
| 66 |
+
<hr>
|
| 67 |
+
|
| 68 |
+
<div align="center" style="line-height: 1;">
|
| 69 |
+
<a href="https://huggingface.co/Kwaipilot/KAT-V1-40B" target="_blank">
|
| 70 |
+
<img alt="Hugging Face" src="https://img.shields.io/badge/HuggingFace-fcd022?style=for-the-badge&logo=huggingface&logoColor=000&labelColor"/>
|
| 71 |
+
</a>
|
| 72 |
+
|
| 73 |
+
<a href="https://arxiv.org/pdf/2507.08297" target="_blank">
|
| 74 |
+
<img alt="arXiv" src="https://img.shields.io/badge/arXiv-2507.08297-b31b1b.svg?style=for-the-badge"/>
|
| 75 |
+
</a>
|
| 76 |
+
</div>
|
| 77 |
+
|
| 78 |
+
# News
|
| 79 |
+
|
| 80 |
+
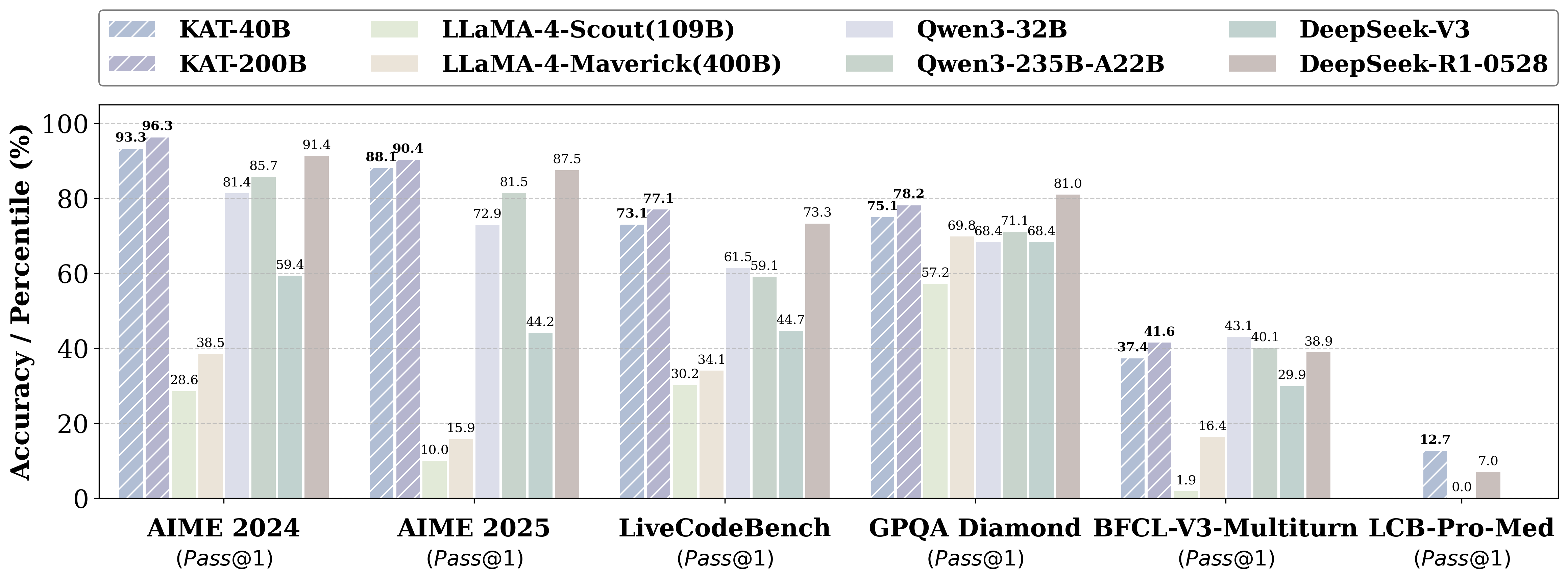
- Kwaipilot-AutoThink ranks first among all open-source models on [LiveCodeBench Pro](https://livecodebenchpro.com/), a challenging benchmark explicitly designed to prevent data leakage, and even surpasses strong proprietary systems such as Seed and o3-mini.
|
| 81 |
+
|
| 82 |
+
***
|
| 83 |
+
|
| 84 |
+
# Introduction
|
| 85 |
+
|
| 86 |
+
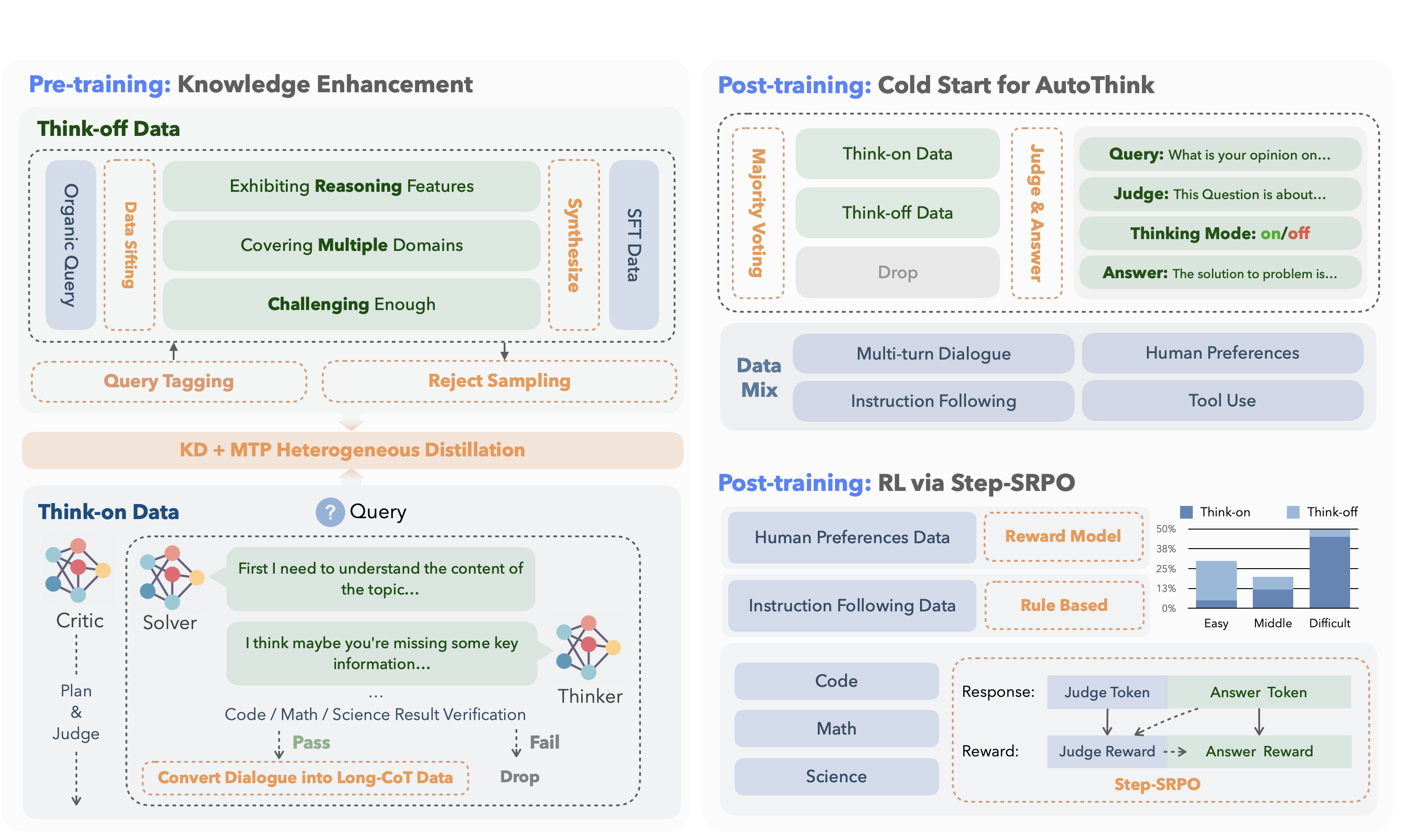
**KAT (Kwaipilot-AutoThink)** is an open-source large-language model that mitigates *over-thinking* by learning **when** to produce explicit chain-of-thought and **when** to answer directly.
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
Its development follows a concise two-stage training pipeline:
|
| 91 |
+
|
| 92 |
+
<table>
|
| 93 |
+
<thead>
|
| 94 |
+
<tr>
|
| 95 |
+
<th style="text-align:left; width:18%;">Stage</th>
|
| 96 |
+
<th style="text-align:left;">Core Idea</th>
|
| 97 |
+
<th style="text-align:left;">Key Techniques</th>
|
| 98 |
+
<th style="text-align:left;">Outcome</th>
|
| 99 |
+
</tr>
|
| 100 |
+
</thead>
|
| 101 |
+
<tbody>
|
| 102 |
+
<tr>
|
| 103 |
+
<td><strong>1. Pre-training</strong></td>
|
| 104 |
+
<td>Inject knowledge while separating “reasoning” from “direct answering”.</td>
|
| 105 |
+
<td>
|
| 106 |
+
<em>Dual-regime data</em><br>
|
| 107 |
+
• <strong>Think-off</strong> queries labeled via a custom tagging system.<br>
|
| 108 |
+
• <strong>Think-on</strong> queries generated by a multi-agent solver.<br><br>
|
| 109 |
+
<em>Knowledge Distillation + Multi-Token Prediction</em> for fine-grained utility.
|
| 110 |
+
</td>
|
| 111 |
+
<td>Base model attains strong factual and reasoning skills without full-scale pre-training costs.</td>
|
| 112 |
+
</tr>
|
| 113 |
+
<tr>
