
End of training
Browse files- .gitattributes +2 -0
- README.md +111 -199
- confusion_matrix_best.png +3 -0
- confusion_matrix_latest.png +3 -0
- final_model/config.json +11 -0
- final_model/model.safetensors +3 -0
- final_model/pytorch_model.bin +3 -0
- final_model/training_args.bin +3 -0
- training_args.bin +3 -0
- training_metrics.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
confusion_matrix_best.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
confusion_matrix_latest.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,199 +1,111 @@
|
|
| 1 |
-
---
|
| 2 |
-
library_name: transformers
|
| 3 |
-
tags:
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
-
|
| 21 |
-
|
| 22 |
-
-
|
| 23 |
-
-
|
| 24 |
-
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
###
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
###
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
[More Information Needed]
|
| 114 |
-
|
| 115 |
-
#### Factors
|
| 116 |
-
|
| 117 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
-
|
| 119 |
-
[More Information Needed]
|
| 120 |
-
|
| 121 |
-
#### Metrics
|
| 122 |
-
|
| 123 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
-
|
| 125 |
-
[More Information Needed]
|
| 126 |
-
|
| 127 |
-
### Results
|
| 128 |
-
|
| 129 |
-
[More Information Needed]
|
| 130 |
-
|
| 131 |
-
#### Summary
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
## Model Examination [optional]
|
| 136 |
-
|
| 137 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
-
|
| 139 |
-
[More Information Needed]
|
| 140 |
-
|
| 141 |
-
## Environmental Impact
|
| 142 |
-
|
| 143 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
-
|
| 145 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
-
|
| 147 |
-
- **Hardware Type:** [More Information Needed]
|
| 148 |
-
- **Hours used:** [More Information Needed]
|
| 149 |
-
- **Cloud Provider:** [More Information Needed]
|
| 150 |
-
- **Compute Region:** [More Information Needed]
|
| 151 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
-
|
| 153 |
-
## Technical Specifications [optional]
|
| 154 |
-
|
| 155 |
-
### Model Architecture and Objective
|
| 156 |
-
|
| 157 |
-
[More Information Needed]
|
| 158 |
-
|
| 159 |
-
### Compute Infrastructure
|
| 160 |
-
|
| 161 |
-
[More Information Needed]
|
| 162 |
-
|
| 163 |
-
#### Hardware
|
| 164 |
-
|
| 165 |
-
[More Information Needed]
|
| 166 |
-
|
| 167 |
-
#### Software
|
| 168 |
-
|
| 169 |
-
[More Information Needed]
|
| 170 |
-
|
| 171 |
-
## Citation [optional]
|
| 172 |
-
|
| 173 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
-
|
| 175 |
-
**BibTeX:**
|
| 176 |
-
|
| 177 |
-
[More Information Needed]
|
| 178 |
-
|
| 179 |
-
**APA:**
|
| 180 |
-
|
| 181 |
-
[More Information Needed]
|
| 182 |
-
|
| 183 |
-
## Glossary [optional]
|
| 184 |
-
|
| 185 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 186 |
-
|
| 187 |
-
[More Information Needed]
|
| 188 |
-
|
| 189 |
-
## More Information [optional]
|
| 190 |
-
|
| 191 |
-
[More Information Needed]
|
| 192 |
-
|
| 193 |
-
## Model Card Authors [optional]
|
| 194 |
-
|
| 195 |
-
[More Information Needed]
|
| 196 |
-
|
| 197 |
-
## Model Card Contact
|
| 198 |
-
|
| 199 |
-
[More Information Needed]
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
tags:
|
| 4 |
+
- generated_from_trainer
|
| 5 |
+
datasets:
|
| 6 |
+
- generator
|
| 7 |
+
metrics:
|
| 8 |
+
- accuracy
|
| 9 |
+
- f1
|
| 10 |
+
model-index:
|
| 11 |
+
- name: EraClassifierBiLSTM
|
| 12 |
+
results: []
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 16 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 17 |
+
|
| 18 |
+
# EraClassifierBiLSTM
|
| 19 |
+
|
| 20 |
+
This model is a fine-tuned version of [](https://huggingface.co/) on the generator dataset.
