
Upload 25 files
Browse files- .gitattributes +5 -0
- NeuroRVQ/NeuroRVQ.py +821 -0
- NeuroRVQ/NeuroRVQ_modules.py +254 -0
- NeuroRVQ/RVQ.py +67 -0
- NeuroRVQ/__init__.py +2 -0
- NeuroRVQ/norm_ema_quantizer.py +204 -0
- README.md +132 -0
- example_files/eeg_sample/example_eeg_file.xdf +3 -0
- fine_tuning/NeuroRVQ_EEG_FM_FineTuning.py +163 -0
- fine_tuning/data.py +87 -0
- fine_tuning/utils.py +51 -0
- fine_tuning/wrappers.py +45 -0
- flags/NeuroRVQ_EEG_v1.yml +47 -0
- images/banner.png +3 -0
- images/ecg.png +3 -0
- images/eeg.png +3 -0
- images/emg.png +3 -0
- inference/modules/NeuroRVQ_EEG_FM_inference_modules.py +48 -0
- inference/modules/NeuroRVQ_EEG_tokenizer_inference_modules.py +48 -0
- inference/run/NeuroRVQ_EEG_FM_example.py +107 -0
- inference/run/NeuroRVQ_EEG_tokenizer_example.py +50 -0
- plotting/plotting_example.py +84 -0
- preprocessing/preprocessing_eeg_example.py +55 -0
- pretrained_models/foundation_models/NeuroRVQ_EEG_foundation_model_v1.pt +3 -0
- pretrained_models/tokenizers/NeuroRVQ_EEG_tokenizer_v1.pt +3 -0
- requirements.txt +189 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
example_files/eeg_sample/example_eeg_file.xdf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/banner.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
images/ecg.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
images/eeg.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
images/emg.png filter=lfs diff=lfs merge=lfs -text
|
NeuroRVQ/NeuroRVQ.py
ADDED
|
@@ -0,0 +1,821 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
from einops import rearrange
|
| 5 |
+
import math
|
| 6 |
+
from functools import partial
|
| 7 |
+
import os
|
| 8 |
+
import sys
|
| 9 |
+
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
|
| 10 |
+
from NeuroRVQ_modules import Block, trunc_normal_
|
| 11 |
+
from RVQ import ResidualVectorQuantization
|
| 12 |
+
|
| 13 |
+
def inverse_fft_cos_sin(fft_amp, fft_sin_pha, fft_cos_pha):
|
| 14 |
+
"""
|
| 15 |
+
Inverse FFT function using sin and cos
|
| 16 |
+
:param fft_amp: amplitude
|
| 17 |
+
:param fft_sin_pha: sine
|
| 18 |
+
:param fft_cos_pha: cosine
|
| 19 |
+
:return: inverse fft in time
|
| 20 |
+
"""
|
| 21 |
+
imag = fft_amp * fft_sin_pha
|
| 22 |
+
real = fft_amp * fft_cos_pha
|
| 23 |
+
fft_y = torch.complex(real, imag)
|
| 24 |
+
y = torch.fft.ifft(fft_y)
|
| 25 |
+
return y
|
| 26 |
+
|
| 27 |
+
class PatchEmbed(nn.Module):
|
| 28 |
+
"""
|
| 29 |
+
Project each codebook to the patch latent space
|
| 30 |
+
:param in_chans: number of input channels
|
| 31 |
+
:param embed_dim: dimension of embedding space
|
| 32 |
+
"""
|
| 33 |
+
def __init__(self, in_chans=1, embed_dim=200):
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=(1, 1), stride=(1, 1))
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 38 |
+
return x
|
| 39 |
+
|
| 40 |
+
class MultiDimentionalTemporalConv(nn.Module):
|
| 41 |
+
"""
|
| 42 |
+
EEG to Patch Embedding - Multidimentional Temporal Filtering
|
| 43 |
+
:param in_chans: number of input channels
|
| 44 |
+
:param out_chans: number of output channels
|
| 45 |
+
"""
|
| 46 |
+
def __init__(self, in_chans=1, out_chans=8):
|
| 47 |
+
super().__init__()
|
| 48 |
+
# Inception Style Seperate Branches - Group 1 #
|
| 49 |
+
# Branch 1: >10 Hz assuming fs=200Hz
|
| 50 |
+
self.conv1_1 = nn.Conv2d(in_chans, out_chans, kernel_size=(1, 21), padding=(0, 10))
|
| 51 |
+
self.norm1_1 = nn.GroupNorm(4, out_chans)
|
| 52 |
+
self.pool1_1 = nn.AvgPool2d(kernel_size=(1, 2))
|
| 53 |
+
|
| 54 |
+
# Branch 2: >13 Hz assuming fs=200Hz
|
| 55 |
+
self.conv1_2 = nn.Conv2d(in_chans, out_chans, kernel_size=(1, 15), padding=(0, 7))
|
| 56 |
+
self.norm1_2 = nn.GroupNorm(4, out_chans)
|
| 57 |
+
self.pool1_2 = nn.AvgPool2d(kernel_size=(1, 2))
|
| 58 |
+
|
| 59 |
+
# Branch 3: >20 Hz assuming fs=200Hz
|
| 60 |
+
self.conv1_3 = nn.Conv2d(in_chans, out_chans, kernel_size=(1, 9), padding=(0, 4))
|
| 61 |
+
self.norm1_3 = nn.GroupNorm(4, out_chans)
|
| 62 |
+
self.pool1_3 = nn.AvgPool2d(kernel_size=(1, 2))
|
| 63 |
+
|
| 64 |
+
# Branch 4: >40 Hz assuming fs=200Hz
|
| 65 |
+
self.conv1_4 = nn.Conv2d(in_chans, out_chans, kernel_size=(1, 5), padding=(0, 2))
|
| 66 |
+
self.norm1_4 = nn.GroupNorm(4, out_chans)
|
| 67 |
+
self.pool1_4 = nn.AvgPool2d(kernel_size=(1, 2))
|
| 68 |
+
self.gelu1 = nn.GELU()
|
| 69 |
+
|
| 70 |
+
# Inception Style Seperate Branches - Group 2 #
|
| 71 |
+
self.conv2_1 = nn.Conv2d(out_chans, out_chans, kernel_size=(1, 9), padding=(0, 4))
|
| 72 |
+
self.norm2_1 = nn.GroupNorm(4, out_chans)
|
| 73 |
+
self.pool2_1 = nn.AvgPool2d(kernel_size=(1, 4))
|
| 74 |
+
|
| 75 |
+
self.conv2_2 = nn.Conv2d(out_chans, out_chans, kernel_size=(1, 7), padding=(0, 3))
|
| 76 |
+
self.norm2_2 = nn.GroupNorm(4, out_chans)
|
| 77 |
+
self.pool2_2 = nn.AvgPool2d(kernel_size=(1, 4))
|
| 78 |
+
|
| 79 |
+
self.conv2_3 = nn.Conv2d(out_chans, out_chans, kernel_size=(1, 5), padding=(0, 2))
|
| 80 |
+
self.norm2_3 = nn.GroupNorm(4, out_chans)
|
| 81 |
+
self.pool2_3 = nn.AvgPool2d(kernel_size=(1, 4))
|
| 82 |
+
|
| 83 |
+
self.conv2_4 = nn.Conv2d(out_chans, out_chans, kernel_size=(1, 3), padding=(0, 1))
|
| 84 |
+
self.norm2_4 = nn.GroupNorm(4, out_chans)
|
| 85 |
+
self.pool2_4 = nn.AvgPool2d(kernel_size=(1, 4))
|
| 86 |
+
self.gelu2 = nn.GELU()
|
| 87 |
+
|
| 88 |
+
def forward(self, x):
|
| 89 |
+
x = rearrange(x, 'B N A T -> B (N A) T')
|
| 90 |
+
x = x.unsqueeze(1)
|
| 91 |
+
|
| 92 |
+
# First layer of filtering - Group 1
|
| 93 |
+
x1 = self.pool1_1(self.gelu1(self.norm1_1(self.conv1_1(x))))
|
| 94 |
+
x2 = self.pool1_2(self.gelu1(self.norm1_2(self.conv1_2(x))))
|
| 95 |
+
x3 = self.pool1_3(self.gelu1(self.norm1_3(self.conv1_3(x))))
|
| 96 |
+
x4 = self.pool1_4(self.gelu1(self.norm1_4(self.conv1_4(x))))
|
| 97 |
+
|
| 98 |
+
# First layer of filtering - Group 2
|
| 99 |
+
x1 = self.pool2_1(self.gelu2(self.norm2_1(self.conv2_1(x1))))
|
| 100 |
+
x2 = self.pool2_2(self.gelu2(self.norm2_2(self.conv2_2(x2))))
|
| 101 |
+
x3 = self.pool2_3(self.gelu2(self.norm2_3(self.conv2_3(x3))))
|
| 102 |
+
x4 = self.pool2_4(self.gelu2(self.norm2_4(self.conv2_4(x4))))
|
| 103 |
+
|
| 104 |
+
# Re-arrange
|
| 105 |
+
x1 = rearrange(x1, 'B C NA T -> B NA (T C)')
|
| 106 |
+
x2 = rearrange(x2, 'B C NA T -> B NA (T C)')
|
| 107 |
+
x3 = rearrange(x3, 'B C NA T -> B NA (T C)')
|
| 108 |
+
x4 = rearrange(x4, 'B C NA T -> B NA (T C)')
|
| 109 |
+
return x1, x2, x3, x4
|
| 110 |
+
|
| 111 |
+
class NeuroRVQFM(nn.Module):
|
| 112 |
+
"""
|
| 113 |
+
NeuroRVQ Foundation Model Class
|
| 114 |
+
"""
|
| 115 |
+
def __init__(self, n_patches=256, patch_size=200, in_chans=1, out_chans=8, num_classes=5,
|
| 116 |
+
embed_dim=200, depth=12, num_heads=10, mlp_ratio=4., qkv_bias=False, qk_norm=None, drop_rate=0.,
|
| 117 |
+
attn_drop_rate=0., drop_path_rate=0., init_values=None, init_scale=0.001,
|
| 118 |
+
n_global_electrodes=127, vocab_size=8192, use_as_encoder=True, use_for_pretraining=False):
|
| 119 |
+
|
| 120 |
+
super().__init__()
|
| 121 |
+
|
| 122 |
+
self.num_classes = num_classes
|
| 123 |
+
self.embed_dim = embed_dim
|
| 124 |
+
self.num_heads = num_heads
|
| 125 |
+
self.patch_size = patch_size
|
| 126 |
+
self.use_for_pretraining = use_for_pretraining
|
| 127 |
+
self.use_as_encoder = use_as_encoder
|
| 128 |
+
# Not necessary - legacy code
|
| 129 |
+
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 130 |
+
|
| 131 |
+
# To identify whether patch_embed layer is used as tokenizer/encoder or as a decoder
|
| 132 |
+
if use_as_encoder or use_for_pretraining:
|
| 133 |
+
self.patch_embed = MultiDimentionalTemporalConv(out_chans=out_chans)
|
| 134 |
+
else:
|
| 135 |
+
self.patch_embed_1 = PatchEmbed(in_chans=in_chans, embed_dim=embed_dim)
|
| 136 |
+
self.patch_embed_2 = PatchEmbed(in_chans=in_chans, embed_dim=embed_dim)
|
| 137 |
+
self.patch_embed_3 = PatchEmbed(in_chans=in_chans, embed_dim=embed_dim)
|
| 138 |
+
self.patch_embed_4 = PatchEmbed(in_chans=in_chans, embed_dim=embed_dim)
|
| 139 |
+
|
| 140 |
+
self.pos_embed = nn.Parameter(torch.zeros(n_global_electrodes + 1, embed_dim), requires_grad=True)
|
| 141 |
+
self.time_embed = nn.Parameter(torch.zeros(n_patches, embed_dim), requires_grad=True)
|
| 142 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 143 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
|
| 144 |
+
|
| 145 |
+
self.blocks = nn.ModuleList([
|
| 146 |
+
Block(
|
| 147 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_norm=qk_norm,
|
| 148 |
+
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=nn.LayerNorm,
|
| 149 |
+
init_values=init_values, window_size=None)
|
| 150 |
+
for i in range(depth)])
|
| 151 |
+
|
| 152 |
+
# If used for pre-training we need heads to predict 8 * 4 tokens per input sample
|
| 153 |
+
# TODO: Modular
|
| 154 |
+
if use_for_pretraining:
|
| 155 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 156 |
+
self.norm_pre = nn.LayerNorm(embed_dim)
|
| 157 |
+
self.head_pre_1 = nn.Linear(embed_dim, vocab_size)
|
| 158 |
+
self.head_pre_2 = nn.Linear(embed_dim, vocab_size)
|
| 159 |
+
self.head_pre_3 = nn.Linear(embed_dim, vocab_size)
|
| 160 |
+
self.head_pre_4 = nn.Linear(embed_dim, vocab_size)
|
| 161 |
+
self.head_pre_5 = nn.Linear(embed_dim, vocab_size)
|
| 162 |
+
self.head_pre_6 = nn.Linear(embed_dim, vocab_size)
|
| 163 |
+
self.head_pre_7 = nn.Linear(embed_dim, vocab_size)
|
| 164 |
+
self.head_pre_8 = nn.Linear(embed_dim, vocab_size)
|
| 165 |
+
self.head_pre_9 = nn.Linear(embed_dim, vocab_size)
|
| 166 |
+
self.head_pre_10 = nn.Linear(embed_dim, vocab_size)
|
| 167 |
+
self.head_pre_11 = nn.Linear(embed_dim, vocab_size)
|
| 168 |
+
self.head_pre_12 = nn.Linear(embed_dim, vocab_size)
|
| 169 |
+
self.head_pre_13 = nn.Linear(embed_dim, vocab_size)
|
| 170 |
+
self.head_pre_14 = nn.Linear(embed_dim, vocab_size)
|
| 171 |
+
self.head_pre_15 = nn.Linear(embed_dim, vocab_size)
|
| 172 |
+
self.head_pre_16 = nn.Linear(embed_dim, vocab_size)
|
| 173 |
+
self.head_pre_17 = nn.Linear(embed_dim, vocab_size)
|
| 174 |
+
self.head_pre_18 = nn.Linear(embed_dim, vocab_size)
|
| 175 |
+
self.head_pre_19 = nn.Linear(embed_dim, vocab_size)
|
| 176 |
+
self.head_pre_20 = nn.Linear(embed_dim, vocab_size)
|
| 177 |
+
self.head_pre_21 = nn.Linear(embed_dim, vocab_size)
|
| 178 |
+
self.head_pre_22 = nn.Linear(embed_dim, vocab_size)
|
| 179 |
+
self.head_pre_23 = nn.Linear(embed_dim, vocab_size)
|
| 180 |
+
self.head_pre_24 = nn.Linear(embed_dim, vocab_size)
|
| 181 |
+
self.head_pre_25 = nn.Linear(embed_dim, vocab_size)
|
| 182 |
+
self.head_pre_26 = nn.Linear(embed_dim, vocab_size)
|
| 183 |
+
self.head_pre_27 = nn.Linear(embed_dim, vocab_size)
|
| 184 |
+
self.head_pre_28 = nn.Linear(embed_dim, vocab_size)
|
| 185 |
+
self.head_pre_29 = nn.Linear(embed_dim, vocab_size)
|
| 186 |
+
self.head_pre_30 = nn.Linear(embed_dim, vocab_size)
|
| 187 |
+
self.head_pre_31 = nn.Linear(embed_dim, vocab_size)
|
| 188 |
+