|
| 114 |
+
<td><strong>2. Post-training</strong></td>
|
| 115 |
+
<td>Make reasoning optional and efficient.</td>
|
| 116 |
+
<td>
|
| 117 |
+
<em>Cold-start AutoThink</em> — majority vote sets the initial thinking mode.<br>
|
| 118 |
+
<em>Step-SRPO</em> — intermediate supervision rewards correct <strong>mode selection</strong> and <strong>answer accuracy</strong> under that mode.
|
| 119 |
+
</td>
|
| 120 |
+
<td>Model triggers CoT only when beneficial, reducing token use and speeding inference.</td>
|
| 121 |
+
</tr>
|
| 122 |
+
</tbody>
|
| 123 |
+
</table>
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
***
|
| 129 |
+
|
| 130 |
+
# Data Format
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
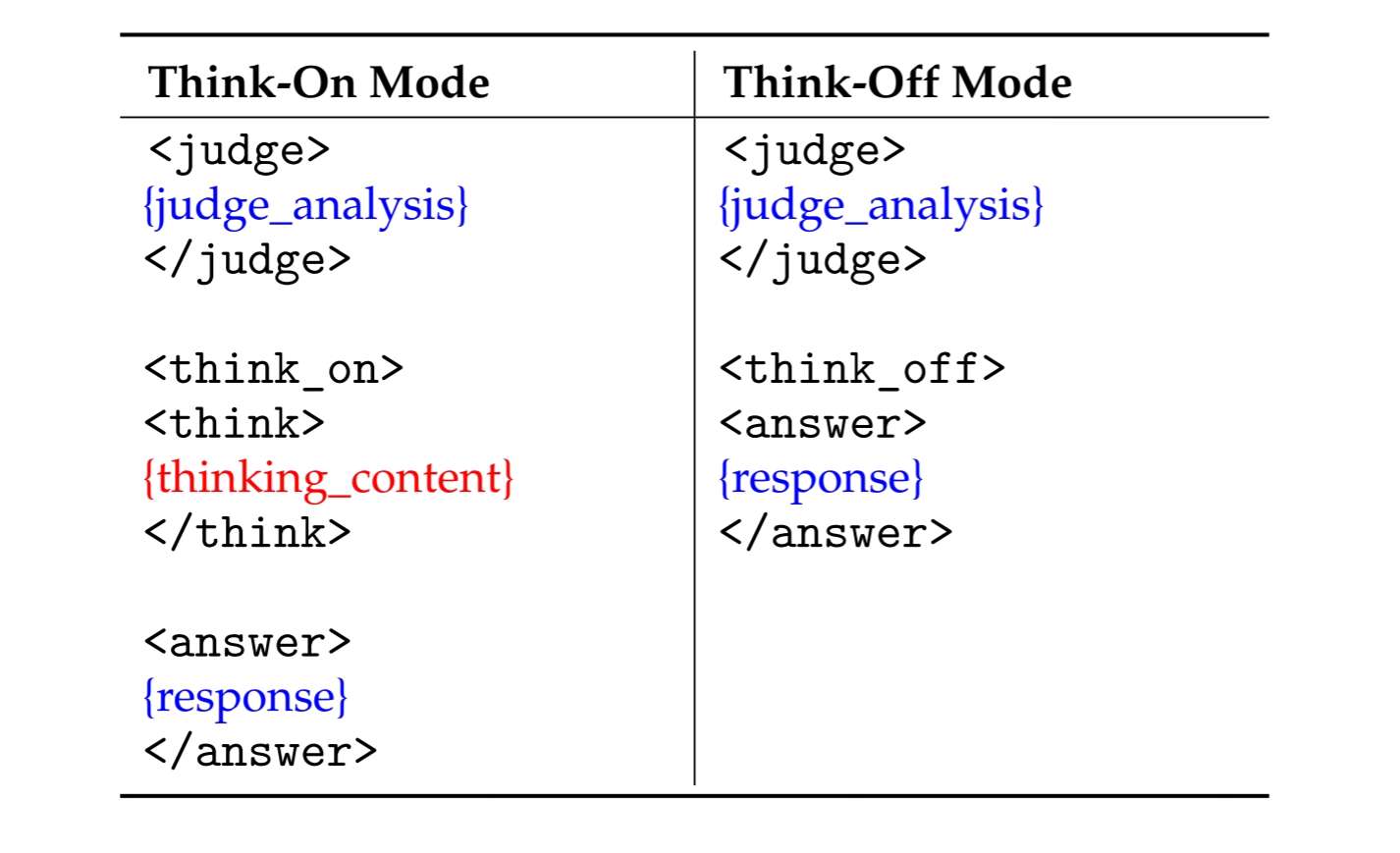
KAT produces responses in a **structured template** that makes the reasoning path explicit and machine-parsable.
|
| 134 |
+
Two modes are supported:
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## Special Tokens
|
| 141 |
+
|
| 142 |
+
| Token | Description |
|
| 143 |
+
|-------|-------------|
|
| 144 |
+
| `<judge>` | Analyzes the input to decide whether explicit reasoning is needed. |
|
| 145 |
+
| `<think_on>` / `<think_off>` | Indicates whether reasoning is **activated** (“on”) or **skipped** (“off”). |
|
| 146 |
+
| `<think>` | Marks the start of the chain-of-thought segment when `think_on` is chosen. |
|
| 147 |
+
| `<answer>` | Marks the start of the final user-facing answer. |
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
***
|
| 151 |
+
|
| 152 |
+
# 🔧 Quick Start
|
| 153 |
+
|
| 154 |
+
```python
|
| 155 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 156 |
+
|
| 157 |
+
model_name = "Kwaipilot/KAT-V1-40B"
|
| 158 |
+
|
| 159 |
+
# load the tokenizer and the model
|
| 160 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 161 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 162 |
+
model_name,
|
| 163 |
+
torch_dtype="auto",
|
| 164 |
+
device_map="auto"
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# prepare the model input
|
| 168 |
+
prompt = "Give me a short introduction to large language model."
|
| 169 |
+
messages = [
|
| 170 |
+
{"role": "user", "content": prompt}
|
| 171 |
+
]
|
| 172 |
+
text = tokenizer.apply_chat_template(
|
| 173 |
+
messages,
|
| 174 |
+
tokenize=False,
|
| 175 |
+
add_generation_prompt=True
|