|
| 21 |
+
It achieves the following results on the evaluation set:
|
| 22 |
+
- Loss: 1.1056
|
| 23 |
+
- Accuracy: 0.5736
|
| 24 |
+
- F1: 0.4174
|
| 25 |
+
|
| 26 |
+
## Model description
|
| 27 |
+
|
| 28 |
+
More information needed
|
| 29 |
+
|
| 30 |
+
## Intended uses & limitations
|
| 31 |
+
|
| 32 |
+
More information needed
|
| 33 |
+
|
| 34 |
+
## Training and evaluation data
|
| 35 |
+
|
| 36 |
+
More information needed
|
| 37 |
+
|
| 38 |
+
## Training procedure
|
| 39 |
+
|
| 40 |
+
### Training hyperparameters
|
| 41 |
+
|
| 42 |
+
The following hyperparameters were used during training:
|
| 43 |
+
- learning_rate: 4.761974698772928e-05
|
| 44 |
+
- train_batch_size: 64
|
| 45 |
+
- eval_batch_size: 64
|
| 46 |
+
- seed: 42
|
| 47 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 48 |
+
- lr_scheduler_type: reduce_lr_on_plateau
|
| 49 |
+
- num_epochs: 5
|
| 50 |
+
- mixed_precision_training: Native AMP
|
| 51 |
+
|
| 52 |
+
### Training results
|
| 53 |
+
|
| 54 |
+
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|
| 55 |
+
|:-------------:|:------:|:-----:|:---------------:|:--------:|:------:|
|
| 56 |
+
| 1.2797 | 0.1031 | 2000 | 1.3522 | 0.4608 | 0.2486 |
|
| 57 |
+
| 1.1521 | 0.2063 | 4000 | 1.2422 | 0.4987 | 0.3139 |
|
| 58 |
+
| 1.0887 | 0.3094 | 6000 | 1.2189 | 0.5056 | 0.3223 |
|
| 59 |
+
| 1.0432 | 0.4126 | 8000 | 1.1715 | 0.5252 | 0.3479 |
|
| 60 |
+
| 1.019 | 0.5157 | 10000 | 1.2021 | 0.5150 | 0.3304 |
|
| 61 |
+
| 0.9963 | 0.6188 | 12000 | 1.1789 | 0.5252 | 0.3487 |
|
| 62 |
+
| 0.976 | 0.7220 | 14000 | 1.1151 | 0.5759 | 0.3983 |
|
| 63 |
+
| 0.9544 | 0.8251 | 16000 | 1.1800 | 0.5299 | 0.3529 |
|
| 64 |
+
| 0.9455 | 0.9283 | 18000 | 1.1866 | 0.5415 | 0.3662 |
|
| 65 |
+
| 0.9276 | 1.0314 | 20000 | 1.1744 | 0.5350 | 0.3792 |
|
| 66 |
+
| 0.9167 | 1.1345 | 22000 | 1.1032 | 0.5774 | 0.4120 |
|
| 67 |
+