self.head_pre_32 = nn.Linear(embed_dim, vocab_size)
|
| 189 |
+
else:
|
| 190 |
+
self.norm = nn.Identity()
|
| 191 |
+
self.fc_norm_1 = nn.LayerNorm(embed_dim)
|
| 192 |
+
self.head_1 = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 193 |
+
self.fc_norm_2 = nn.LayerNorm(embed_dim)
|
| 194 |
+
self.head_2 = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 195 |
+
self.fc_norm_3 = nn.LayerNorm(embed_dim)
|
| 196 |
+
self.head_3 = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 197 |
+
self.fc_norm_4 = nn.LayerNorm(embed_dim)
|
| 198 |
+
self.head_4 = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 199 |
+
|
| 200 |
+
# Initialize the weights of the network
|
| 201 |
+
trunc_normal_(self.pos_embed, std=.02)
|
| 202 |
+
trunc_normal_(self.time_embed, std=.02)
|
| 203 |
+
trunc_normal_(self.cls_token, std=.02)
|
| 204 |
+
|
| 205 |
+
# Initialization ONLY during pretraining
|
| 206 |
+
if use_for_pretraining:
|
| 207 |
+
trunc_normal_(self.mask_token, std=.02)
|
| 208 |
+
trunc_normal_(self.head_pre_1.weight, std=.02)
|
| 209 |
+
trunc_normal_(self.head_pre_2.weight, std=.02)
|
| 210 |
+
trunc_normal_(self.head_pre_3.weight, std=.02)
|
| 211 |
+
trunc_normal_(self.head_pre_4.weight, std=.02)
|
| 212 |
+
trunc_normal_(self.head_pre_5.weight, std=.02)
|
| 213 |
+
trunc_normal_(self.head_pre_6.weight, std=.02)
|
| 214 |
+
trunc_normal_(self.head_pre_7.weight, std=.02)
|
| 215 |
+
trunc_normal_(self.head_pre_8.weight, std=.02)
|
| 216 |
+
trunc_normal_(self.head_pre_9.weight, std=.02)
|
| 217 |
+
trunc_normal_(self.head_pre_10.weight, std=.02)
|
| 218 |
+
trunc_normal_(self.head_pre_11.weight, std=.02)
|
| 219 |
+
trunc_normal_(self.head_pre_12.weight, std=.02)
|
| 220 |
+
trunc_normal_(self.head_pre_13.weight, std=.02)
|
| 221 |
+
trunc_normal_(self.head_pre_14.weight, std=.02)
|
| 222 |
+
trunc_normal_(self.head_pre_15.weight, std=.02)
|
| 223 |
+
trunc_normal_(self.head_pre_16.weight, std=.02)
|
| 224 |
+
trunc_normal_(self.head_pre_17.weight, std=.02)
|
| 225 |
+
trunc_normal_(self.head_pre_18.weight, std=.02)
|
| 226 |
+
trunc_normal_(self.head_pre_19.weight, std=.02)
|
| 227 |
+
trunc_normal_(self.head_pre_20.weight, std=.02)
|
| 228 |
+
trunc_normal_(self.head_pre_21.weight, std=.02)
|
| 229 |
+
trunc_normal_(self.head_pre_22.weight, std=.02)
|
| 230 |
+
trunc_normal_(self.head_pre_23.weight, std=.02)
|
| 231 |
+
trunc_normal_(self.head_pre_24.weight, std=.02)
|
| 232 |
+
trunc_normal_(self.head_pre_25.weight, std=.02)
|
| 233 |
+
trunc_normal_(self.head_pre_26.weight, std=.02)
|
| 234 |
+
trunc_normal_(self.head_pre_27.weight, std=.02)
|
| 235 |
+
trunc_normal_(self.head_pre_28.weight, std=.02)
|
| 236 |
+
trunc_normal_(self.head_pre_29.weight, std=.02)
|
| 237 |
+
trunc_normal_(self.head_pre_30.weight, std=.02)
|
| 238 |
+
trunc_normal_(self.head_pre_31.weight, std=.02)
|
| 239 |
+
trunc_normal_(self.head_pre_32.weight, std=.02)
|
| 240 |
+
else:
|
| 241 |
+
if isinstance(self.head_1, nn.Linear):
|
| 242 |
+
trunc_normal_(self.head_1.weight, std=.02)
|
| 243 |
+
if isinstance(self.head_1, nn.Linear):
|
| 244 |
+
self.head_1.weight.data.mul_(init_scale)
|
| 245 |
+
self.head_1.bias.data.mul_(init_scale)
|
| 246 |
+
if isinstance(self.head_2, nn.Linear):
|
| 247 |
+
trunc_normal_(self.head_2.weight, std=.02)
|
| 248 |
+
if isinstance(self.head_2, nn.Linear):
|
| 249 |
+
self.head_2.weight.data.mul_(init_scale)
|
| 250 |
+
self.head_2.bias.data.mul_(init_scale)
|
| 251 |
+
if isinstance(self.head_3, nn.Linear):
|
| 252 |
+
trunc_normal_(self.head_3.weight, std=.02)
|
| 253 |
+
if isinstance(self.head_3, nn.Linear):
|
| 254 |
+
self.head_3.weight.data.mul_(init_scale)
|
| 255 |
+
self.head_3.bias.data.mul_(init_scale)
|
| 256 |
+
if isinstance(self.head_4, nn.Linear):
|
| 257 |
+
trunc_normal_(self.head_4.weight, std=.02)
|
| 258 |
+
if isinstance(self.head_4, nn.Linear):
|
| 259 |
+
self.head_4.weight.data.mul_(init_scale)
|
| 260 |
+
self.head_4.bias.data.mul_(init_scale)
|
| 261 |
+
|
| 262 |
+
self.apply(self._init_weights)
|
| 263 |
+
self.fix_init_weight()
|
| 264 |
+
|
| 265 |
+
# Function to initialize the weights of the network
|
| 266 |
+
def fix_init_weight(self):
|
| 267 |
+
def rescale(param, layer_id):
|
| 268 |
+
param.div_(math.sqrt(2.0 * layer_id))
|
| 269 |
+
for layer_id, layer in enumerate(self.blocks):
|
| 270 |
+
rescale(layer.attn.proj.weight.data, layer_id + 1)
|
| 271 |
+
rescale(layer.mlp.fc2.weight.data, layer_id + 1)
|
| 272 |
+
|
| 273 |
+
# Function to initialize the weights of the network
|
| 274 |
+
def _init_weights(self, m):
|
| 275 |
+
if isinstance(m, nn.Linear):
|
| 276 |
+
trunc_normal_(m.weight, std=.02)
|
| 277 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 278 |
+
nn.init.constant_(m.bias, 0)
|
| 279 |
+
elif isinstance(m, nn.LayerNorm):
|
| 280 |
+
nn.init.constant_(m.bias, 0)
|
| 281 |
+
nn.init.constant_(m.weight, 1.0)
|
| 282 |
+
elif isinstance(m, nn.Conv2d):
|
| 283 |
+
trunc_normal_(m.weight, std=.02)
|
| 284 |
+
if m.bias is not None:
|
| 285 |
+
nn.init.constant_(m.bias, 0)
|
| 286 |
+
|
| 287 |
+
# Get number of layers from the transformer
|
| 288 |
+
def get_num_layers(self):
|
| 289 |
+
return len(self.blocks)
|
| 290 |
+
|
| 291 |
+
# Get classification head
|
| 292 |
+
def get_classifier(self):
|
| 293 |
+
return self.head
|
| 294 |
+
|
| 295 |
+
# Reset the classification head
|
| 296 |
+
def reset_classifier(self, num_classes):
|
| 297 |
+
self.num_classes = num_classes
|
| 298 |
+
self.fc_norm = nn.LayerNorm(self.embed_dim * 4) # multiply dim by 4 for concat [x1,x2,x3,x4]
|
| 299 |
+
self.head = nn.Linear(self.embed_dim * 4, num_classes) if num_classes > 0 else nn.Identity()
|
| 300 |
+
|
| 301 |
+
@torch.jit.ignore
|
| 302 |
+
def no_weight_decay(self):
|
| 303 |
+
return {'pos_embed', 'cls_token', 'time_embed'}
|
| 304 |
+
|
| 305 |
+
def forward(self, x, temporal_embedding_ix, spatial_embedding_ix, return_patch_tokens=False, bool_masked_pos=None, use_for_pretraining=False, branch_idx=0):
|
| 306 |
+
'''
|
| 307 |
+
x: [batch size, number of electrodes, number of patches, patch size]
|
| 308 |
+
For example, for an EEG sample of 4 seconds with 64 electrodes, x will be [batch size, 64, 4, 200]
|
| 309 |
+
'''
|
| 310 |
+
if (self.use_as_encoder):
|
| 311 |
+
x1, x2, x3, x4 = self.patch_embed(x)
|
| 312 |
+
x = x1
|
| 313 |
+
else:
|
| 314 |
+
if (branch_idx==0):
|
| 315 |
+
x = self.patch_embed_1(x)
|
| 316 |
+
elif (branch_idx==1):
|
| 317 |
+
x = self.patch_embed_2(x)
|
| 318 |
+
elif (branch_idx==2):
|
| 319 |
+
x = self.patch_embed_3(x)
|
| 320 |
+
elif (branch_idx==3):
|
| 321 |
+
x = self.patch_embed_4(x)
|
| 322 |
+
|
| 323 |
+
batch_size, seq_len, _ = x.size()
|
| 324 |
+
|
| 325 |
+
# Concatenate the cls token - Legacy code
|
| 326 |
+
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
|
| 327 |
+
|
| 328 |
+
# ONLY in Pre-Training - Masking technique used in LaBraM
|
| 329 |
+
if (use_for_pretraining or bool_masked_pos is not None):
|
| 330 |
+
mask_token = self.mask_token.expand(batch_size, seq_len, -1)
|
| 331 |
+
w = bool_masked_pos.unsqueeze(-1).type_as(mask_token)
|
| 332 |
+
symmetric_bool_masked_pos = ~bool_masked_pos
|
| 333 |
+
w_symmetric = symmetric_bool_masked_pos.unsqueeze(-1).type_as(mask_token)
|
| 334 |
+
|
| 335 |
+
x_symmetric_1 = x1 * (1 - w_symmetric) + mask_token * w_symmetric
|
| 336 |
+
x1 = x1 * (1 - w) + mask_token * w
|
| 337 |
+
x_symmetric_1 = torch.cat((cls_tokens, x_symmetric_1), dim=1)
|
| 338 |
+
|
| 339 |
+
x_symmetric_2 = x2 * (1 - w_symmetric) + mask_token * w_symmetric
|
| 340 |
+
x2 = x2 * (1 - w) + mask_token * w
|
| 341 |
+
x_symmetric_2 = torch.cat((cls_tokens, x_symmetric_2), dim=1)
|
| 342 |
+
|
| 343 |
+
x_symmetric_3 = x3 * (1 - w_symmetric) + mask_token * w_symmetric
|
| 344 |
+
x3 = x3 * (1 - w) + mask_token * w
|
| 345 |
+
x_symmetric_3 = torch.cat((cls_tokens, x_symmetric_3), dim=1)
|
| 346 |
+
|
| 347 |
+
x_symmetric_4 = x4 * (1 - w_symmetric) + mask_token * w_symmetric
|
| 348 |
+
x4 = x4 * (1 - w) + mask_token * w
|
| 349 |
+
x_symmetric_4 = torch.cat((cls_tokens, x_symmetric_4), dim=1)
|
| 350 |
+
|
| 351 |
+
if (self.use_as_encoder):
|
| 352 |
+
x1 = torch.cat((cls_tokens, x1), dim=1)
|
| 353 |
+
x2 = torch.cat((cls_tokens, x2), dim=1)
|
| 354 |
+
x3 = torch.cat((cls_tokens, x3), dim=1)
|
| 355 |
+
x4 = torch.cat((cls_tokens, x4), dim=1)
|
| 356 |
+
else:
|
| 357 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 358 |
+
|
| 359 |
+
# Pad the spatial_embedding_ix - spatial_embedding_ix: (batch, n_patches), spatial_embedding: (n_electrodes + 1, embed_dim)
|
| 360 |
+
spatial_embedding_ix = F.pad(input=spatial_embedding_ix, pad=(1, 0), mode='constant', value=0) # for cls token (batch_size, n_patches + 1)
|
| 361 |
+
# Gets the corresponding pos_embed
|
| 362 |
+
spatial_embedding = self.pos_embed[spatial_embedding_ix.reshape(-1), :] # (batch_size * (n_patches + 1), embed_dim)
|
| 363 |
+
spatial_embedding = spatial_embedding.reshape(spatial_embedding_ix.shape[0], spatial_embedding_ix.shape[1], spatial_embedding.shape[-1]) # (batch_size, n_patches + 1, embed_dim)
|
| 364 |
+
|
| 365 |
+
if (self.use_as_encoder):
|
| 366 |
+
x1 = x1 + spatial_embedding
|
| 367 |
+
x2 = x2 + spatial_embedding
|
| 368 |
+
x3 = x3 + spatial_embedding
|
| 369 |
+
x4 = x4 + spatial_embedding
|
| 370 |
+
else:
|
| 371 |
+
x = x + spatial_embedding
|
| 372 |
+
|
| 373 |
+
# temporal_embedding_ix: (batch, n_patches), temporal_embedding: (n_patches, embed_dim)
|
| 374 |
+
temporal_embedding = self.time_embed[temporal_embedding_ix.reshape(-1), :] # (batch_size * (n_patches), embed_dim)
|
| 375 |
+
temporal_embedding = temporal_embedding.reshape(temporal_embedding_ix.shape[0], temporal_embedding_ix.shape[1], temporal_embedding.shape[-1]) # (batch_size, n_patches, embed_dim)
|
| 376 |
+
|
| 377 |
+
if (self.use_as_encoder):
|
| 378 |
+
x1[:, 1:, :] += temporal_embedding
|
| 379 |
+
x1 = self.pos_drop(x1)
|
| 380 |
+
x2[:, 1:, :] += temporal_embedding
|
| 381 |
+
x2 = self.pos_drop(x2)
|
| 382 |
+
x3[:, 1:, :] += temporal_embedding
|
| 383 |
+
x3 = self.pos_drop(x3)
|
| 384 |
+
x4[:, 1:, :] += temporal_embedding
|
| 385 |
+
x4 = self.pos_drop(x4)
|
| 386 |
+
else:
|
| 387 |
+
x[:, 1:, :] += temporal_embedding
|
| 388 |
+
x = self.pos_drop(x)
|
| 389 |
+
|
| 390 |
+
if (self.use_as_encoder):
|
| 391 |
+
# Pass the transformer blocks
|
| 392 |
+
for i, x in enumerate([x1, x2, x3, x4]):
|
| 393 |
+
for blk in self.blocks:
|
| 394 |
+
x = blk(x)
|
| 395 |
+
|
| 396 |
+
if (use_for_pretraining or bool_masked_pos is not None):
|
| 397 |
+
x = self.norm_pre(x)
|
| 398 |
+
else:
|
| 399 |
+
x = self.norm(x)
|
| 400 |
+
# All except cls token
|
| 401 |
+
if i == 0:
|
| 402 |
+
x1 = x[:, 1:, :]
|
| 403 |
+
elif i == 1:
|
| 404 |
+
x2 = x[:, 1:, :]
|
| 405 |
+
elif i == 2:
|
| 406 |
+
x3 = x[:, 1:, :]
|
| 407 |
+
else:
|
| 408 |
+
x4 = x[:, 1:, :]
|
| 409 |
+
else:
|
| 410 |
+
# Pass the transformer blocks
|
| 411 |
+
for blk in self.blocks:
|
| 412 |
+
x = blk(x)
|
| 413 |
+
if (use_for_pretraining or bool_masked_pos is not None):
|
| 414 |
+
x = self.norm_pre(x)
|
| 415 |
+
else:
|
| 416 |
+
x = self.norm(x)
|
| 417 |
+
|
| 418 |
+
# All except cls token
|
| 419 |
+
x = x[:, 1:, :]
|
| 420 |
+
|
| 421 |
+
if (use_for_pretraining or bool_masked_pos is not None):
|
| 422 |
+
for i, x_symmetric in enumerate([x_symmetric_1, x_symmetric_2, x_symmetric_3, x_symmetric_4]):
|
| 423 |
+
x_symmetric += spatial_embedding
|
| 424 |
+
x_symmetric[:, 1:, :] += temporal_embedding
|
| 425 |
+
x_symmetric = self.pos_drop(x_symmetric)
|
| 426 |
+
for blk in self.blocks:
|
| 427 |
+
x_symmetric = blk(x_symmetric)
|
| 428 |
+
x_symmetric = self.norm_pre(x_symmetric)
|
| 429 |
+
# All except cls token
|
| 430 |
+
if i == 0:
|
| 431 |
+
x_symmetric_1 = x_symmetric[:, 1:, :]
|
| 432 |
+
elif i == 1:
|
| 433 |
+
x_symmetric_2 = x_symmetric[:, 1:, :]
|
| 434 |
+
elif i == 2:
|
| 435 |
+
x_symmetric_3 = x_symmetric[:, 1:, :]
|
| 436 |
+
else:
|
| 437 |
+
x_symmetric_4 = x_symmetric[:, 1:, :]
|
| 438 |
+
|
| 439 |
+
# ONLY in Pre-Training
|
| 440 |
+
if (use_for_pretraining or bool_masked_pos is not None):
|
| 441 |
+
|
| 442 |
+
logits = torch.stack([
|
| 443 |
+
# x1 heads
|
| 444 |
+
self.head_pre_1(x1[bool_masked_pos]),
|
| 445 |
+
self.head_pre_2(x1[bool_masked_pos]),
|
| 446 |
+
self.head_pre_3(x1[bool_masked_pos]),
|
| 447 |
+
self.head_pre_4(x1[bool_masked_pos]),
|
| 448 |
+
self.head_pre_5(x1[bool_masked_pos]),
|
| 449 |
+
self.head_pre_6(x1[bool_masked_pos]),
|
| 450 |
+
self.head_pre_7(x1[bool_masked_pos]),
|
| 451 |
+
self.head_pre_8(x1[bool_masked_pos]),
|
| 452 |
+
|
| 453 |
+
# x2 heads
|
| 454 |
+
self.head_pre_9(x2[bool_masked_pos]),
|
| 455 |
+
self.head_pre_10(x2[bool_masked_pos]),
|
| 456 |
+
self.head_pre_11(x2[bool_masked_pos]),
|
| 457 |
+
self.head_pre_12(x2[bool_masked_pos]),
|
| 458 |
+
self.head_pre_13(x2[bool_masked_pos]),
|
| 459 |
+
self.head_pre_14(x2[bool_masked_pos]),
|
| 460 |
+
self.head_pre_15(x2[bool_masked_pos]),
|
| 461 |
+
self.head_pre_16(x2[bool_masked_pos]),
|
| 462 |
+
|
| 463 |
+
# x3 heads
|
| 464 |
+
self.head_pre_17(x3[bool_masked_pos]),
|
| 465 |
+
self.head_pre_18(x3[bool_masked_pos]),
|
| 466 |
+
self.head_pre_19(x3[bool_masked_pos]),
|
| 467 |
+
self.head_pre_20(x3[bool_masked_pos]),
|
| 468 |
+
self.head_pre_21(x3[bool_masked_pos]),
|
| 469 |
+
self.head_pre_22(x3[bool_masked_pos]),
|
| 470 |
+
self.head_pre_23(x3[bool_masked_pos]),
|
| 471 |
+
self.head_pre_24(x3[bool_masked_pos]),
|
| 472 |
+
|
| 473 |
+
# x4 heads
|
| 474 |
+
self.head_pre_25(x4[bool_masked_pos]),
|
| 475 |
+
self.head_pre_26(x4[bool_masked_pos]),
|
| 476 |
+
self.head_pre_27(x4[bool_masked_pos]),
|
| 477 |
+
self.head_pre_28(x4[bool_masked_pos]),
|
| 478 |
+
self.head_pre_29(x4[bool_masked_pos]),
|
| 479 |
+
self.head_pre_30(x4[bool_masked_pos]),
|
| 480 |
+
self.head_pre_31(x4[bool_masked_pos]),
|
| 481 |
+
self.head_pre_32(x4[bool_masked_pos]),
|
| 482 |
+
], dim=0)
|
| 483 |
+
|
| 484 |
+
logits_symmetric = torch.stack([
|
| 485 |
+
# x_symmetric_1 heads
|
| 486 |
+
self.head_pre_1(x_symmetric_1[~bool_masked_pos]),
|
| 487 |
+
self.head_pre_2(x_symmetric_1[~bool_masked_pos]),
|
| 488 |
+
self.head_pre_3(x_symmetric_1[~bool_masked_pos]),
|
| 489 |
+
self.head_pre_4(x_symmetric_1[~bool_masked_pos]),
|
| 490 |
+
self.head_pre_5(x_symmetric_1[~bool_masked_pos]),
|
| 491 |
+
self.head_pre_6(x_symmetric_1[~bool_masked_pos]),
|
| 492 |
+
self.head_pre_7(x_symmetric_1[~bool_masked_pos]),
|
| 493 |
+
self.head_pre_8(x_symmetric_1[~bool_masked_pos]),
|
| 494 |
+
|
| 495 |
+
# x_symmetric_2 heads
|
| 496 |
+
self.head_pre_9(x_symmetric_2[~bool_masked_pos]),
|
| 497 |
+
self.head_pre_10(x_symmetric_2[~bool_masked_pos]),
|
| 498 |
+
self.head_pre_11(x_symmetric_2[~bool_masked_pos]),
|
| 499 |
+
self.head_pre_12(x_symmetric_2[~bool_masked_pos]),
|
| 500 |
+
self.head_pre_13(x_symmetric_2[~bool_masked_pos]),
|
| 501 |
+
self.head_pre_14(x_symmetric_2[~bool_masked_pos]),
|
| 502 |
+
self.head_pre_15(x_symmetric_2[~bool_masked_pos]),
|
| 503 |
+
self.head_pre_16(x_symmetric_2[~bool_masked_pos]),
|
| 504 |
+
|
| 505 |
+
# x_symmetric_3 heads
|
| 506 |
+
self.head_pre_17(x_symmetric_3[~bool_masked_pos]),
|
| 507 |
+
self.head_pre_18(x_symmetric_3[~bool_masked_pos]),
|
| 508 |
+
self.head_pre_19(x_symmetric_3[~bool_masked_pos]),
|
| 509 |
+
self.head_pre_20(x_symmetric_3[~bool_masked_pos]),
|
| 510 |
+
self.head_pre_21(x_symmetric_3[~bool_masked_pos]),
|
| 511 |
+
self.head_pre_22(x_symmetric_3[~bool_masked_pos]),
|
| 512 |
+
self.head_pre_23(x_symmetric_3[~bool_masked_pos]),
|
| 513 |
+
self.head_pre_24(x_symmetric_3[~bool_masked_pos]),
|
| 514 |
+
|
| 515 |
+
# x_symmetric_4 heads
|
| 516 |
+
self.head_pre_25(x_symmetric_4[~bool_masked_pos]),
|
| 517 |
+
self.head_pre_26(x_symmetric_4[~bool_masked_pos]),
|
| 518 |
+
self.head_pre_27(x_symmetric_4[~bool_masked_pos]),
|
| 519 |
+
self.head_pre_28(x_symmetric_4[~bool_masked_pos]),
|
| 520 |
+
self.head_pre_29(x_symmetric_4[~bool_masked_pos]),
|
| 521 |
+
self.head_pre_30(x_symmetric_4[~bool_masked_pos]),
|
| 522 |
+
self.head_pre_31(x_symmetric_4[~bool_masked_pos]),
|
| 523 |
+
self.head_pre_32(x_symmetric_4[~bool_masked_pos]),
|
| 524 |
+
], dim=0)
|
| 525 |
+
|
| 526 |
+
return logits, logits_symmetric
|
| 527 |
+
else:
|
| 528 |
+
# ONLY in RVQ
|
| 529 |
+
if return_patch_tokens:
|
| 530 |
+
if (self.use_as_encoder):
|
| 531 |
+
return self.head_1(self.fc_norm_1(x1)), self.head_2(self.fc_norm_2(x2)), self.head_3(self.fc_norm_3(x3)), self.head_4(self.fc_norm_4(x4)), _
|
| 532 |
+
else:
|
| 533 |
+
if (branch_idx==0):
|
| 534 |
+
return self.head_1(self.fc_norm_1(x)), _
|
| 535 |
+
elif (branch_idx==1):
|
| 536 |
+
return self.head_2(self.fc_norm_2(x)), _
|
| 537 |
+
elif (branch_idx==2):
|
| 538 |
+
return self.head_3(self.fc_norm_3(x)), _
|
| 539 |
+
elif (branch_idx==3):
|
| 540 |
+
return self.head_4(self.fc_norm_4(x)), _
|
| 541 |
+
else:
|
| 542 |
+
# ONLY in Fine-Tune
|
| 543 |
+
x = torch.concat([x1,x2,x3,x4], dim=-1)
|
| 544 |
+
return self.head(self.fc_norm(x.mean(1))), _
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
|
| 548 |
+
class NeuroRVQTokenizer(nn.Module):
|
| 549 |
+
"""
|
| 550 |
+
NeuroRVQ Tokenizer
|
| 551 |
+
"""
|
| 552 |
+
def __init__(self,
|
| 553 |
+
encoder_config,
|
| 554 |
+
decoder_config,
|
| 555 |
+
n_code,
|
| 556 |
+
code_dim,
|
| 557 |
+
decoder_out_dim
|
| 558 |
+
):
|
| 559 |
+
|
| 560 |
+
super().__init__()
|
| 561 |
+
self.patch_size = encoder_config['patch_size']
|
| 562 |
+
self.code_dim = code_dim
|
| 563 |
+
|
| 564 |
+
# Encoder layer of NeuroRVQFM
|
| 565 |
+
self.encoder = NeuroRVQFM(n_patches=encoder_config['n_patches'], patch_size=encoder_config['patch_size'],
|
| 566 |
+
in_chans=encoder_config['in_chans'], out_chans=encoder_config['out_chans_encoder'],
|
| 567 |
+
num_classes = encoder_config['num_classes'], embed_dim=encoder_config['embed_dim'],
|
| 568 |
+
depth=encoder_config['depth'], num_heads=encoder_config['num_heads'],
|
| 569 |
+
mlp_ratio=encoder_config['mlp_ratio'], qkv_bias=encoder_config['qkv_bias'],
|
| 570 |
+
qk_norm=partial(nn.LayerNorm, eps=1e-6), drop_rate=encoder_config['drop_rate'],
|
| 571 |
+
attn_drop_rate=encoder_config['attn_drop_rate'], drop_path_rate=encoder_config['drop_path_rate'],
|
| 572 |
+
init_values=encoder_config['init_values'], init_scale=encoder_config['init_scale'],
|
| 573 |
+
n_global_electrodes=encoder_config['n_global_electrodes'], vocab_size=n_code,
|
| 574 |
+
use_as_encoder=True, use_for_pretraining = False)
|
| 575 |
+
|
| 576 |
+
# Decoder layer of NeuroRVQFM
|
| 577 |
+
self.decoder = NeuroRVQFM(n_patches=decoder_config['n_patches'], patch_size=decoder_config['patch_size'],
|
| 578 |
+
in_chans=decoder_config['in_chans'], out_chans=0,
|
| 579 |
+
num_classes = decoder_config['num_classes'], embed_dim=decoder_config['embed_dim'],
|
| 580 |
+
depth=decoder_config['depth'], num_heads=decoder_config['num_heads'],
|
| 581 |
+
mlp_ratio=decoder_config['mlp_ratio'], qkv_bias=decoder_config['qkv_bias'],
|
| 582 |
+
qk_norm=partial(nn.LayerNorm, eps=1e-6), drop_rate=decoder_config['drop_rate'],
|
| 583 |
+
attn_drop_rate=decoder_config['attn_drop_rate'], drop_path_rate=decoder_config['drop_path_rate'],
|
| 584 |
+
init_values=decoder_config['init_values'], init_scale=decoder_config['init_scale'],
|
| 585 |
+
n_global_electrodes=decoder_config['n_global_electrodes'], vocab_size=n_code,
|
| 586 |
+
use_as_encoder=False, use_for_pretraining = False)
|
| 587 |
+
|
| 588 |
+
self.quantize_1 = ResidualVectorQuantization(num_quantizers = 8,
|
| 589 |
+
n_embed=n_code, embedding_dim=code_dim, beta=1.0, kmeans_init=True, decay=0.99,
|
| 590 |
+
)
|
| 591 |
+
self.quantize_2 = ResidualVectorQuantization(num_quantizers = 8,
|
| 592 |
+
n_embed=n_code, embedding_dim=code_dim, beta=1.0, kmeans_init=True, decay=0.99,
|
| 593 |
+
)
|
| 594 |
+
self.quantize_3 = ResidualVectorQuantization(num_quantizers = 8,
|
| 595 |
+
n_embed=n_code, embedding_dim=code_dim, beta=1.0, kmeans_init=True, decay=0.99,
|
| 596 |
+
)
|
| 597 |
+
self.quantize_4 = ResidualVectorQuantization(num_quantizers = 8,
|
| 598 |
+
n_embed=n_code, embedding_dim=code_dim, beta=1.0, kmeans_init=True, decay=0.99,
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
# Output dimension of the decoder layer
|
| 602 |
+
self.decoder_out_dim = decoder_out_dim
|
| 603 |
+
|
| 604 |
+
# Encoding head after the encoder transformer
|
| 605 |
+
self.encode_task_layer_1 = nn.Sequential(
|
| 606 |
+
nn.Linear(encoder_config['embed_dim'], encoder_config['embed_dim']),
|
| 607 |
+
nn.Tanh(),
|
| 608 |
+
nn.Linear(encoder_config['embed_dim'], code_dim)
|
| 609 |
+
)
|
| 610 |
+
self.encode_task_layer_2 = nn.Sequential(
|
| 611 |
+
nn.Linear(encoder_config['embed_dim'], encoder_config['embed_dim']),
|
| 612 |
+
nn.Tanh(),
|
| 613 |
+
nn.Linear(encoder_config['embed_dim'], code_dim)
|
| 614 |
+
)
|
| 615 |
+
self.encode_task_layer_3 = nn.Sequential(
|
| 616 |
+
nn.Linear(encoder_config['embed_dim'], encoder_config['embed_dim']),
|
| 617 |
+
nn.Tanh(),
|
| 618 |
+
nn.Linear(encoder_config['embed_dim'], code_dim)
|
| 619 |
+
)
|
| 620 |
+
self.encode_task_layer_4 = nn.Sequential(
|
| 621 |
+
nn.Linear(encoder_config['embed_dim'], encoder_config['embed_dim']),
|
| 622 |
+
nn.Tanh(),
|
| 623 |
+
nn.Linear(encoder_config['embed_dim'], code_dim)
|
| 624 |
+
)
|
| 625 |
+
self.encode_task_layer_1.apply(self._init_weights)
|
| 626 |
+
self.encode_task_layer_2.apply(self._init_weights)
|
| 627 |
+
self.encode_task_layer_3.apply(self._init_weights)
|
| 628 |
+
self.encode_task_layer_4.apply(self._init_weights)
|
| 629 |
+
|
| 630 |
+
# Decoding heads after the decoder transformer
|
| 631 |
+
self.decode_task_layer_amplitude = nn.Sequential(
|
| 632 |
+
nn.Linear(4*decoder_config['embed_dim'], decoder_config['embed_dim']),
|
| 633 |
+
nn.GELU(),
|
| 634 |
+