| 176 |
+
)
|
| 177 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 178 |
+
|
| 179 |
+
# conduct text completion
|
| 180 |
+
generated_ids = model.generate(
|
| 181 |
+
**model_inputs,
|
| 182 |
+
max_new_tokens=65536,
|
| 183 |
+
temperature=0.6,
|
| 184 |
+
top_p=0.95,
|
| 185 |
+
)
|
| 186 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
| 187 |
+
content = tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
|
| 188 |
+
print("prompt:\n", prompt)
|
| 189 |
+
print("content:\n", content)
|
| 190 |
+
"""
|
| 191 |
+
prompt:
|
| 192 |
+
Give me a short introduction to large language model.
|
| 193 |
+
content:
|
| 194 |
+
<judge>
|
| 195 |
+
The user's request is to provide a concise factual introduction to large language models, which involves retrieving and summarizing basic information. This task is straightforward as it only requires recalling and presenting well-known details without deeper analysis. No complex reasoning is needed here—just a simple explanation will suffice.
|
| 196 |
+
</judge>
|
| 197 |
+
|
| 198 |
+
<think_off>
|
| 199 |
+
<answer>
|
| 200 |
+
A **Large Language Model (LLM)** is an advanced AI system trained on vast amounts of text data to understand, generate, and process human-like language. Here’s a concise introduction:
|
| 201 |
+
|
| 202 |
+
### Key Points:
|
| 203 |
+
1. **Training**: Trained on diverse text sources (books, websites, etc.) using deep learning.
|
| 204 |
+
2. **Capabilities**:
|
| 205 |
+
- Answer questions, generate text, summarize content, translate languages.
|
| 206 |
+
- Understand context, sentiment, and nuances in language.
|
| 207 |
+
3. **Architecture**: Often based on **transformer models** (e.g., BERT, GPT, LLaMA).
|
| 208 |
+
4. **Scale**: Billions of parameters, requiring massive computational resources.
|
| 209 |
+
5. **Applications**: Chatbots, content creation, coding assistance, research, and more.
|
| 210 |
+
|
| 211 |
+
### Examples:
|
| 212 |
+
- **OpenAI’s GPT-4**: Powers ChatGPT.
|
| 213 |
+
- **Google’s Gemini**: Used in Bard.
|
| 214 |
+
- **Meta’s LLaMA**: Open-source alternative.
|
| 215 |
+
|
| 216 |
+
### Challenges:
|
| 217 |
+
- **Bias**: Can reflect biases in training data.
|
| 218 |
+
- **Accuracy**: May hallucinate "facts" not grounded in reality.
|
| 219 |
+
- **Ethics**: Raises concerns about misinformation and job displacement.