| 0.9084 | 1.2377 | 24000 | 1.1312 | 0.5553 | 0.3818 |
|
| 68 |
+
| 0.8758 | 1.3408 | 26000 | 1.1042 | 0.5667 | 0.4109 |
|
| 69 |
+
| 0.859 | 1.4440 | 28000 | 1.1065 | 0.5733 | 0.4125 |
|
| 70 |
+
| 0.8607 | 1.5471 | 30000 | 1.1104 | 0.5695 | 0.4115 |
|
| 71 |
+
| 0.8526 | 1.6503 | 32000 | 1.1011 | 0.5830 | 0.4255 |
|
| 72 |
+
| 0.8559 | 1.7534 | 34000 | 1.1083 | 0.5765 | 0.4136 |
|
| 73 |
+
| 0.8501 | 1.8565 | 36000 | 1.1113 | 0.5752 | 0.4163 |
|
| 74 |
+
| 0.8497 | 1.9597 | 38000 | 1.0935 | 0.5775 | 0.4220 |
|
| 75 |
+
| 0.8473 | 2.0628 | 40000 | 1.1092 | 0.5745 | 0.4181 |
|
| 76 |
+
| 0.8441 | 2.1660 | 42000 | 1.1095 | 0.5733 | 0.4164 |
|
| 77 |
+
| 0.8396 | 2.2691 | 44000 | 1.0935 | 0.5852 | 0.4299 |
|
| 78 |
+
| 0.8391 | 2.3722 | 46000 | 1.1054 | 0.5744 | 0.4160 |
|
| 79 |
+
| 0.8401 | 2.4754 | 48000 | 1.1008 | 0.5755 | 0.4198 |
|
| 80 |
+
| 0.8327 | 2.5785 | 50000 | 1.1097 | 0.5712 | 0.4132 |
|
| 81 |
+
| 0.838 | 2.6817 | 52000 | 1.1055 | 0.5720 | 0.4143 |
|
| 82 |
+
| 0.8329 | 2.7848 | 54000 | 1.1055 | 0.5728 | 0.4165 |
|
| 83 |
+
| 0.8346 | 2.8879 | 56000 | 1.1038 | 0.5743 | 0.4172 |
|
| 84 |
+
| 0.8353 | 2.9911 | 58000 | 1.1090 | 0.5728 | 0.4167 |
|
| 85 |
+
| 0.8385 | 3.0942 | 60000 | 1.1013 | 0.5755 | 0.4201 |
|
| 86 |
+
| 0.8337 | 3.1974 | 62000 | 1.1088 | 0.5733 | 0.4163 |
|
| 87 |
+
| 0.8256 | 3.3005 | 64000 | 1.1076 | 0.5748 | 0.4177 |
|
| 88 |
+
| 0.8367 | 3.4036 | 66000 | 1.1066 | 0.5730 | 0.4159 |
|
| 89 |
+
| 0.831 | 3.5068 | 68000 | 1.1083 | 0.5732 | 0.4164 |
|
| 90 |
+
| 0.8283 | 3.6099 | 70000 | 1.1067 | 0.5744 | 0.4173 |
|
| 91 |
+
| 0.8349 | 3.7131 | 72000 | 1.1058 | 0.5747 | 0.4180 |
|
| 92 |
+
| 0.8313 | 3.8162 | 74000 | 1.1058 | 0.5741 | 0.4171 |
|
| 93 |
+
| 0.8313 | 3.9193 | 76000 | 1.1065 | 0.5735 | 0.4169 |
|
| 94 |
+
| 0.8309 | 4.0225 | 78000 | 1.1067 | 0.5736 | 0.4171 |
|
| 95 |
+
| 0.8331 | 4.1256 | 80000 | 1.1055 | 0.5744 | 0.4174 |
|
| 96 |