nn.Linear(decoder_config['embed_dim'], self.decoder_out_dim),
|
| 635 |
+
)
|
| 636 |
+
self.decode_task_layer_angle_sin = nn.Sequential(
|
| 637 |
+
nn.Linear(4*decoder_config['embed_dim'], decoder_config['embed_dim']),
|
| 638 |
+
nn.Tanh(),
|
| 639 |
+
nn.Linear(decoder_config['embed_dim'], self.decoder_out_dim),
|
| 640 |
+
nn.Tanh()
|
| 641 |
+
)
|
| 642 |
+
self.decode_task_layer_angle_cos = nn.Sequential(
|
| 643 |
+
nn.Linear(4*decoder_config['embed_dim'], decoder_config['embed_dim']),
|
| 644 |
+
nn.Tanh(),
|
| 645 |
+
nn.Linear(decoder_config['embed_dim'], self.decoder_out_dim),
|
| 646 |
+
nn.Tanh()
|
| 647 |
+
)
|
| 648 |
+
|
| 649 |
+
# Initialize model weights
|
| 650 |
+
self.decode_task_layer_amplitude.apply(self._init_weights)
|
| 651 |
+
self.decode_task_layer_angle_sin.apply(self._init_weights)
|
| 652 |
+
self.decode_task_layer_angle_cos.apply(self._init_weights)
|
| 653 |
+
|
| 654 |
+
# MSE loss function
|
| 655 |
+
self.loss_fn = F.mse_loss
|
| 656 |
+
|
| 657 |
+
# Function to initialize the weights of the network
|
| 658 |
+
def _init_weights(self, m):
|
| 659 |
+
if isinstance(m, nn.Linear):
|
| 660 |
+
trunc_normal_(m.weight, std=.02)
|
| 661 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 662 |
+
nn.init.constant_(m.bias, 0)
|
| 663 |
+
elif isinstance(m, nn.LayerNorm):
|
| 664 |
+
nn.init.constant_(m.bias, 0)
|
| 665 |
+
nn.init.constant_(m.weight, 1.0)
|
| 666 |
+
|
| 667 |
+
@torch.jit.ignore
|
| 668 |
+
def no_weight_decay(self):
|
| 669 |
+
return {'quantize.embedding.weight', 'decoder.cls_token', 'decoder.pos_embed', 'decoder.time_embed',
|
| 670 |
+
'encoder.cls_token', 'encoder.pos_embed', 'encoder.time_embed'}
|
| 671 |
+
|
| 672 |
+
def get_number_of_tokens(self):
|
| 673 |
+
return self.quantize.n_e
|
| 674 |
+
|
| 675 |
+
def get_tokens(self, data, temporal_embedding_ix, spatial_embedding_ix):
|
| 676 |
+
quantize, code_ind, loss, usage_ratios = self.encode(data, temporal_embedding_ix, spatial_embedding_ix)
|
| 677 |
+
# Convert [8, B*P] to [8, B, P]
|
| 678 |
+
code_inds = [code_ind_ix.view(8, data.shape[0], -1) for code_ind_ix in code_ind]
|
| 679 |
+
# Stack all codebooks [4, 8, B, P]
|
| 680 |
+
stacked_code_inds = torch.stack(code_inds, dim=0)
|
| 681 |
+
quantize_vecs = [rearrange(quantize_ix, 'b d a c -> b (a c) d').contiguous() for quantize_ix in quantize]
|
| 682 |
+
output = {}
|
| 683 |
+
output['token'] = stacked_code_inds
|
| 684 |
+
output['input_img'] = data
|
| 685 |
+
output['quantize'] = quantize_vecs
|
| 686 |
+
return output
|
| 687 |
+
|
| 688 |
+
def encode(self, x, temporal_embedding_ix, spatial_embedding_ix):
|
| 689 |
+
batch_size, n, a, t = x.shape
|
| 690 |
+
encoder_features_1, encoder_features_2, encoder_features_3, encoder_features_4, _ = self.encoder(x, temporal_embedding_ix=temporal_embedding_ix, spatial_embedding_ix=spatial_embedding_ix, return_patch_tokens=True)
|
| 691 |
+
|
| 692 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 693 |
+
to_quantizer_features_1 = self.encode_task_layer_1(encoder_features_1.type_as(self.encode_task_layer_1[-1].weight))
|
| 694 |
+
to_quantizer_features_2 = self.encode_task_layer_2(encoder_features_2.type_as(self.encode_task_layer_2[-1].weight))
|
| 695 |
+
to_quantizer_features_3 = self.encode_task_layer_3(encoder_features_3.type_as(self.encode_task_layer_3[-1].weight))
|
| 696 |
+
to_quantizer_features_4 = self.encode_task_layer_4(encoder_features_4.type_as(self.encode_task_layer_4[-1].weight))
|
| 697 |
+
|
| 698 |
+
N = to_quantizer_features_1.shape[1]
|
| 699 |
+
h, w = n, N // n
|
| 700 |
+
|
| 701 |
+
# reshape tokens to feature maps for patch embed in decoder
|
| 702 |
+
to_quantizer_features_1 = rearrange(to_quantizer_features_1, 'b (h w) c -> b c h w', h=h,
|
| 703 |
+
w=w).contiguous() # reshape for quantizer
|
| 704 |
+
quantize_1, code_ind_1, loss_1, usage_ratios_1 = self.quantize_1(to_quantizer_features_1)
|
| 705 |
+
|
| 706 |
+
to_quantizer_features_2 = rearrange(to_quantizer_features_2, 'b (h w) c -> b c h w', h=h,
|
| 707 |
+
w=w).contiguous() # reshape for quantizer
|
| 708 |
+
quantize_2, code_ind_2, loss_2, usage_ratios_2 = self.quantize_2(to_quantizer_features_2)
|
| 709 |
+
|
| 710 |
+
to_quantizer_features_3 = rearrange(to_quantizer_features_3, 'b (h w) c -> b c h w', h=h,
|
| 711 |
+
w=w).contiguous() # reshape for quantizer
|
| 712 |
+
quantize_3, code_ind_3, loss_3, usage_ratios_3 = self.quantize_3(to_quantizer_features_3)
|
| 713 |
+
|
| 714 |
+
to_quantizer_features_4 = rearrange(to_quantizer_features_4, 'b (h w) c -> b c h w', h=h,
|
| 715 |
+
w=w).contiguous() # reshape for quantizer
|
| 716 |
+
quantize_4, code_ind_4, loss_4, usage_ratios_4 = self.quantize_4(to_quantizer_features_4)
|
| 717 |
+
|
| 718 |
+
# Combine loss
|
| 719 |
+
loss = loss_1 + loss_2 + loss_3 + loss_4
|
| 720 |
+
|
| 721 |
+
return [quantize_1, quantize_2, quantize_3, quantize_4], [code_ind_1, code_ind_2, code_ind_3, code_ind_4], loss, [usage_ratios_1, usage_ratios_2, usage_ratios_3, usage_ratios_4]
|
| 722 |
+
|
| 723 |
+
def decode(self, quantize, temporal_embedding_ix, spatial_embedding_ix):
|
| 724 |
+
|
| 725 |
+
for i, quantize_i in enumerate(quantize):
|
| 726 |
+
if i == 0:
|
| 727 |
+
decoder_features_1, _ = self.decoder(quantize_i, temporal_embedding_ix=temporal_embedding_ix,
|
| 728 |
+
spatial_embedding_ix=spatial_embedding_ix, return_patch_tokens=True, branch_idx = 0)
|
| 729 |
+
elif i == 1:
|
| 730 |
+
decoder_features_2, _ = self.decoder(quantize_i, temporal_embedding_ix=temporal_embedding_ix,
|
| 731 |
+
spatial_embedding_ix=spatial_embedding_ix, return_patch_tokens=True, branch_idx = 1)
|
| 732 |
+
elif i == 2:
|
| 733 |
+
decoder_features_3, _ = self.decoder(quantize_i, temporal_embedding_ix=temporal_embedding_ix,
|
| 734 |
+
spatial_embedding_ix=spatial_embedding_ix, return_patch_tokens=True, branch_idx = 2)
|
| 735 |
+
else:
|
| 736 |
+
decoder_features_4, _ = self.decoder(quantize_i, temporal_embedding_ix=temporal_embedding_ix,
|
| 737 |
+
spatial_embedding_ix=spatial_embedding_ix, return_patch_tokens=True, branch_idx = 3)
|
| 738 |
+
decoder_features = torch.cat([decoder_features_1, decoder_features_2, decoder_features_3, decoder_features_4], dim=2)
|
| 739 |
+
|
| 740 |
+
# Reconstruct Amplitude, Sine and Cosine
|
| 741 |
+
rec_amplitude = self.decode_task_layer_amplitude(decoder_features)
|
| 742 |
+
rec_angle_sin = self.decode_task_layer_angle_sin(decoder_features)
|
| 743 |
+
rec_angle_cos = self.decode_task_layer_angle_cos(decoder_features)
|
| 744 |
+
|
| 745 |
+
return rec_amplitude, rec_angle_sin, rec_angle_cos
|
| 746 |
+
|
| 747 |
+
def get_codebook_indices(self, x, temporal_embedding_ix, spatial_embedding_ix):
|
| 748 |
+
return self.get_tokens(x, temporal_embedding_ix, spatial_embedding_ix)['token']
|
| 749 |
+
|
| 750 |
+
def calculate_phase_loss(self, rec_sin, target_sin, rec_cos, target_cos):
|
| 751 |
+
target_sin = rearrange(target_sin, 'b n a c -> b (n a) c').contiguous()
|
| 752 |
+
target_cos = rearrange(target_cos, 'b n a c -> b (n a) c').contiguous()
|
| 753 |
+
rec = torch.stack((rec_cos, rec_sin), dim=-1)
|
| 754 |
+
target = torch.stack((target_cos, target_sin), dim=-1)
|
| 755 |
+
# Cosine Similarity for direction and Enforcing Magnitude loss
|
| 756 |
+
phase_loss = 1.0 - F.cosine_similarity(rec, target, dim=-1).mean() + 0.1 * ((rec_sin**2 + rec_cos**2 - 1) ** 2).mean()
|
| 757 |
+
return phase_loss
|
| 758 |
+
|
| 759 |
+
def calculate_rec_loss(self, rec, target):
|
| 760 |
+
target = rearrange(target, 'b n a c -> b (n a) c').contiguous()
|
| 761 |
+
rec_loss = self.loss_fn(rec, target)
|
| 762 |
+
return rec_loss
|
| 763 |
+
|
| 764 |
+
def calculate_signal_rec_loss(self, rec, target):
|
| 765 |
+
target = rearrange(target, 'b n a c -> b (n a) c').contiguous()
|
| 766 |
+
rec = rearrange(rec, 'b n a c -> b (n a) c').contiguous()
|
| 767 |
+
mse = self.loss_fn(rec, target)
|
| 768 |
+
return mse
|
| 769 |
+
|
| 770 |
+
def std_norm(self, x):
|
| 771 |
+
mean = torch.mean(x, dim=(1, 2, 3), keepdim=True)
|
| 772 |
+
std = torch.sqrt(torch.var(x, dim=(1, 2, 3), keepdim=True).clamp(min=1e-8))
|
| 773 |
+
x = (x - mean) / std
|
| 774 |
+
return x, mean, std
|
| 775 |
+
|
| 776 |
+
def forward(self, x, temporal_embedding_ix, spatial_embedding_ix):
|
| 777 |
+
"""
|
| 778 |
+
x: shape [B, N, T]
|
| 779 |
+
"""
|
| 780 |
+
x = rearrange(x, 'B N (A T) -> B N A T', T=self.patch_size).contiguous()
|
| 781 |
+
x_fft = torch.fft.fft(x, dim=-1)
|
| 782 |
+
|
| 783 |
+
# Get the log ampltitude
|
| 784 |
+
amplitude = torch.abs(x_fft)
|
| 785 |
+
amplitude = torch.log1p(amplitude)
|
| 786 |
+
amplitude, amp_mean, amp_std = self.std_norm(amplitude)
|
| 787 |
+
|
| 788 |
+
# Get the sine / cosine of the phase
|
| 789 |
+
angle = torch.angle(x_fft)
|
| 790 |
+
sin_angle = torch.sin(angle)
|
| 791 |
+
cos_angle = torch.cos(angle)
|
| 792 |
+
|
| 793 |
+
# Encoding and Quantize
|
| 794 |
+
quantize, code_ind, code_loss, usage_ratios = self.encode(x, temporal_embedding_ix, spatial_embedding_ix)
|
| 795 |
+
|
| 796 |
+
# Decoding
|
| 797 |
+
xrec_amp, xrec_angle_sin, xrec_angle_cos = self.decode(quantize, temporal_embedding_ix, spatial_embedding_ix)
|
| 798 |
+
|
| 799 |
+
# Reconstruct raw signal from amplitude and sine / cosine
|
| 800 |
+
ustd_xrec = (rearrange(xrec_amp, 'B N (A T) -> B N A T', T=self.patch_size).contiguous() * amp_std) + amp_mean # unstandardize
|
| 801 |
+
ustd_xrec = torch.expm1(ustd_xrec)
|
| 802 |
+
ustd_xrec = rearrange(ustd_xrec, 'b n a c -> b (n a) c').contiguous()
|
| 803 |
+
xrec_signal = torch.real(inverse_fft_cos_sin(ustd_xrec, xrec_angle_sin, xrec_angle_cos))
|
| 804 |
+
|
| 805 |
+
# Standardize sample and Reconstructed signal for MSE
|
| 806 |
+
std_x, _, _ = self.std_norm(x)
|
| 807 |
+
std_xrec_signal, _, _ = self.std_norm(rearrange(xrec_signal, 'B N (A T) -> B N A T', T=self.patch_size).contiguous())
|
| 808 |
+
signal_rec_loss = self.calculate_signal_rec_loss(std_xrec_signal, std_x)
|
| 809 |
+
|
| 810 |
+
# Calculate losses from decoder
|
| 811 |
+
rec_amplitude_loss = self.calculate_rec_loss(xrec_amp, amplitude)
|
| 812 |
+
phase_loss = self.calculate_phase_loss(xrec_angle_sin, sin_angle, xrec_angle_cos, cos_angle)
|
| 813 |
+
|
| 814 |
+
# Total loss
|
| 815 |
+
loss = code_loss + rec_amplitude_loss + phase_loss + signal_rec_loss
|
| 816 |
+
|
| 817 |
+
std_x = std_x.view(std_x.size(0), -1, 1,std_x.size(-1)).squeeze(2)
|
| 818 |
+
std_xrec_signal = std_xrec_signal.squeeze(2)
|
| 819 |
+
|
| 820 |
+
return std_x, std_xrec_signal
|
| 821 |
+
|
NeuroRVQ/NeuroRVQ_modules.py
ADDED
|
@@ -0,0 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
import warnings
|
| 5 |
+
import os
|
| 6 |
+
from functools import partial
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
import sys
|
| 9 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 10 |
+
|
| 11 |
+
'''
|
| 12 |
+
Get dictionary for shared encoder and decoder configurations based on the yaml file params.