|
| 220 |
+
|
| 221 |
+
LLMs represent a leap forward in natural language processing, enabling machines to interact with humans in increasingly sophisticated ways. 🌐🤖
|
| 222 |
+
</answer>
|
| 223 |
+
"""
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
***
|
| 227 |
+
|
| 228 |
+
# Future Releases
|
| 229 |
+
|
| 230 |
+
Looking ahead, we will publish a companion paper that fully documents the **AutoThink training framework**, covering:
|
| 231 |
+
|
| 232 |
+
* Cold-start initialization procedures
|
| 233 |
+
* Reinforcement-learning (Step-SRPO) strategies
|
| 234 |
+
* Data curation and reward design details
|
| 235 |
+
|
| 236 |
+
At the same time, we will open-source:
|
| 237 |
+
|
| 238 |
+
* **Training resources** – the curated dual-regime datasets and RL codebase
|
| 239 |
+
* **Model suite** – checkpoints at 1.5B, 7B, and 13B parameters, all trained with AutoThink gating
|
.mdl
ADDED
|
Binary file (44 Bytes). View file
|
|
|
.msc
ADDED
|
Binary file (1.29 kB). View file
|
|
|
.mv
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Revision:master,CreatedAt:1753930441
|
LICENSE
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL LICENSE AGREEMENT
|
| 2 |
+
By clicking to agree or by using, reproducing, modifying, distributing, performing or displaying any portion or element of the Model Works, You will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 3 |
+
1. DEFINITIONS.
|
| 4 |
+
a. “Agreement” shall mean the terms and conditions for use, reproduction, distribution, modification, performance and displaying of the Model Works or any portion or element thereof set forth herein.
|
| 5 |
+
b. “Materials” shall mean, collectively, Us proprietary the Model and Documentation (and any portion thereof) as made available by Us under this Agreement.
|
| 6 |
+
c. “Model” shall mean the large language models, image/video/audio/3D generation models, and multimodal large language models and their software and algorithms, including trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing made publicly available by Us .
|
| 7 |
+
d. “Output” shall mean the information and/or content output of Model or a Model Derivative that results from operating or otherwise using Model or a Model Derivative.
|
| 8 |
+
e. “Model Derivatives” shall mean all: (i) modifications to the Model or any Model Derivative; (ii) works based on the Model or any Model Derivative; or (iii) any other machine learning model which is created by transfer of patterns of the weights, parameters, operations, or Output of the Model or any Model Derivative, to that model in order to cause that model to perform similarly to the Model or a Model Derivative, including distillation methods, methods that use intermediate data representations, or methods based on the generation of synthetic data Outputs or a Model Derivative for training that model. For clarity, Outputs by themselves are not deemed Model Derivatives.
|
| 9 |
+
f. “Model Works” shall mean: (i) the Materials; (ii) Model Derivatives; and (iii) all derivative works thereof.
|
| 10 |
+
g. “Licensor” , “We” or “Us” shall mean the copyright owner or entity authorized by the copyright owner that is granting the License, including the persons or entities that may have rights in the Model and/or distributing the Model.
|
| 11 |
+
h. “Licensee”, “You” or “Your” shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Model Works for any purpose and in any field of use.
|
| 12 |
+
i. “Third Party” or “Third Parties” shall mean individuals or legal entities that are not under common control with Us or You.
|
| 13 |
+
|
| 14 |
+
2. LICENSE CONTENT.
|
| 15 |
+
a. We grant You a non-exclusive, worldwide, non-transferable and royalty-free limited license under the intellectual property or other rights owned by Us embodied in or utilized by the Materials to use, reproduce, distribute, create derivative works of (including Model Derivatives), and make modifications to the Materials, only in accordance with the terms of this Agreement and the Acceptable Use Policy, and You must not violate (or encourage or permit anyone else to violate) any term of this Agreement or the Acceptable Use Policy.
|
| 16 |
+
b. You may, subject to Your compliance with this Agreement, distribute or make available to Third Parties the Model Works, provided that You meet all of the following conditions:
|
| 17 |
+
(i) You must provide all such Third Party recipients of the Model Works or products or services using them the source of the Model and a copy of this Agreement;
|
| 18 |
+
(ii) You must cause any modified documents to carry prominent notices stating that You changed the documents;
|
| 19 |
+
(iii) You may add Your own copyright statement to Your modifications and, may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Model Derivatives as a whole, provided Your use, reproduction, modification, distribution, performance and display of the work otherwise complies with the terms and conditions of this Agreement.
|
| 20 |
+
|
| 21 |
+
3. LICENSE RESTRICITIONS.
|
| 22 |
+
a. Your use of the Model Works must comply with applicable laws and regulations (including trade compliance laws and regulations) and the restrictions set forth in Attachment A . You must include the use restrictions referenced in these Sections 3(a) and 3(b) as an enforceable provision in any agreement (e.g., license agreement, terms of use, etc.) governing the use and/or distribution of Model Works and You must provide notice to subsequent users to whom You distribute that Model Works are subject to the use restrictions in these Sections 3(a) and 3(b).
|
| 23 |
+
b. You must not use the Model Works or any Output or results of the Model Works to improve any other large model (other than Model or Model Derivatives thereof).
|
| 24 |
+
4. INTELLECTUAL PROPERTY.
|
| 25 |
+
a. We retain ownership of all intellectual property rights in and to the Model and derivatives. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by You, You are and will be the owner of such derivative works and modifications.
|
| 26 |
+
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of Us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
| 27 |
+
c. If You commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any person or entity alleging that the Materials or any Output, or any portion of any of the foregoing, infringe any intellectual property or other right owned or licensable by You, then all licenses granted to You under this Agreement shall terminate as of the date such lawsuit or other proceeding is filed.
|
| 28 |
+
5. DISCLAIMERS OF WARRANTY AND LIMITATIONS OF LIABILITY.
|
| 29 |
+
a. THE MODEL WORKS AND ANY OUTPUT AND RESULTS THERE FROM ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
| 30 |
+
b. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
| 31 |
+
c. You will defend, indemnify and hold harmless Us from and against any claim by any third party arising out of or related to Your use or distribution of the Materials.
|
| 32 |
+
|
| 33 |
+
6. SURVIVAL AND TERMINATION.
|
| 34 |
+
a. The term of this Agreement shall commence upon Your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 35 |
+
b. We may terminate this Agreement if You breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, You must promptly delete and cease use of the Model Works. Sections 4(a), 4(c), 5 and 7 shall survive the termination of this Agreement.