+
| 0.8371 | 4.2288 | 82000 | 1.1058 | 0.5735 | 0.4167 |
|
| 97 |
+
| 0.8344 | 4.3319 | 84000 | 1.1060 | 0.5734 | 0.4166 |
|
| 98 |
+
| 0.8291 | 4.4350 | 86000 | 1.1049 | 0.5747 | 0.4185 |
|
| 99 |
+
| 0.8343 | 4.5382 | 88000 | 1.1053 | 0.5735 | 0.4171 |
|
| 100 |
+
| 0.8293 | 4.6413 | 90000 | 1.1056 | 0.5736 | 0.4174 |
|
| 101 |
+
| 0.8294 | 4.7445 | 92000 | 1.1056 | 0.5736 | 0.4174 |
|
| 102 |
+
| 0.8316 | 4.8476 | 94000 | 1.1055 | 0.5736 | 0.4174 |
|
| 103 |
+
| 0.8264 | 4.9508 | 96000 | 1.1056 | 0.5736 | 0.4174 |
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
### Framework versions
|
| 107 |
+
|
| 108 |
+
- Transformers 4.49.0
|
| 109 |
+
- Pytorch 2.6.0+cu126
|
| 110 |
+
- Datasets 3.3.2
|
| 111 |
+
- Tokenizers 0.21.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
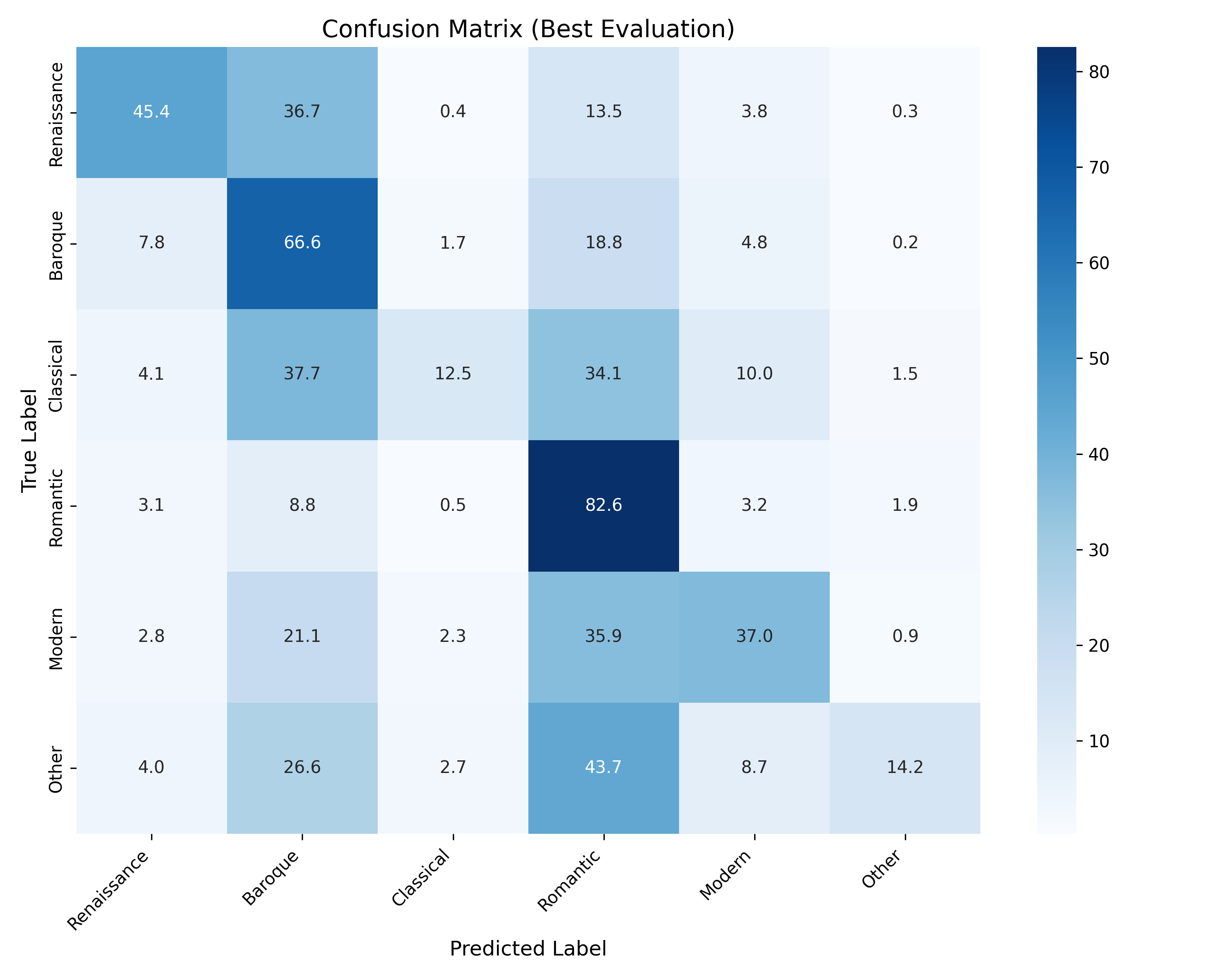
confusion_matrix_best.png
ADDED
|
Git LFS Details
|
confusion_matrix_latest.png
ADDED

|
Git LFS Details
|
final_model/config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"EraClassifierBiLSTM"
|
| 4 |
+
],
|
| 5 |
+
"hidden_size": 384,
|
| 6 |
+
"input_size": 8,
|
| 7 |
+
"num_eras": 6,
|
| 8 |
+
"num_layers": 2,
|
| 9 |
+
"torch_dtype": "float32",
|
| 10 |
+
"transformers_version": "4.49.0"
|
| 11 |
+
}
|
final_model/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:696d0c893fe4741cbcc3a67ff26be5367882d4978bf725c4d455bd5ce6ee71b1
|
| 3 |
+
size 19041840
|
final_model/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:015d8295dff65e2d870118c7ac70a1a548616a7ab7f60625ed51c676aca423ca
|
| 3 |
+
size 19043582
|
final_model/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:143ef019a635ec41710daf91a1f3029d14c0ed1784f5d1396b88e916624161c8
|
| 3 |
+
size 5304
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:143ef019a635ec41710daf91a1f3029d14c0ed1784f5d1396b88e916624161c8
|
| 3 |
+
size 5304
|
training_metrics.png
ADDED

|