|
| 13 |
+
'''
|
| 14 |
+
def get_encoder_decoder_params(args):
|
| 15 |
+
config = dict(patch_size=args['patch_size'], n_patches=args['n_patches'],
|
| 16 |
+
n_global_electrodes=args['n_global_electrodes'],
|
| 17 |
+
embed_dim=args['embed_dim'], num_heads=args['num_heads_tokenizer'],
|
| 18 |
+
mlp_ratio=args['mlp_ratio_tokenizer'],
|
| 19 |
+
qkv_bias=args['qkv_bias_tokenizer'], drop_rate=args['drop_rate_tokenizer'],
|
| 20 |
+
attn_drop_rate=args['attn_drop_rate_tokenizer'], drop_path_rate=args['drop_path_rate_tokenizer'],
|
| 21 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6), init_values=args['init_values_tokenizer'],
|
| 22 |
+
init_scale=args['init_scale_tokenizer'])
|
| 23 |
+
|
| 24 |
+
encoder_config = config.copy()
|
| 25 |
+
encoder_config['in_chans'] = args['in_chans_encoder']
|
| 26 |
+
encoder_config['depth'] = args['depth_encoder']
|
| 27 |
+
encoder_config['num_classes'] = 0
|
| 28 |
+
encoder_config['out_chans_encoder'] = args['out_chans_encoder']
|
| 29 |
+
|
| 30 |
+
decoder_config = config.copy()
|
| 31 |
+
decoder_config['in_chans'] = args['code_dim']
|
| 32 |
+
decoder_config['depth'] = args['depth_decoder']
|
| 33 |
+
decoder_config['num_classes'] = 0
|
| 34 |
+
|
| 35 |
+
return encoder_config, decoder_config
|
| 36 |
+
|
| 37 |
+
'''
|
| 38 |
+
Code taken from: https://github.com/huggingface/pytorch-image-models/tree/v0.4.12/timm/models/layers
|
| 39 |
+
'''
|
| 40 |
+
def drop_path(x, drop_prob: float = 0., training: bool = False):
|
| 41 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 42 |
+
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
|
| 43 |
+
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
|
| 44 |
+
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
|
| 45 |
+
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
|
| 46 |
+
'survival rate' as the argument.
|
| 47 |
+
"""
|
| 48 |
+
if drop_prob == 0. or not training:
|
| 49 |
+
return x
|
| 50 |
+
keep_prob = 1 - drop_prob
|
| 51 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
|
| 52 |
+
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
|
| 53 |
+
random_tensor.floor_() # binarize
|
| 54 |
+
output = x.div(keep_prob) * random_tensor
|
| 55 |
+
return output
|
| 56 |
+
|
| 57 |
+
'''
|
| 58 |
+
Code taken from: https://github.com/huggingface/pytorch-image-models/tree/v0.4.12/timm/models/layers
|
| 59 |
+
'''
|
| 60 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 61 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 62 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 63 |
+
def norm_cdf(x):
|
| 64 |
+
# Computes standard normal cumulative distribution function
|
| 65 |
+
return (1. + math.erf(x / math.sqrt(2.))) / 2.
|
| 66 |
+
|
| 67 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 68 |
+
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 69 |
+
"The distribution of values may be incorrect.",
|
| 70 |
+
stacklevel=2)
|
| 71 |
+
|
| 72 |
+
with torch.no_grad():
|
| 73 |
+
# Values are generated by using a truncated uniform distribution and
|
| 74 |
+
# then using the inverse CDF for the normal distribution.
|
| 75 |
+
# Get upper and lower cdf values
|
| 76 |
+
l = norm_cdf((a - mean) / std)
|
| 77 |
+
u = norm_cdf((b - mean) / std)
|
| 78 |
+
|
| 79 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 80 |
+
# [2l-1, 2u-1].
|
| 81 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 82 |
+
|
| 83 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 84 |
+
# standard normal
|
| 85 |
+
tensor.erfinv_()
|
| 86 |
+
|
| 87 |
+
# Transform to proper mean, std
|
| 88 |
+
tensor.mul_(std * math.sqrt(2.))
|
| 89 |
+
tensor.add_(mean)
|
| 90 |
+
|
| 91 |
+
# Clamp to ensure it's in the proper range
|
| 92 |
+
tensor.clamp_(min=a, max=b)
|
| 93 |
+
return tensor
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
'''
|
| 97 |
+
Code taken from: https://github.com/huggingface/pytorch-image-models/tree/v0.4.12/timm/models/layers
|
| 98 |
+
'''
|
| 99 |
+
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
|
| 100 |
+
# type: (Tensor, float, float, float, float) -> Tensor
|
| 101 |
+
r"""Fills the input Tensor with values drawn from a truncated
|
| 102 |
+
normal distribution. The values are effectively drawn from the
|
| 103 |
+
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 104 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 105 |
+
the bounds. The method used for generating the random values works
|
| 106 |
+
best when :math:`a \leq \text{mean} \leq b`.
|
| 107 |
+
Args:
|
| 108 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 109 |
+
mean: the mean of the normal distribution
|
| 110 |
+
std: the standard deviation of the normal distribution
|
| 111 |
+
a: the minimum cutoff value
|
| 112 |
+
b: the maximum cutoff value
|
| 113 |
+
Examples:
|
| 114 |
+
>>> w = torch.empty(3, 5)
|
| 115 |
+
>>> nn.init.trunc_normal_(w)
|
| 116 |
+
"""
|
| 117 |
+
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
|
| 118 |
+
|
| 119 |
+
class DropPath(nn.Module):
|
| 120 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 121 |
+
"""
|
| 122 |
+
def __init__(self, drop_prob=None):
|
| 123 |
+
super(DropPath, self).__init__()
|
| 124 |
+
self.drop_prob = drop_prob
|
| 125 |
+
|
| 126 |
+
def forward(self, x):
|
| 127 |
+
return drop_path(x, self.drop_prob, self.training)
|
| 128 |
+
|
| 129 |
+
def extra_repr(self) -> str:
|
| 130 |
+
return 'p={}'.format(self.drop_prob)
|
| 131 |
+
|
| 132 |
+
class Mlp(nn.Module):
|
| 133 |
+
"""
|
| 134 |
+
MLP module of Transformer based on https://github.com/935963004/LaBraM/
|
| 135 |
+
"""
|
| 136 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 137 |
+
super().__init__()
|
| 138 |
+
out_features = out_features or in_features
|
| 139 |
+
hidden_features = hidden_features or in_features
|
| 140 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 141 |
+
self.act = act_layer()
|
| 142 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 143 |
+
self.drop = nn.Dropout(drop)
|
| 144 |
+
|
| 145 |
+
def forward(self, x):
|
| 146 |
+
x = self.fc1(x)
|
| 147 |
+
x = self.act(x)
|
| 148 |
+
x = self.fc2(x)
|
| 149 |
+
x = self.drop(x)
|
| 150 |
+
return x
|
| 151 |
+
|
| 152 |
+
class Attention(nn.Module):
|
| 153 |
+
"""
|
| 154 |
+
Attention module of Transformer based on https://github.com/935963004/LaBraM/
|
| 155 |
+
"""
|
| 156 |
+
def __init__(
|
| 157 |
+
self, dim, num_heads=8, qkv_bias=False, qk_norm=None, attn_drop=0., proj_drop=0., window_size=None):
|
| 158 |
+
super().__init__()
|
| 159 |
+
|
| 160 |
+
self.num_heads = num_heads
|
| 161 |
+
head_dim = dim // num_heads
|
| 162 |
+
all_head_dim = head_dim * self.num_heads
|
| 163 |
+
self.scale = head_dim ** -0.5
|
| 164 |
+
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
|
| 165 |
+
|
| 166 |
+
if qkv_bias:
|
| 167 |
+
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 168 |
+
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 169 |
+
else:
|
| 170 |
+
self.q_bias = None
|
| 171 |
+
self.v_bias = None
|
| 172 |
+
|
| 173 |
+
if qk_norm is not None:
|
| 174 |
+
self.q_norm = qk_norm(head_dim)
|
| 175 |
+
self.k_norm = qk_norm(head_dim)
|
| 176 |
+
else:
|
| 177 |
+
self.q_norm = None
|
| 178 |
+
self.k_norm = None
|
| 179 |
+
|
| 180 |
+
self.window_size = None
|
| 181 |
+
self.relative_position_bias_table = None
|
| 182 |
+
self.relative_position_index = None
|
| 183 |
+
|
| 184 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 185 |
+
self.proj = nn.Linear(all_head_dim, dim)
|
| 186 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 187 |
+
|
| 188 |
+
def forward(self, x, return_attention=False, return_qkv=False):
|
| 189 |
+
B, N, C = x.shape
|
| 190 |
+
|
| 191 |
+
if self.q_bias is not None:
|
| 192 |
+
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
|
| 193 |
+
else:
|
| 194 |
+
qkv_bias = None
|
| 195 |
+
|
| 196 |
+
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
|
| 197 |
+
|
| 198 |
+
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4) # (3, B, H, N, C)
|
| 199 |
+
|
| 200 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # (B, H, N, C)
|
| 201 |
+
if self.q_norm is not None:
|
| 202 |
+
q = self.q_norm(q).type_as(v)
|
| 203 |
+
if self.k_norm is not None:
|
| 204 |
+
k = self.k_norm(k).type_as(v)
|
| 205 |
+
|
| 206 |
+
q = q * self.scale
|
| 207 |
+
attn = (q @ k.transpose(-2, -1))
|
| 208 |
+
|
| 209 |
+
attn = attn.softmax(dim=-1)
|
| 210 |
+
attn = self.attn_drop(attn)
|
| 211 |
+
|
| 212 |
+
if return_attention:
|
| 213 |
+
return attn
|
| 214 |
+
|
| 215 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
|
| 216 |
+
x = self.proj(x)
|
| 217 |
+
x = self.proj_drop(x)
|
| 218 |
+
|
| 219 |
+
if return_qkv:
|
| 220 |
+
return x, qkv
|
| 221 |
+
|
| 222 |
+
return x
|
| 223 |
+
|
| 224 |
+
class Block(nn.Module):
|
| 225 |
+
"""
|
| 226 |
+
Block of Transformer based on https://github.com/935963004/LaBraM/
|
| 227 |
+
"""
|
| 228 |
+
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_norm=None, drop=0., attn_drop=0.,
|
| 229 |
+
drop_path=0., init_values=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm,
|
| 230 |
+
window_size=None, attn_head_dim=None):
|
| 231 |
+
super().__init__()
|
| 232 |
+
self.norm1 = norm_layer(dim)
|
| 233 |
+
self.attn = Attention(
|
| 234 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_norm=qk_norm, attn_drop=attn_drop,
|
| 235 |
+
proj_drop=drop, window_size=window_size)
|
| 236 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 237 |
+
self.norm2 = norm_layer(dim)
|
| 238 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 239 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 240 |
+
|
| 241 |
+
if init_values > 0:
|
| 242 |
+
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
|
| 243 |
+
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
|
| 244 |
+
else:
|
| 245 |
+
self.gamma_1, self.gamma_2 = None, None
|
| 246 |
+
|
| 247 |
+
def forward(self, x):
|
| 248 |
+
if self.gamma_1 is None:
|
| 249 |
+
x = x + self.drop_path(self.attn(self.norm1(x)))
|
| 250 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 251 |
+
else:
|
| 252 |
+
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
|
| 253 |
+
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
|
| 254 |
+
return x
|
NeuroRVQ/RVQ.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Residual Vector Quantization Implementation.
