
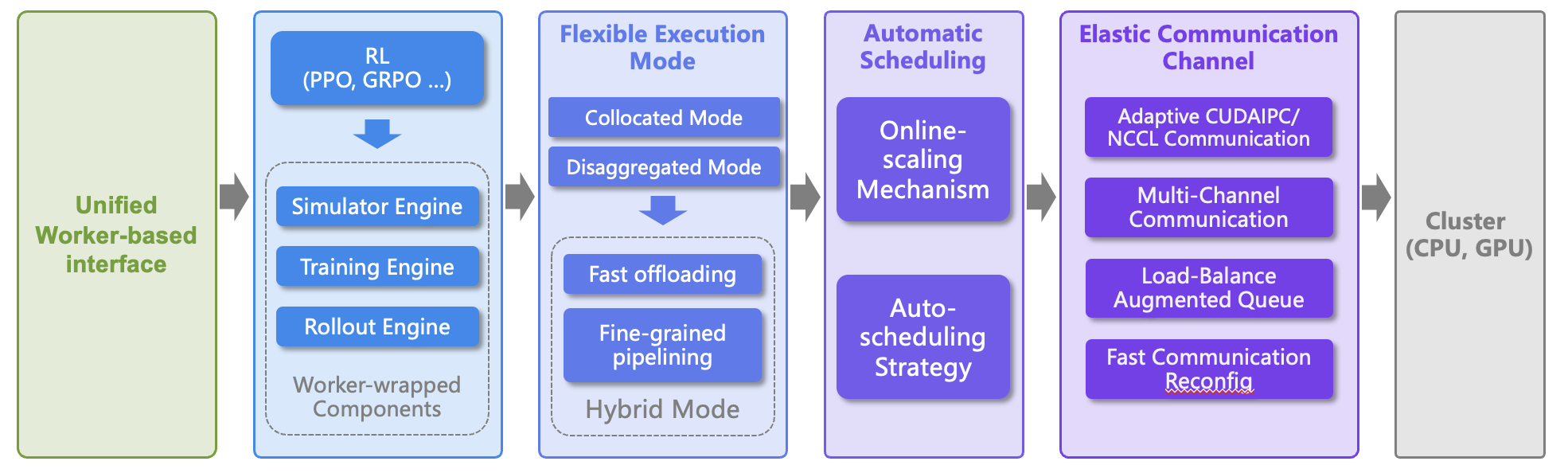
RLinf: Reinforcement Learning Infrastructure for Agentic AI
RLinf is a flexible and scalable open-source infrastructure designed for post-training foundation models (LLMs, VLMs, VLAs) via reinforcement learning. The 'inf' in RLinf stands for Infrastructure, highlighting its role as a robust backbone for next-generation training. It also stands for Infinite, symbolizing the system’s support for open-ended learning, continuous generalization, and limitless possibilities in intelligence development.
Model Description
This LoRA model is trained on Maniskill setting by SFT with base model Haozhan72/Openvla-oft-SFT-libero10-trajall. Combining this and the base model, you can get a reasonable starting checkpoint for the OpenVLA-OFT model on the ManiSkill PutOnPlateInScene25Main task defined in RL4VLA and RLinf.
How to Use
Please integrate the provided model with the RLinf codebase and the model RLinf/Openvla-oft-SFT-libero10-trajall. To do so, modify the following parameters in the configuration file examples/embodiment/config/maniskill_ppo_openvlaoft.yaml:
- Set
actor.checkpoint_load_path,actor.tokenizer.tokenizer_model, androllout.model_dirto the path of theRLinf/Openvla-oft-SFT-libero10-trajallcheckpoint. - Set
actor.model.lora_pathto the path of this LoRA checkpoint and setactor.model.is_loraas True.
Note: Currently we only support LoRA training with this checkpoint. If you do not want to use LoRA, please combine the base model and the lora checkpoint by the merge_and_unload function in the peft package.
License
This code repository and the model weights are licensed under the MIT License.
Evaluation results
- success rate on put-on-plate-in-scene-25-mainself-reportednull