|
| 36 |
+
7. GOVERNING LAW AND JURISDICTION.
|
| 37 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China (for the purpose of this agreement only, excluding Hong Kong, Macau, and Taiwan), without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 38 |
+
b. Any disputes arising from or related to this Agreement shall be under the jurisdiction of the People's Court where the Licensor is located.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
Attachment A
|
| 42 |
+
|
| 43 |
+
Use Restrictions
|
| 44 |
+
|
| 45 |
+
You agree not to use the Model or Derivatives of the Model:
|
| 46 |
+
|
| 47 |
+
- In any way that violates any applicable national or international law or regulation or infringes upon the lawful rights and interests of any third party;
|
| 48 |
+
- For military use in any way;
|
| 49 |
+
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 50 |
+
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
|
| 51 |
+
- To generate or disseminate inappropriate content subject to applicable regulatory requirements;
|
| 52 |
+
- To generate or disseminate personal identifiable information without due authorization or for unreasonable use;
|
| 53 |
+
- To defame, disparage or otherwise harass others;
|
| 54 |
+
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
|
| 55 |
+
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
|
| 56 |
+
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 57 |
+
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories.
|
README.md
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507/blob/main/LICENSE
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
tags:
|
| 6 |
+
- AWQ
|
| 7 |
+
- 量化修复
|
| 8 |
+
- vLLM
|
| 9 |
+
base_model:
|
| 10 |
+
- Kwaipilot/KAT-V1-40B
|
| 11 |
+
base_model_relation: quantized
|
| 12 |
+
---
|
| 13 |
+
# KAT-V1-40B-AWQ
|
| 14 |
+
Base model: [Kwaipilot/KAT-V1-40B](https://huggingface.co/Kwaipilot/KAT-V1-40B)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
### 【vLLM Single Node with 4 GPUs Startup Command】
|
| 18 |
+
```
|
| 19 |
+
CONTEXT_LENGTH=32768
|
| 20 |
+
|
| 21 |
+
vllm serve \
|
| 22 |
+
QuantTrio/KAT-V1-40B-AWQ \
|
| 23 |
+
--served-model-name KAT-V1-40B-AWQ \
|
| 24 |
+
--swap-space 16 \
|
| 25 |
+
--max-num-seqs 512 \
|
| 26 |
+
--max-model-len $CONTEXT_LENGTH \
|
| 27 |
+
--max-seq-len-to-capture $CONTEXT_LENGTH \
|
| 28 |
+
--gpu-memory-utilization 0.9 \
|
| 29 |
+
--tensor-parallel-size 4 \
|
| 30 |
+
--trust-remote-code \
|
| 31 |
+
--disable-log-requests \
|
| 32 |
+
--host 0.0.0.0 \
|
| 33 |
+
--port 8000
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
### 【Dependencies】
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
vllm==0.10.0
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
### 【Model Update Date】
|
| 43 |
+
```
|
| 44 |
+
2025-07-31
|
| 45 |
+
1. fast commit
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
### 【Model Files】
|
| 49 |
+
| File Size | Last Updated |
|
| 50 |
+
|--------|--------------|
|
| 51 |
+
| `22GB` | `2025-07-31` |
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### 【Model Download】
|
| 55 |
+
|
| 56 |
+
```python
|
| 57 |
+
from huggingface_hub import snapshot_download
|
| 58 |
+
snapshot_download('QuantTrio/KAT-V1-40B-AWQ', cache_dir="your_local_path")
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
### 【Overview】
|
| 62 |
+
<div align="center">
|
| 63 |
+
<img src="https://raw.githubusercontent.com/Anditty/OASIS/refs/heads/main/Group.svg" width="60%" alt="Kwaipilot" />
|
| 64 |
+
</div>
|
| 65 |
+
|
| 66 |
+
<hr>
|
| 67 |
+
|
| 68 |
+
<div align="center" style="line-height: 1;">
|
| 69 |
+
<a href="https://huggingface.co/Kwaipilot/KAT-V1-40B" target="_blank">
|
| 70 |
+
<img alt="Hugging Face" src="https://img.shields.io/badge/HuggingFace-fcd022?style=for-the-badge&logo=huggingface&logoColor=000&labelColor"/>
|
| 71 |
+
</a>
|
| 72 |
+
|
| 73 |
+
<a href="https://arxiv.org/pdf/2507.08297" target="_blank">
|
| 74 |
+
<img alt="arXiv" src="https://img.shields.io/badge/arXiv-2507.08297-b31b1b.svg?style=for-the-badge"/>
|
| 75 |
+
</a>
|
| 76 |
+
</div>
|
| 77 |
+
|
| 78 |
+
# News
|
| 79 |
+
|
| 80 |
+
- Kwaipilot-AutoThink ranks first among all open-source models on [LiveCodeBench Pro](https://livecodebenchpro.com/), a challenging benchmark explicitly designed to prevent data leakage, and even surpasses strong proprietary systems such as Seed and o3-mini.
|
| 81 |
+
|
| 82 |
+
***
|
| 83 |
+
|
| 84 |
+
# Introduction
|
| 85 |
+
|
| 86 |
+
**KAT (Kwaipilot-AutoThink)** is an open-source large-language model that mitigates *over-thinking* by learning **when** to produce explicit chain-of-thought and **when** to answer directly.
|
| 87 |
+
|
| 88 |
+

|
| 89 |
+
|
| 90 |
+
Its development follows a concise two-stage training pipeline:
|
| 91 |
+
|
| 92 |
+
<table>
|
| 93 |
+
<thead>
|
| 94 |
+
<tr>
|
| 95 |
+
<th style="text-align:left; width:18%;">Stage</th>
|
| 96 |
+
<th style="text-align:left;">Core Idea</th>
|
| 97 |
+
<th style="text-align:left;">Key Techniques</th>
|
| 98 |
+
<th style="text-align:left;">Outcome</th>
|
| 99 |
+
</tr>
|
| 100 |
+
</thead>
|
| 101 |
+
<tbody>
|
| 102 |
+
<tr>
|
| 103 |
+
<td><strong>1. Pre-training</strong></td>
|
| 104 |
+
<td>Inject knowledge while separating “reasoning” from “direct answering”.</td>
|
| 105 |
+
<td>
|
| 106 |
+
<em>Dual-regime data</em><br>
|
| 107 |
+
• <strong>Think-off</strong> queries labeled via a custom tagging system.<br>
|
| 108 |
+
• <strong>Think-on</strong> queries generated by a multi-agent solver.<br><br>
|
| 109 |
+
<em>Knowledge Distillation + Multi-Token Prediction</em> for fine-grained utility.