|
| 3 |
+
Follows Algorithm 1. in https://arxiv.org/pdf/2107.03312.pdf
|
| 4 |
+
'''
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from norm_ema_quantizer import NormEMAVectorQuantizer
|
| 10 |
+
|
| 11 |
+
class ResidualVectorQuantization(nn.Module):
|
| 12 |
+
def __init__(self, *, num_quantizers, **kwargs):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.layers = nn.ModuleList(
|
| 15 |
+
[NormEMAVectorQuantizer(**kwargs) for _ in range(num_quantizers)]
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
quantized_out = torch.zeros_like(x)
|
| 20 |
+
residual = x
|
| 21 |
+
|
| 22 |
+
all_losses = []
|
| 23 |
+
all_indices = []
|
| 24 |
+
n_q = len(self.layers)
|
| 25 |
+
|
| 26 |
+
usage_ratios = [] # Track usage per quantizer
|
| 27 |
+
total_codes = self.layers[0].num_tokens
|
| 28 |
+
|
| 29 |
+
for layer in self.layers[:n_q]:
|
| 30 |
+
quantized, loss, indices = layer(residual)
|
| 31 |
+
residual = residual - quantized
|
| 32 |
+
quantized_out = quantized_out + quantized
|
| 33 |
+
# Auxilatory Loss
|
| 34 |
+
loss = loss + 0.4 * F.mse_loss(quantized, residual.detach())
|
| 35 |
+
|
| 36 |
+
all_indices.append(indices)
|
| 37 |
+
all_losses.append(loss)
|
| 38 |
+
|
| 39 |
+
# --- Codebook usage tracking ---
|
| 40 |
+
unique_codes = torch.unique(indices)
|
| 41 |
+
usage_ratio = unique_codes.numel() / total_codes
|
| 42 |
+
usage_ratios.append(float(usage_ratio))
|
| 43 |
+
|
| 44 |
+
out_losses, out_indices = map(torch.stack, (all_losses, all_indices))
|
| 45 |
+
out_losses = out_losses.mean()
|
| 46 |
+
|
| 47 |
+
return quantized_out, out_indices, out_losses, usage_ratios
|
| 48 |
+
|
| 49 |
+
def encode(self, x):
|
| 50 |
+
residual = x
|
| 51 |
+
all_indices = []
|
| 52 |
+
n_q = len(self.layers)
|
| 53 |
+
for layer in self.layers[:n_q]:
|
| 54 |
+
indices = layer.encode(residual)
|
| 55 |
+
quantized = layer.decode(indices)
|
| 56 |
+
residual = residual - quantized
|
| 57 |
+
all_indices.append(indices)
|
| 58 |
+
out_indices = torch.stack(all_indices)
|
| 59 |
+
return out_indices
|
| 60 |
+
|
| 61 |
+
def decode(self, q_indices):
|
| 62 |
+
quantized_out = torch.tensor(0.0, device=q_indices.device)
|
| 63 |
+
for i, indices in enumerate(q_indices):
|
| 64 |
+
layer = self.layers[i]
|
| 65 |
+
quantized = layer.decode(indices)
|
| 66 |
+
quantized_out = quantized_out + quantized
|
| 67 |
+
return quantized_out
|
NeuroRVQ/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .NeuroRVQ import NeuroRVQTokenizer
|
| 2 |
+
from .NeuroRVQ import NeuroRVQFM
|
NeuroRVQ/norm_ema_quantizer.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
This file is based on LaBraM, BEiT-v2, timm, DeiT, and DINO code bases
|
| 3 |
+
https://github.com/935963004/LaBraM/blob/main/norm_ema_quantizer.py
|
| 4 |
+
https://github.com/microsoft/unilm/tree/master/beitv2
|
| 5 |
+
https://github.com/rwightman/pytorch-image-models/tree/master/timm
|
| 6 |
+
https://github.com/facebookresearch/deit/
|
| 7 |
+
https://github.com/facebookresearch/dino
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
import torch.distributed as distributed
|
| 14 |
+
from einops import rearrange, repeat
|
| 15 |
+
|
| 16 |
+
def l2norm(t):
|
| 17 |
+
return F.normalize(t, p = 2, dim = -1)
|
| 18 |
+
|
| 19 |
+
def ema_inplace(moving_avg, new, decay):
|
| 20 |
+
moving_avg.data.mul_(decay).add_(new, alpha = (1 - decay))
|
| 21 |
+
|
| 22 |
+
def sample_vectors(samples, num):
|
| 23 |
+
num_samples, device = samples.shape[0], samples.device
|
| 24 |
+
|
| 25 |
+
if num_samples >= num:
|
| 26 |
+
indices = torch.randperm(num_samples, device = device)[:num]
|
| 27 |
+
else:
|
| 28 |
+
indices = torch.randint(0, num_samples, (num,), device = device)
|
| 29 |
+
|
| 30 |
+
return samples[indices]
|
| 31 |
+
|
| 32 |
+
def kmeans(samples, num_clusters, num_iters = 10, use_cosine_sim = False):
|
| 33 |
+
dim, dtype, device = samples.shape[-1], samples.dtype, samples.device
|
| 34 |
+
|
| 35 |
+
means = sample_vectors(samples, num_clusters)
|
| 36 |
+
|
| 37 |
+
for _ in range(num_iters):
|
| 38 |
+
if use_cosine_sim:
|
| 39 |
+
dists = samples @ means.t()
|
| 40 |
+
else:
|
| 41 |
+
diffs = rearrange(samples, 'n d -> n () d') \
|
| 42 |
+
- rearrange(means, 'c d -> () c d')
|
| 43 |
+
dists = -(diffs ** 2).sum(dim = -1)
|
| 44 |
+
|
| 45 |
+
buckets = dists.max(dim = -1).indices
|
| 46 |
+
bins = torch.bincount(buckets, minlength = num_clusters)
|
| 47 |
+
zero_mask = bins == 0
|
| 48 |
+
bins_min_clamped = bins.masked_fill(zero_mask, 1)
|
| 49 |
+
|
| 50 |
+
new_means = buckets.new_zeros(num_clusters, dim, dtype = dtype)
|
| 51 |
+
new_means.scatter_add_(0, repeat(buckets, 'n -> n d', d = dim), samples)
|
| 52 |
+
new_means = new_means / bins_min_clamped[..., None]
|
| 53 |
+
|
| 54 |
+
if use_cosine_sim:
|
| 55 |
+
new_means = l2norm(new_means)
|
| 56 |
+
|
| 57 |
+
means = torch.where(zero_mask[..., None], means, new_means)
|
| 58 |
+
|
| 59 |
+
return means, bins
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class EmbeddingEMA(nn.Module):
|
| 63 |
+
def __init__(self, num_tokens, codebook_dim, decay=0.99, eps=1e-5, kmeans_init=True, codebook_init_path=''):
|
| 64 |
+
super().__init__()
|
| 65 |
+
self.num_tokens = num_tokens
|
| 66 |
+
self.codebook_dim = codebook_dim
|
| 67 |
+
self.decay = decay
|
| 68 |
+
self.eps = eps
|
| 69 |
+
if codebook_init_path == '':
|
| 70 |
+
if not kmeans_init:
|
| 71 |
+
weight = torch.randn(num_tokens, codebook_dim)
|
| 72 |
+
weight = l2norm(weight)
|
| 73 |
+
else:
|
| 74 |
+
weight = torch.zeros(num_tokens, codebook_dim)
|
| 75 |
+
self.register_buffer('initted', torch.Tensor([not kmeans_init]))
|
| 76 |
+
else:
|
| 77 |
+
print(f"load init codebook weight from {codebook_init_path}")
|
| 78 |
+
codebook_ckpt_weight = torch.load(codebook_init_path, map_location='cpu')
|
| 79 |
+
weight = codebook_ckpt_weight.clone()
|
| 80 |
+
self.register_buffer('initted', torch.Tensor([True]))
|
| 81 |
+
|
| 82 |
+
self.weight = nn.Parameter(weight, requires_grad = False)
|
| 83 |
+
self.cluster_size = nn.Parameter(torch.zeros(num_tokens), requires_grad = False)
|
| 84 |
+
self.embed_avg = nn.Parameter(weight.clone(), requires_grad = False)
|
| 85 |
+
# self.register_buffer('initted', torch.Tensor([not kmeans_init]))
|
| 86 |
+
self.update = True
|
| 87 |
+
|
| 88 |
+
@torch.jit.ignore
|
| 89 |
+
def init_embed_(self, data):
|
| 90 |
+
if self.initted:
|
| 91 |
+
return
|
| 92 |
+
# print("Performing Kmeans init for codebook")
|
| 93 |
+
embed, cluster_size = kmeans(data, self.num_tokens, 10, use_cosine_sim = True)
|
| 94 |
+
self.weight.data.copy_(embed)
|
| 95 |
+
self.cluster_size.data.copy_(cluster_size)
|
| 96 |
+
self.initted.data.copy_(torch.Tensor([True]))
|
| 97 |
+
|
| 98 |
+
def forward(self, embed_id):
|
| 99 |
+
return F.embedding(embed_id, self.weight)
|
| 100 |
+
|
| 101 |
+
def cluster_size_ema_update(self, new_cluster_size):
|
| 102 |
+
self.cluster_size.data.mul_(self.decay).add_(new_cluster_size, alpha=1 - self.decay)
|
| 103 |
+
|
| 104 |
+
def embed_avg_ema_update(self, new_embed_avg):
|
| 105 |
+
self.embed_avg.data.mul_(self.decay).add_(new_embed_avg, alpha=1 - self.decay)
|
| 106 |
+
|
| 107 |
+
def weight_update(self, num_tokens):
|
| 108 |
+
n = self.cluster_size.sum()
|
| 109 |
+
smoothed_cluster_size = (
|
| 110 |
+
(self.cluster_size + self.eps) / (n + num_tokens * self.eps) * n
|
| 111 |
+
)
|
| 112 |
+
#normalize embedding average with smoothed cluster size
|
| 113 |
+
embed_normalized = self.embed_avg / smoothed_cluster_size.unsqueeze(1)
|
| 114 |
+
# embed_normalized = l2norm(self.embed_avg / smoothed_cluster_size.unsqueeze(1))
|
| 115 |
+
self.weight.data.copy_(embed_normalized)
|
| 116 |
+
|
| 117 |
+
def norm_ema_inplace(moving_avg, new, decay):
|
| 118 |
+
moving_avg.data.mul_(decay).add_(new, alpha = (1 - decay))
|
| 119 |
+
moving_avg.data.copy_(l2norm(moving_avg.data))
|
| 120 |
+
|
| 121 |
+
class NormEMAVectorQuantizer(nn.Module):
|
| 122 |
+
def __init__(self, n_embed, embedding_dim, beta, decay=0.99, eps=1e-5,
|
| 123 |
+
statistic_code_usage=True, kmeans_init=False, codebook_init_path=''):
|
| 124 |
+
super().__init__()
|
| 125 |
+
self.codebook_dim = embedding_dim
|
| 126 |
+
self.num_tokens = n_embed
|
| 127 |
+
self.beta = beta
|
| 128 |
+
self.decay = decay
|
| 129 |
+
|
| 130 |
+
# learnable = True if orthogonal_reg_weight > 0 else False
|
| 131 |
+
self.embedding = EmbeddingEMA(self.num_tokens, self.codebook_dim, decay, eps, kmeans_init, codebook_init_path)
|
| 132 |
+
|
| 133 |
+
self.statistic_code_usage = statistic_code_usage
|
| 134 |
+
if statistic_code_usage:
|
| 135 |
+
self.register_buffer('cluster_size', torch.zeros(n_embed))
|
| 136 |
+
if distributed.is_available() and distributed.is_initialized():
|
| 137 |
+
print("ddp is enable, so use ddp_reduce to sync the statistic_code_usage for each gpu!")
|
| 138 |
+
self.all_reduce_fn = distributed.all_reduce
|
| 139 |
+
else:
|
| 140 |
+
self.all_reduce_fn = nn.Identity()
|
| 141 |
+
|
| 142 |
+
def reset_cluster_size(self, device):
|
| 143 |
+
if self.statistic_code_usage:
|
| 144 |
+
self.register_buffer('cluster_size', torch.zeros(self.num_tokens))
|
| 145 |
+
self.cluster_size = self.cluster_size.to(device)
|
| 146 |
+
|
| 147 |
+
def forward(self, z):
|
| 148 |
+
# reshape z -> (batch, height, width, channel) and flatten
|
| 149 |
+
#z, 'b c h w -> b h w c'
|
| 150 |
+
z = rearrange(z, 'b c h w -> b h w c')
|
| 151 |
+
z = l2norm(z)
|
| 152 |
+
z_flattened = z.reshape(-1, self.codebook_dim)
|
| 153 |
+
self.embedding.init_embed_(z_flattened)
|
| 154 |
+
|
| 155 |
+
d = z_flattened.pow(2).sum(dim=1, keepdim=True) + \
|
| 156 |
+
self.embedding.weight.pow(2).sum(dim=1) - 2 * \
|
| 157 |
+
torch.einsum('bd,nd->bn', z_flattened, self.embedding.weight) # 'n d -> d n'
|
| 158 |
+
|
| 159 |
+
encoding_indices = torch.argmin(d, dim=1)
|
| 160 |
+
|
| 161 |
+
z_q = self.embedding(encoding_indices).view(z.shape)
|
| 162 |
+
|
| 163 |
+
encodings = F.one_hot(encoding_indices, self.num_tokens).type(z.dtype)
|
| 164 |
+
|
| 165 |
+
if not self.training:
|
| 166 |
+
with torch.no_grad():
|
| 167 |
+
cluster_size = encodings.sum(0)
|
| 168 |
+
self.all_reduce_fn(cluster_size)
|
| 169 |
+
ema_inplace(self.cluster_size, cluster_size, self.decay)
|
| 170 |
+
|
| 171 |
+
if self.training and self.embedding.update:
|
| 172 |
+
#EMA cluster size
|
| 173 |
+
|
| 174 |
+
bins = encodings.sum(0)
|
| 175 |
+
self.all_reduce_fn(bins)
|
| 176 |
+
|
| 177 |
+
# self.embedding.cluster_size_ema_update(bins)
|
| 178 |
+
ema_inplace(self.cluster_size, bins, self.decay)
|
| 179 |
+
|
| 180 |
+
zero_mask = (bins == 0)
|
| 181 |
+
bins = bins.masked_fill(zero_mask, 1.)
|
| 182 |
+
|
| 183 |
+
embed_sum = z_flattened.t() @ encodings
|
| 184 |
+
self.all_reduce_fn(embed_sum)
|
| 185 |
+
|
| 186 |
+
embed_normalized = (embed_sum / bins.unsqueeze(0)).t()
|
| 187 |
+
embed_normalized = l2norm(embed_normalized)
|
| 188 |
+
|
| 189 |
+
embed_normalized = torch.where(zero_mask[..., None], self.embedding.weight,
|
| 190 |
+
embed_normalized)
|
| 191 |
+
|
| 192 |
+
norm_ema_inplace(self.embedding.weight, embed_normalized, self.decay)
|
| 193 |
+
|
| 194 |
+
# compute loss for embedding
|
| 195 |
+
loss = self.beta * F.mse_loss(z_q.detach(), z)
|
| 196 |
+
|
| 197 |
+
# preserve gradients
|
| 198 |
+
z_q = z + (z_q - z).detach()
|
| 199 |
+
|
| 200 |
+
# reshape back to match original input shape
|
| 201 |
+
#z_q, 'b h w c -> b c h w'
|
| 202 |
+
z_q = rearrange(z_q, 'b h w c -> b c h w')
|
| 203 |
+
return z_q, loss, encoding_indices
|
| 204 |
+
|
README.md
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
<img src="images/banner.png" width="600">
|
| 4 |
+
|
| 5 |
+
# 🧠NeuroRVQ: Multi-Scale EEG Tokenization for Generative Large Brainwave Models
|
| 6 |
+
|
| 7 |
+
<a href='https://arxiv.org/abs/2510.13068'><img src='https://img.shields.io/badge/Paper-arXiv-red'></a>
|
| 8 |
+
<a href=''><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-orange'></a>
|
| 9 |
+
|
| 10 |
+
[Konstantinos Barmpas](https://www.barmpas.com)<sup>1,2</sup>   [Na Lee](https://www.linkedin.com/in/na-lee-57777387/)<sup>1,2</sup>   [Alexandros Koliousis](https://akoliousis.com)<sup>3</sup>
|
| 11 |
+
|
| 12 |
+
[Yannis Panagakis](http://users.uoa.gr/~yannisp/)<sup>2,4,5</sup>   [Dimitrios Adamos](https://profiles.imperial.ac.uk/d.adamos)<sup>1,2</sup>   [Nikolaos Laskaris](https://people.auth.gr/laskaris/?lang=en)<sup>2,6</sup>   [Stefanos Zafeiriou](https://profiles.imperial.ac.uk/s.zafeiriou)<sup>1,2</sup>
|
| 13 |
+
|
| 14 |
+
<sup>1</sup>Imperial College London, United Kingdom <br>
|
| 15 |
+
<sup>2</sup>Cogitat, United Kingdom <br>
|
| 16 |
+
<sup>3</sup>Northeastern University London, United Kingdom <br>
|
| 17 |
+
<sup>4</sup>National and Kapodistrian University of Athens, Greece <br>
|
| 18 |
+
<sup>5</sup>Archimedes Research Unit, Greece <br>
|
| 19 |
+
<sup>6</sup>Aristotle University of Thessaloniki, Greece
|
| 20 |
+
|
| 21 |
+
This is the official implementation of **NeuroRVQ**, a foundation model for biosignals powered by a state-of-the-art biosignal tokenizer
|
| 22 |
+
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
## 🌟 Overview
|
| 26 |
+
|
| 27 |
+
**NeuroRVQ Tokenizer** is a specialized network designed to convert raw biosignals into a sequence of compact and informative neural tokens. This transformation reduces the inherently high-dimensional and noisy nature of biosginals into a structured lower-dimensional representation that preserves essential temporal–spectral patterns. In doing so, the tokenizer provides a kind of "neural grammar" for neural activity. The input multi-variate timeseries is first segmented into patches. These patches are encoded by the multi-scale temporal encoder, that captures features in multiple resolutions and are then combined via the transfromer encoder. For each scale, RVQ codebooks discretize the embeddings into a sequence of neural tokens. Finally, these tokens are combined and passed through the tokenizer decoder to reconstruct the input patches using the Fourier spectrum.
|
| 28 |
+
|
| 29 |
+
**NeuroRVQ Foundation Model** is a scalable foundation model that operates on the tokenized representation. By working at the token level rather than raw signals, this model can better capture long-range dependencies, learn abstract neural dynamics and enable efficient pretraining across diverse EEG datasets. The model leverages the learned codebooks from the tokenizer stage and is trained using a masked-token prediction strategy, where a subset of input patches is randomly masked. This objective encourages the network to infer missing tokens from their surrounding context.
|
| 30 |
+
|
| 31 |
+
## Model and Modalities
|
| 32 |
+
|
| 33 |
+
| Modality | Support |
|
| 34 |
+
| :--- | :--- |
|
| 35 |
+
| **EEG** | ✅ |
|
| 36 |
+
| **EMG** | ✅ |
|
| 37 |
+
| **ECG** | ✅ |
|
| 38 |
+
|
| 39 |
+
| Model Version | Parameters | Modality | Trained Models <a href=''><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-orange'></a> |
|
| 40 |
+
| :--- | :--- | :--- | :--- |
|
| 41 |
+
| **NeuroRVQ-EEG-tokenizer-v1** | 76 Million | EEG | NeuroRVQ_EEG_tokenizer_v1.pt |
|
| 42 |
+
| **NeuroRVQ-EEG-foundation-model-v1** | 6 Million | EEG | NeuroRVQ_EEG_foundation_model_v1.pt |
|
| 43 |
+
| **NeuroRVQ-EMG-tokenizer-v1** | - | EMG | "To be released soon..." |
|
| 44 |
+
| **NeuroRVQ-EMG-foundation-model-v1** | - | EMG | "Training in Progress..." |
|
| 45 |
+
| **NeuroRVQ-ECG-tokenizer-v1** | - | ECG | "To be released soon..." |
|
| 46 |
+
| **NeuroRVQ-ECG-foundation-model-v1** | - | ECG | "Training in Progress..." |
|
| 47 |
+
|
| 48 |
+
## Tokenization / Reconstruction Capabilities
|
| 49 |
+
|
| 50 |
+
| EEG | ECG | EMG |
|
| 51 |
+
|:---:|:---:|:---:|
|
| 52 |
+
| <img src="images/eeg.png" width="300"/> | <img src="images/ecg.png" width="300"/> | <img src="images/emg.png" width="350"/> |
|
| 53 |
+
|
| 54 |
+
## Downstream Performance
|
| 55 |
+
|
| 56 |
+
### EEG
|
| 57 |
+
|
| 58 |
+
| Model | Motor | ERP | Memory | Sleep* | Eyes | Mean | Size |
|
| 59 |
+
|-----------|-------|------|---------|---------|-------|--------|-------|
|
| 60 |
+
| NeuroGPT | <u>0.682±0.083</u> | 0.757±0.048 | **0.597±0.029** | <u>0.674±0.033</u> | 0.827±0.036 | <u>0.707±0.046</u> | 79.5M |
|
| 61 |
+
| CBraMod | 0.614±0.104 | 0.777±0.052 | <u>0.574±0.038</u> | 0.635±0.041 | <u>0.839±0.041</u> | 0.688±0.055 | 4.9M |
|
| 62 |
+
| BIOT | 0.443±0.079 | 0.500±0.000 | 0.510±0.018 | -- | 0.763±0.049 | -- | 3.2M |
|
| 63 |
+
| MIRepNet | 0.689±0.086 | -- | -- | -- | -- | -- | -- |
|
| 64 |
+
| LaBraM | 0.630±0.076 | <u>0.822±0.040</u> | 0.526±0.026 | 0.652±0.037 | 0.799±0.047 | 0.686±0.045 | 5.8M |
|
| 65 |
+
| EEGPT | 0.313±0.035 | 0.668±0.146 | 0.520±0.017 | 0.634±0.044 | 0.797±0.037 | 0.587±0.056 | 25.7M |
|
| 66 |
+
| **NeuroRVQ** | **0.700±0.073** | **0.876±0.033** | <u>0.574±0.027</u> | **0.728±0.028** | **0.869±0.026** | **0.749±0.037** | 5.9M |
|
| 67 |
+
|
| 68 |
+
We used the benchmark presented in IEEE MLSP 2025 Paper [Assessing the Capabilities of Large Brainwave Foundation Models](https://ieeexplore.ieee.org/document/11204282).
|
| 69 |
+
|
| 70 |
+
#### About the Benchmark
|
| 71 |
+
Over the last decade, deep learning models have been widely used for automatic feature extraction and classification in various Brain-Computer Interface (BCI) tasks. However, their performance and generalization capabilities are often not adequately assessed, as these models are frequently trained and tested under flawed setups and / or influenced by spurious correlations. Recently, these limitations have also been observed in the training and evaluation of Large Brainwave Foundation Models (LBMs). In this work, we employ causal reasoning and careful consideration for task-discriminative artifacts in various EEG datasets covering diverse BCI paradigms and propose a benchmarking protocol to properly evaluate the decoding performance and generalization capabilities of LBMs. Utilising a subject-independent cross-validation approach for each curated benchmark dataset, we showcase that LBMs achieve marginal performance gains over conventional deep learning baselines.
|
| 72 |
+
|
| 73 |
+
[Open-Source Benchmark Code](https://github.com/dykestra/EEG-Benchmarking)
|
| 74 |
+
|
| 75 |
+
## Installation
|
| 76 |
+
```bash
|
| 77 |
+
conda create -n neurorvq python=3.10
|
| 78 |
+
conda activate neurorvq
|
| 79 |
+
|
| 80 |
+
# Install requirements
|
| 81 |
+
pip install -r requirements.txt
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
## Download Models
|
| 85 |
+
The models and the sample biosignal for reconstruction demos can be downloaded manually from [HuggingFace]() or using python:
|
| 86 |
+
```python
|
| 87 |
+
from huggingface_hub import hf_hub_download
|
| 88 |
+
|
| 89 |
+
hf_hub_download(repo_id="", filename="pretrained_models/tokenizers/NeuroRVQ_EEG_tokenizer_v1.pt", local_dir="./pretrained_models/tokenizers")
|
| 90 |
+
hf_hub_download(repo_id="", filename="pretrained_models/foundation_models/NeuroRVQ_EEG_foundation_model_v1.pt", local_dir="./pretrained_models/foundation_models")
|
| 91 |
+
hf_hub_download(repo_id="", filename="example_files/eeg_sample/example_eeg_file.xdf", local_dir="./example_files/eeg_sample")
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## Model Loading / Usage
|
| 95 |
+
|
| 96 |
+
Load tokenizer and see reconstruction results. Example for EEG tokenizer:
|
| 97 |
+
```python
|
| 98 |
+
|
| 99 |
+
from inference.run.NeuroRVQ_EEG_tokenizer_example import load_neurorqv_tokenizer
|
| 100 |
+
|
| 101 |
+
# Set run_example=True and plot_results=True to see reconstruction results
|
| 102 |
+
# Checkout the load_neurorqv_tokenizer() function to load and use tokenizer
|
| 103 |
+
|
| 104 |
+
load_neurorqv_tokenizer(run_example=True, plot_results=True, verbose=True,
|
| 105 |
+
model_path='./pretrained_models/tokenizers/NeuroRVQ_EEG_tokenizer_v1.pt')
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
Load foundation model and see an example for fine-tuning. Example for EEG foundation model:
|
| 109 |
+
```python
|
| 110 |
+
|
| 111 |
+
from inference.run.NeuroRVQ_EEG_FM_example import load_neurorqv_fm
|
| 112 |
+
|
| 113 |
+
# Checkout the load_neurorqv_fm() function with fine_tuning=False to see the correct model loading
|
| 114 |
+
# See the instructions in data.py for your custom dataset before setting fine_tuning=True
|
| 115 |
+
|
| 116 |
+
load_neurorqv_fm(fine_tuning=False, verbose=True,
|
| 117 |
+
model_path = './pretrained_models/foundation_models/NeuroRVQ_EEG_foundation_model_v1.pt')
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
## Citation
|
| 121 |
+
```
|
| 122 |
+
@misc{neurorvq,
|
| 123 |
+
title={NeuroRVQ: Multi-Scale EEG Tokenization for Generative Large Brainwave Models},
|
| 124 |
+
author={Konstantinos Barmpas and Na Lee and Alexandros Koliousis and Yannis Panagakis and Dimitrios A. Adamos and Nikolaos Laskaris and Stefanos Zafeiriou},
|
| 125 |
+
year={2025},
|
| 126 |
+
eprint={2510.13068},
|
| 127 |
+
archivePrefix={arXiv},
|
| 128 |
+
primaryClass={cs.LG},
|
| 129 |
+
url={https://arxiv.org/abs/2510.13068},
|
| 130 |
+
}
|
| 131 |
+
```
|
| 132 |
+
|
example_files/eeg_sample/example_eeg_file.xdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5a94b2b99371a32ecc7386ef5eb84555079616609c45fbb50ffe1a3b90c19ba3
|
| 3 |
+
size 125751622
|
fine_tuning/NeuroRVQ_EEG_FM_FineTuning.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from inference.modules.NeuroRVQ_EEG_tokenizer_inference_modules import ch_names_global, create_embedding_ix, check_model_eval_mode
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from sklearn.metrics import accuracy_score, balanced_accuracy_score
|
| 6 |
+
from torch.utils.data import DataLoader
|
| 7 |
+
import warnings
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
def get_class_weights(y, n_cls):