|
| 110 |
+
</td>
|
| 111 |
+
<td>Base model attains strong factual and reasoning skills without full-scale pre-training costs.</td>
|
| 112 |
+
</tr>
|
| 113 |
+
<tr>
|
| 114 |
+
<td><strong>2. Post-training</strong></td>
|
| 115 |
+
<td>Make reasoning optional and efficient.</td>
|
| 116 |
+
<td>
|
| 117 |
+
<em>Cold-start AutoThink</em> — majority vote sets the initial thinking mode.<br>
|
| 118 |
+
<em>Step-SRPO</em> — intermediate supervision rewards correct <strong>mode selection</strong> and <strong>answer accuracy</strong> under that mode.
|
| 119 |
+
</td>
|
| 120 |
+
<td>Model triggers CoT only when beneficial, reducing token use and speeding inference.</td>
|
| 121 |
+
</tr>
|
| 122 |
+
</tbody>
|
| 123 |
+
</table>
|
| 124 |
+
|
| 125 |
+

|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
***
|
| 129 |
+
|
| 130 |
+
# Data Format
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
KAT produces responses in a **structured template** that makes the reasoning path explicit and machine-parsable.
|
| 134 |
+
Two modes are supported:
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## Special Tokens
|
| 141 |
+
|
| 142 |
+
| Token | Description |
|
| 143 |
+
|-------|-------------|
|
| 144 |
+
| `<judge>` | Analyzes the input to decide whether explicit reasoning is needed. |
|
| 145 |
+
| `<think_on>` / `<think_off>` | Indicates whether reasoning is **activated** (“on”) or **skipped** (“off”). |
|
| 146 |
+
| `<think>` | Marks the start of the chain-of-thought segment when `think_on` is chosen. |
|
| 147 |
+
| `<answer>` | Marks the start of the final user-facing answer. |
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
***
|
| 151 |
+
|
| 152 |
+
# 🔧 Quick Start
|
| 153 |
+
|
| 154 |
+
```python
|
| 155 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 156 |
+
|
| 157 |
+
model_name = "Kwaipilot/KAT-V1-40B"
|
| 158 |
+
|
| 159 |
+
# load the tokenizer and the model
|
| 160 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 161 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 162 |
+
model_name,
|
| 163 |
+
torch_dtype="auto",
|
| 164 |
+
device_map="auto"
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# prepare the model input
|
| 168 |
+
prompt = "Give me a short introduction to large language model."
|
| 169 |
+
messages = [
|
| 170 |
+
{"role": "user", "content": prompt}
|
| 171 |
+
]
|
| 172 |
+
text = tokenizer.apply_chat_template(
|
| 173 |
+
messages,
|
| 174 |
+
tokenize=False,
|
| 175 |
+
add_generation_prompt=True
|
| 176 |
+
)
|
| 177 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 178 |
+
|
| 179 |
+
# conduct text completion
|
| 180 |
+
generated_ids = model.generate(
|
| 181 |
+
**model_inputs,
|
| 182 |
+
max_new_tokens=65536,
|
| 183 |
+
temperature=0.6,
|
| 184 |
+
top_p=0.95,
|
| 185 |
+
)
|
| 186 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
| 187 |
+
content = tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
|
| 188 |
+
print("prompt:\n", prompt)
|
| 189 |
+
print("content:\n", content)
|
| 190 |
+
"""
|
| 191 |
+
prompt:
|
| 192 |
+
Give me a short introduction to large language model.
|
| 193 |
+
content:
|
| 194 |
+
<judge>
|
| 195 |
+
The user's request is to provide a concise factual introduction to large language models, which involves retrieving and summarizing basic information. This task is straightforward as it only requires recalling and presenting well-known details without deeper analysis. No complex reasoning is needed here—just a simple explanation will suffice.
|
| 196 |
+
</judge>
|
| 197 |
+
|
| 198 |
+
<think_off>
|
| 199 |
+
<answer>
|
| 200 |
+
A **Large Language Model (LLM)** is an advanced AI system trained on vast amounts of text data to understand, generate, and process human-like language. Here’s a concise introduction:
|
| 201 |
+
|
| 202 |
+
### Key Points:
|
| 203 |
+
1. **Training**: Trained on diverse text sources (books, websites, etc.) using deep learning.
|
| 204 |
+
2. **Capabilities**:
|
| 205 |
+
- Answer questions, generate text, summarize content, translate languages.
|
| 206 |
+
- Understand context, sentiment, and nuances in language.
|
| 207 |
+
3. **Architecture**: Often based on **transformer models** (e.g., BERT, GPT, LLaMA).
|
| 208 |
+
4. **Scale**: Billions of parameters, requiring massive computational resources.
|
| 209 |
+
5. **Applications**: Chatbots, content creation, coding assistance, research, and more.
|
| 210 |
+
|
| 211 |
+
### Examples:
|
| 212 |
+
- **OpenAI’s GPT-4**: Powers ChatGPT.
|
| 213 |
+
- **Google’s Gemini**: Used in Bard.
|
| 214 |
+
- **Meta’s LLaMA**: Open-source alternative.
|
| 215 |
+
|
| 216 |
+
### Challenges:
|
| 217 |
+
- **Bias**: Can reflect biases in training data.
|
| 218 |
+
- **Accuracy**: May hallucinate "facts" not grounded in reality.
|
| 219 |
+
- **Ethics**: Raises concerns about misinformation and job displacement.
|
| 220 |
+
|
| 221 |
+
LLMs represent a leap forward in natural language processing, enabling machines to interact with humans in increasingly sophisticated ways. 🌐🤖
|
| 222 |
+
</answer>
|
| 223 |
+
"""
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
***
|
| 227 |
+
|
| 228 |
+
# Future Releases
|
| 229 |
+
|
| 230 |
+
Looking ahead, we will publish a companion paper that fully documents the **AutoThink training framework**, covering:
|
| 231 |
+
|
| 232 |
+
* Cold-start initialization procedures
|
| 233 |
+
* Reinforcement-learning (Step-SRPO) strategies
|
| 234 |
+
* Data curation and reward design details
|
| 235 |
+
|
| 236 |
+
At the same time, we will open-source:
|
| 237 |
+
|
| 238 |
+
* **Training resources** – the curated dual-regime datasets and RL codebase
|
| 239 |
+
* **Model suite** – checkpoints at 1.5B, 7B, and 13B parameters, all trained with AutoThink gating
|
added_tokens.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</answer>": 151670,
|
| 3 |
+
"</judge>": 151668,
|
| 4 |
+
"</think>": 151666,
|
| 5 |
+
"</tool_call>": 151658,
|
| 6 |
+
"<answer>": 151669,
|
| 7 |
+
"<judge>": 151667,
|
| 8 |
+
"<think>": 151665,
|
| 9 |
+
"<think_off>": 151672,
|
| 10 |
+
"<think_on>": 151671,
|
| 11 |
+
"<tool_call>": 151657,
|
| 12 |
+
"<|box_end|>": 151649,
|
| 13 |
+
"<|box_start|>": 151648,
|
| 14 |
+
"<|endoftext|>": 151643,
|
| 15 |
+
"<|file_sep|>": 151664,
|
| 16 |
+
"<|fim_middle|>": 151660,
|
| 17 |
+
"<|fim_pad|>": 151662,
|
| 18 |
+
"<|fim_prefix|>": 151659,
|
| 19 |
+
"<|fim_suffix|>": 151661,
|
| 20 |
+
"<|im_end|>": 151645,
|
| 21 |
+
"<|im_start|>": 151644,
|
| 22 |
+
"<|image_pad|>": 151655,
|
| 23 |
+
"<|object_ref_end|>": 151647,
|
| 24 |
+
"<|object_ref_start|>": 151646,
|
| 25 |
+
"<|quad_end|>": 151651,
|
| 26 |
+
"<|quad_start|>": 151650,
|
| 27 |
+
"<|repo_name|>": 151663,
|
| 28 |
+
"<|video_pad|>": 151656,
|
| 29 |
+
"<|vision_end|>": 151653,
|
| 30 |
+
"<|vision_pad|>": 151654,
|
| 31 |
+
"<|vision_start|>": 151652
|
| 32 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- if tools %}
|
| 2 |
+
{{- '<|im_start|>system\n' }}
|
| 3 |
+
{%- if messages[0]['role'] == 'system' %}
|
| 4 |
+
{{- messages[0]['content'] }}
|
| 5 |
+
{%- else %}
|
| 6 |
+
{{- '' }}
|
| 7 |
+
{%- endif %}
|
| 8 |
+
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
|
| 9 |
+
{%- for tool in tools %}
|
| 10 |
+
{{- "\n" }}
|
| 11 |
+
{{- tool | tojson }}
|
| 12 |
+
{%- endfor %}
|
| 13 |
+
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
|
| 14 |
+
{%- else %}
|
| 15 |
+
{%- if messages[0]['role'] == 'system' %}
|
| 16 |
+
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
|
| 17 |
+
{%- else %}
|
| 18 |
+
{{- '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}
|
| 19 |
+
{%- endif %}
|
| 20 |
+
{%- endif %}
|
| 21 |
+
{%- for message in messages %}
|
| 22 |
+
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
|
| 23 |
+
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
|
| 24 |
+
{%- elif message.role == "assistant" and not message.tool_calls %}
|
| 25 |
+
{%- set content = message.content %}
|
| 26 |
+
{%- if not loop.last %}
|
| 27 |
+
{%- set answer_blocks = message.content.split('<answer>\n') %}
|
| 28 |
+
{%- if answer_blocks|length > 1 %}
|
| 29 |
+
{%- set last_answer_block = answer_blocks[-1] %}
|
| 30 |
+
{%- if '\n</answer>' in last_answer_block %}
|
| 31 |
+
{%- set content = last_answer_block.split('\n</answer>')[0] %}
|
| 32 |
+
{%- else %}
|
| 33 |
+
{%- set content = message.content.split('<think_off>')[-1].lstrip('\n') %}
|
| 34 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 35 |
+
{%- endif %}
|
| 36 |
+
{%- else %}
|
| 37 |
+
{%- set content = message.content.split('<think_off>')[-1].lstrip('\n') %}
|
| 38 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 39 |
+
{%- endif %}
|
| 40 |
+
{%- endif %}
|
| 41 |
+
{{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }}
|
| 42 |
+
{%- elif message.role == "assistant" %}
|
| 43 |
+
{%- set content = message.content %}
|
| 44 |
+
{%- if not loop.last %}
|
| 45 |
+
{%- set answer_blocks = message.content.split('<answer>\n') %}
|
| 46 |
+
{%- if answer_blocks|length > 1 %}
|
| 47 |
+
{%- set last_answer_block = answer_blocks[-1] %}
|
| 48 |
+
{%- if '\n</answer>' in last_answer_block %}
|
| 49 |
+
{%- set content = last_answer_block.split('\n</answer>')[0] %}
|
| 50 |
+
{%- else %}
|
| 51 |
+
{%- set content = message.content.split('<think_off>')[-1].lstrip('\n') %}
|
| 52 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 53 |
+
{%- endif %}
|
| 54 |
+
{%- else %}
|
| 55 |
+
{%- set content = message.content.split('<think_off>')[-1].lstrip('\n') %}
|
| 56 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 57 |
+
{%- endif %}
|
| 58 |
+
{%- endif %}
|
| 59 |
+
{{- '<|im_start|>' + message.role }}
|
| 60 |
+
{%- if message.content %}
|
| 61 |
+
{{- '\n' + content }}
|
| 62 |
+
{%- endif %}
|
| 63 |
+
{%- for tool_call in message.tool_calls %}
|
| 64 |
+
{%- if tool_call.function is defined %}
|
| 65 |
+
{%- set tool_call = tool_call.function %}
|
| 66 |
+
{%- endif %}
|
| 67 |
+
{{- '\n<tool_call>\n{\"name\": \"' }}
|
| 68 |
+
{{- tool_call.name }}
|
| 69 |
+
{{- '\", \"arguments\": ' }}
|
| 70 |
+
{{- tool_call.arguments | tojson }}
|
| 71 |
+
{{- '}\n</tool_call>' }}
|
| 72 |
+
{%- endfor %}
|
| 73 |
+
{{- '<|im_end|>\n' }}
|
| 74 |
+
{%- elif message.role == "tool" %}
|
| 75 |
+
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
|
| 76 |
+
{{- '<|im_start|>user' }}
|
| 77 |
+
{%- endif %}
|
| 78 |
+
{{- '\n<tool_response>\n' }}
|
| 79 |
+
{{- message.content }}
|
| 80 |
+
{{- '\n</tool_response>' }}
|
| 81 |
+
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
|
| 82 |
+
{{- '<|im_end|>\n' }}
|
| 83 |
+
{%- endif %}
|
| 84 |
+
{%- endif %}
|
| 85 |
+
{%- endfor %}
|
| 86 |
+
{%- if add_generation_prompt %}
|
| 87 |
+
{{- '<|im_start|>assistant\n' }}
|
| 88 |
+
{%- endif %}
|
config.json
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name_or_path": "tclf90/KAT-V1-40B-AWQ",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151643,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 5120,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 27648,
|
| 13 |
+
"max_position_embeddings": 131072,
|
| 14 |
+
"max_window_layers": 64,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 40,
|
| 17 |
+
"num_hidden_layers": 80,
|
| 18 |
+
"num_key_value_heads": 8,
|
| 19 |
+
"rms_norm_eps": 1e-05,
|
| 20 |
+
"rope_scaling": null,
|
| 21 |
+
"rope_theta": 1000000.0,
|
| 22 |
+
"sliding_window": null,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"torch_dtype": "float16",
|
| 25 |
+
"transformers_version": "4.46.1",
|
| 26 |
+
"use_cache": false,
|
| 27 |
+
"use_sliding_window": false,
|
| 28 |
+
"vocab_size": 152064,
|
| 29 |
+
"quantization_config": {
|
| 30 |
+
"quant_method": "awq",
|
| 31 |
+
"bits": 4,
|
| 32 |
+
"group_size": 128,
|
| 33 |
+
"version": "gemm",
|
| 34 |
+
"zero_point": true
|
| 35 |
+
}
|
| 36 |
+
}
|
configuration.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
generation_config.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"temperature": 0.6,
|
| 10 |
+
"top_p": 0.95,
|
| 11 |
+
"transformers_version": "4.52.4"
|
| 12 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a6500e55b56e36acc90315085adc30730239cdb5e27a2de72609277a95fe45db
|
| 3 |
+
size 4990397496
|
model-00002-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a7a845aa11eac7af3e7a4fb16c8328391cbfe85077204226e3d8bd826ade4ebf
|
| 3 |
+
size 4961829824
|
model-00003-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fba14531e970182a81c8ebf112c4398a7ca01113efa67a29ea4cb744fa5555bb
|
| 3 |
+
size 4972882976
|
model-00004-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:99c6782a7362d334ed2bbd85bb84c9bc1ad8a1d06444c903b63bde48817fd5b8
|
| 3 |
+
size 4998781176
|
model-00005-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2ebc129a0537e6f3e0786717708b91d5aed8de214395ef8de8b73fc3f86e40f2
|
| 3 |
+
size 3458780720
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:528d9f2690ed3679eee70ed9b085fb78899b7f6dfc2a220220cfe89fdd3ffef5
|
| 3 |
+
size 11423388
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<think>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": false
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</think>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": false
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<judge>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": false
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "</judge>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": false
|
| 212 |
+
},
|
| 213 |
+
"151669": {
|
| 214 |
+
"content": "<answer>",
|
| 215 |
+
"lstrip": false,
|
| 216 |
+
"normalized": false,
|
| 217 |
+
"rstrip": false,
|
| 218 |
+
"single_word": false,
|
| 219 |
+
"special": false
|
| 220 |
+
},
|
| 221 |
+
"151670": {
|
| 222 |
+
"content": "</answer>",
|
| 223 |
+
"lstrip": false,
|
| 224 |
+
"normalized": false,
|
| 225 |
+
"rstrip": false,
|
| 226 |
+
"single_word": false,
|
| 227 |
+
"special": false
|
| 228 |
+
},
|
| 229 |
+
"151671": {
|
| 230 |
+
"content": "<think_on>",
|
| 231 |
+
"lstrip": false,
|
| 232 |
+
"normalized": false,
|
| 233 |
+
"rstrip": false,
|
| 234 |
+
"single_word": false,
|
| 235 |
+
"special": false
|
| 236 |
+
},
|
| 237 |
+
"151672": {
|
| 238 |
+
"content": "<think_off>",
|
| 239 |
+
"lstrip": false,
|
| 240 |
+
"normalized": false,
|
| 241 |
+
"rstrip": false,
|
| 242 |
+
"single_word": false,
|
| 243 |
+
"special": false
|
| 244 |
+
}
|
| 245 |
+
},
|
| 246 |
+
"additional_special_tokens": [
|
| 247 |
+
"<|im_start|>",
|
| 248 |
+
"<|im_end|>",
|
| 249 |
+
"<|object_ref_start|>",
|
| 250 |
+
"<|object_ref_end|>",
|
| 251 |
+
"<|box_start|>",
|
| 252 |
+
"<|box_end|>",
|
| 253 |
+
"<|quad_start|>",
|
| 254 |
+
"<|quad_end|>",
|
| 255 |
+
"<|vision_start|>",
|
| 256 |
+
"<|vision_end|>",
|
| 257 |
+
"<|vision_pad|>",
|
| 258 |
+
"<|image_pad|>",
|
| 259 |
+
"<|video_pad|>"
|
| 260 |
+
],
|
| 261 |
+
"bos_token": null,
|
| 262 |
+
"clean_up_tokenization_spaces": false,
|
| 263 |
+
"eos_token": "<|im_end|>",
|
| 264 |
+
"errors": "replace",
|
| 265 |
+
"extra_special_tokens": {},
|
| 266 |
+
"model_max_length": 131072,
|
| 267 |
+
"pad_token": "<|endoftext|>",
|
| 268 |
+
"padding_side": "right",
|
| 269 |
+
"split_special_tokens": false,
|
| 270 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 271 |
+
"unk_token": null
|
| 272 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|