|
| 11 |
+
y = torch.Tensor(y)
|
| 12 |
+
class_weights = torch.unique(y, return_counts=True)[1]
|
| 13 |
+
class_weights = 1 / class_weights
|
| 14 |
+
class_weights = class_weights / class_weights.sum()
|
| 15 |
+
class_weights = class_weights * len(torch.unique(y)) # (n_classes,)
|
| 16 |
+
if len(class_weights) < n_cls:
|
| 17 |
+
tmp = class_weights
|
| 18 |
+
class_weights = torch.zeros(n_cls)
|
| 19 |
+
class_weights[:len(tmp)] = tmp
|
| 20 |
+
class_weights = class_weights.cuda()
|
| 21 |
+
return class_weights
|
| 22 |
+
|
| 23 |
+
class NeuroRVQModule():
|
| 24 |
+
'''
|
| 25 |
+
Module that performs fine-tuning of NeuroRVQ
|
| 26 |
+
'''
|
| 27 |
+
def __init__(self, sample_length, chnames, n_out, train_head_only, args, foundation_model):
|
| 28 |
+
self.n_time = sample_length // args['patch_size']
|
| 29 |
+
chnames = np.array([c.lower().encode() for c in chnames])
|
| 30 |
+
self.chmask = np.isin(chnames, ch_names_global)
|
| 31 |
+
self.chnames = chnames[self.chmask]
|
| 32 |
+
self.n_out = n_out
|
| 33 |
+
self.model = foundation_model
|
| 34 |
+
self.train_head_only = train_head_only
|
| 35 |
+
self.criterion = F.cross_entropy if self.n_out > 2 else F.binary_cross_entropy_with_logits
|
| 36 |
+
self.results = {'train_accuracy': [], 'val_accuracy': [], 'train_bacc': [], 'val_bacc': []}
|
| 37 |
+
self.weight_decay = args['weight_decay_finetuning']
|
| 38 |
+
self.warmup_epochs = args['warmup_epochs_finetuning']
|
| 39 |
+
self.amp_dtype = torch.bfloat16
|
| 40 |
+
self.lr = float(args['lr_finetuning'])
|
| 41 |
+
self.layer_decay = float(args['layer_decay_finetuning'])
|
| 42 |
+
self.n_patches = args['n_patches']
|
| 43 |
+
self.patch_size = args['patch_size']
|
| 44 |
+
|
| 45 |
+
def size(self):
|
| 46 |
+
""" Returns number of trainable parameters in model """
|
| 47 |
+
return sum(p.numel() for p in self.model.parameters() if p.requires_grad)
|
| 48 |
+
|
| 49 |
+
def fit(self, train_dataset, validation_dataset, batch_size, epochs):
|
| 50 |
+
d_out = self.n_out if self.n_out > 2 else 1
|
| 51 |
+
self.model.reset_classifier(d_out)
|
| 52 |
+
self.model.cuda()
|
| 53 |
+
# Set model parameter groups with layer_decay on the learning rate
|
| 54 |
+
if self.train_head_only:
|
| 55 |
+
for name, param in self.model.named_parameters():
|
| 56 |
+
if 'head.' in name or 'fc_norm.' in name:
|
| 57 |
+
continue
|
| 58 |
+
else:
|
| 59 |
+
param.requires_grad = False
|
| 60 |
+
|
| 61 |
+
param_groups = {}
|
| 62 |
+
for i_m, (p_name, param) in enumerate(self.model.named_parameters()): # model layers
|
| 63 |
+
if not param.requires_grad:
|
| 64 |
+
continue
|
| 65 |
+
if ('head.' in p_name) or ('fc_norm.' in p_name): # normal lr for classification head
|
| 66 |
+
param_groups[p_name] = {'params': [param],
|
| 67 |
+
'weight_decay': self.weight_decay,
|
| 68 |
+
'lr': self.lr}
|
| 69 |
+
else:
|
| 70 |
+
param_groups[p_name] = {'params': [param],
|
| 71 |
+
'weight_decay': self.weight_decay,
|
| 72 |
+
'lr': self.lr * self.layer_decay ** (
|
| 73 |
+
len(list(self.model.named_parameters())) - i_m)}
|
| 74 |
+
|
| 75 |
+
# Optimizer and lr_scheduler
|
| 76 |
+
optimizer = torch.optim.AdamW(list(param_groups.values()))
|
| 77 |
+
n_batches_train = int(np.ceil(len(train_dataset) / batch_size))
|
| 78 |
+
if epochs < self.warmup_epochs + 1:
|
| 79 |
+
lr_scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1e-1, end_factor=1,
|
| 80 |
+
total_iters=epochs * n_batches_train)
|
| 81 |
+
else:
|
| 82 |
+
scheduler1 = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1e-1, end_factor=1,
|
| 83 |
+
total_iters=self.warmup_epochs * n_batches_train)
|
| 84 |
+
scheduler2 = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1, end_factor=1e-1,
|
| 85 |
+
total_iters=(epochs - self.warmup_epochs) * n_batches_train)
|
| 86 |
+
lr_scheduler = torch.optim.lr_scheduler.SequentialLR(optimizer, [scheduler1, scheduler2],
|
| 87 |
+
milestones=[self.warmup_epochs * n_batches_train])
|
| 88 |
+
warnings.filterwarnings('ignore', category=UserWarning, module='torch.optim.lr_scheduler')
|
| 89 |
+
# Prepare automatic mixed precision training
|
| 90 |
+
scaler = torch.cuda.amp.GradScaler()
|
| 91 |
+
|
| 92 |
+
y_train = [ys for _, ys in train_dataset]
|
| 93 |
+
y_val = [ys for _, ys in validation_dataset]
|
| 94 |
+
y = y_train + y_val
|
| 95 |
+
class_weights = get_class_weights(y, self.n_out)
|
| 96 |
+
|
| 97 |
+
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
|
| 98 |
+
val_dataloader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False)
|
| 99 |
+
|
| 100 |
+
temp_embed_ix, spat_embed_ix = create_embedding_ix(self.n_time, self.n_patches,
|
| 101 |
+
self.chnames, ch_names_global)
|
| 102 |
+
|
| 103 |
+
# Loop over epochs
|
| 104 |
+
for i_epoch in range(epochs):
|
| 105 |
+
print(f"Epoch {i_epoch}")
|
| 106 |
+
# Loop over training batches
|
| 107 |
+
self.model.train()
|
| 108 |
+
e_pred_train = [] # collect predictions
|
| 109 |
+
y_true_train = [] # y in order seen
|
| 110 |
+
for x_b, y_b in tqdm(train_dataloader):
|
| 111 |
+
x_b = x_b[:, self.chmask, :]
|
| 112 |
+
n, c, t = x_b.shape
|
| 113 |
+
x_b = x_b.reshape(n, c, self.n_time, self.patch_size).cuda()
|
| 114 |
+
y_b = y_b.long() if self.n_out > 2 else y_b.float()
|
| 115 |
+
with torch.amp.autocast(device_type='cuda', dtype=self.amp_dtype):
|
| 116 |
+
optimizer.zero_grad()
|
| 117 |
+
p, _ = self.model(x_b, temp_embed_ix, spat_embed_ix)
|
| 118 |
+
p = p.squeeze(-1) # remove class dim if binary task
|
| 119 |
+
loss_weight = class_weights if p.ndim == 2 else class_weights[y_b.long()]
|
| 120 |
+
loss = self.criterion(p, y_b.cuda(), weight=loss_weight)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
scaler.scale(loss).backward()
|
| 124 |
+
scaler.step(optimizer)
|
| 125 |
+
scaler.update()
|
| 126 |
+
lr_scheduler.step()
|
| 127 |
+
|
| 128 |
+
# Collect class predictions to compute metrics on the full epoch
|
| 129 |
+
p = p.detach().cpu().float()
|
| 130 |
+
p = p.argmax(dim=-1) if p.ndim == 2 else torch.round(torch.sigmoid(p))
|
| 131 |
+
e_pred_train += [p.numpy()]
|
| 132 |
+
y_true_train += [y_b.numpy()]
|
| 133 |
+
|
| 134 |
+
# Loop over validation batches
|
| 135 |
+
self.model.eval()
|
| 136 |
+
e_pred_val = [] # collect predictions
|
| 137 |
+
y_true_val = [] # y in order seen
|
| 138 |
+
for x_b, y_b in tqdm(val_dataloader):
|
| 139 |
+
x_b = x_b[:, self.chmask, :]
|
| 140 |
+
n, c, t = x_b.shape
|
| 141 |
+
x_b = x_b.reshape(n, c, self.n_time, self.patch_size).cuda()
|
| 142 |
+
with torch.amp.autocast(device_type='cuda', dtype=self.amp_dtype):
|
| 143 |
+
p, _ = self.model(x_b, temp_embed_ix, spat_embed_ix)
|
| 144 |
+
p = p.squeeze(-1) # remove class dim if binary task
|
| 145 |
+
|
| 146 |
+
# Collect class predictions to compute metrics on the full epoch
|
| 147 |
+
p = p.detach().cpu().float()
|
| 148 |
+
p = p.argmax(dim=-1) if p.ndim == 2 else torch.round(torch.sigmoid(p))
|
| 149 |
+
e_pred_val += [p.numpy()]
|
| 150 |
+
y_true_val += [y_b.numpy()]
|
| 151 |
+
|
| 152 |
+
# Compute accuracy and balanced accuracy
|
| 153 |
+
e_pred_train = np.concatenate(e_pred_train)
|
| 154 |
+
e_pred_val = np.concatenate(e_pred_val)
|
| 155 |
+
y_true_train = np.concatenate(y_true_train)
|
| 156 |
+
y_true_val = np.concatenate(y_true_val)
|
| 157 |
+
|
| 158 |
+
self.results['train_accuracy'] += [accuracy_score(y_true_train, e_pred_train)]
|
| 159 |
+
self.results['val_accuracy'] += [accuracy_score(y_true_val, e_pred_val)]
|
| 160 |
+
self.results['train_bacc'] += [balanced_accuracy_score(y_true_train, e_pred_train)]
|
| 161 |
+
self.results['val_bacc'] += [balanced_accuracy_score(y_true_val, e_pred_val)]
|
| 162 |
+
if len(validation_dataset) > 1:
|
| 163 |
+
print(f"VAL ACC: {self.results['val_accuracy'][-1]}, VAL BACC: {self.results['val_bacc'][-1]}")
|
fine_tuning/data.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from abc import ABC
|
| 4 |
+
|
| 5 |
+
class Benchmark(ABC):
|
| 6 |
+
"""
|
| 7 |
+
Class for benchmark dataset with expected properties:
|
| 8 |
+
eeg: array of EEG data (samples, channels, time)
|
| 9 |
+
subject_ids: array of subject ID for each data sample (samples,)
|
| 10 |
+
labels: array of target class labels for each data sample (samples,)
|
| 11 |
+
chnames: array of electrode channel names (channels,)
|
| 12 |
+
"""
|
| 13 |
+
def __init__(self):
|
| 14 |
+
self.eeg = None
|
| 15 |
+
self.subject_ids = None
|
| 16 |
+
self.labels = None
|
| 17 |
+
self.chnames = None
|
| 18 |
+
|
| 19 |
+
def get_data(self):
|
| 20 |
+
return self.eeg, self.subject_ids, self.labels, self.chnames
|
| 21 |
+
|
| 22 |
+
def sample_balanced_set(self, idx, seed):
|
| 23 |
+
"""
|
| 24 |
+
Performs a random sampling of indices to balance classes for each subject
|
| 25 |
+
idx: array of sample indices relative to self.eeg
|
| 26 |
+
seed: random seed for sampling
|
| 27 |
+
Returns:
|
| 28 |
+
filtered indices after random sampling
|
| 29 |
+
"""
|
| 30 |
+
rng = np.random.default_rng(seed)
|
| 31 |
+
subj_all = self.subject_ids[idx]
|
| 32 |
+
y_all = self.labels[idx]
|
| 33 |
+
sampled = []
|
| 34 |
+
|
| 35 |
+
for s in np.unique(subj_all):
|
| 36 |
+
mask_s = (subj_all == s)
|
| 37 |
+
idx_s = idx[mask_s]
|
| 38 |
+
y_s = y_all[mask_s]
|
| 39 |
+
|
| 40 |
+
labels = np.unique(y_s)
|
| 41 |
+
|
| 42 |
+
idx_by_label = [idx_s[y_s == label] for label in labels]
|
| 43 |
+
|
| 44 |
+
# minority per subject
|
| 45 |
+
n = min([len(idx_l) for idx_l in idx_by_label])
|
| 46 |
+
if n == 0:
|
| 47 |
+
continue
|
| 48 |
+
|
| 49 |
+
take_by_label = [rng.choice(idx_l, size=n, replace=False) for idx_l in idx_by_label]
|
| 50 |
+
sampled.append(np.concatenate(take_by_label))
|
| 51 |
+
|
| 52 |
+
sampled_idx = np.concatenate(sampled)
|
| 53 |
+
return sampled_idx
|
| 54 |
+
|
| 55 |
+
class YourCustomBenchmark(Benchmark):
|
| 56 |
+
"""
|
| 57 |
+
Custom Class Example where your eeg trials are in stored in .npy file
|
| 58 |
+
The labels and other info in the .pd file
|
| 59 |
+
And your dasaset has 4-classes
|
| 60 |
+
"""
|
| 61 |
+
def __init__(self, root, subdir, apply_car):
|
| 62 |
+
super().__init__()
|
| 63 |
+
print("Loading Your Data...")
|
| 64 |
+
eeg = np.load('./fine_tuning/data/data_eeg.npy', mmap_mode='r')
|
| 65 |
+
tf = pd.read_pickle('./fine_tuning/data/trial_features.pd')
|
| 66 |
+
subject_ids = tf['subject_id'].to_numpy()
|
| 67 |
+
chnames = np.array([c.upper() for c in tf.attrs['channel_names']])
|
| 68 |
+
labels = tf['task'].replace({'class_1': 0, 'class_2': 1, 'class_3': 2, 'class_4': 3}).to_numpy()
|
| 69 |
+
|
| 70 |
+
self.eeg = eeg
|
| 71 |
+
self.subject_ids = subject_ids
|
| 72 |
+
self.labels = labels
|
| 73 |
+
self.chnames = chnames
|
| 74 |
+
|
| 75 |
+
def sample_balanced_set(self, idx, seed):
|
| 76 |
+
print("Classes are already balanced for High Gamma")
|
| 77 |
+
return idx
|
| 78 |
+
|
| 79 |
+
def load_benchmark(benchmark, root, subdir, apply_car=False) -> Benchmark:
|
| 80 |
+
BENCHMARK_CLASSES = {
|
| 81 |
+
"Custom Benchmark": YourCustomBenchmark
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
assert (benchmark in BENCHMARK_CLASSES), f"Unsupported benchmark {benchmark}. Make sure load function is added to BENCHMARK_LOADERS."
|
| 85 |
+
|
| 86 |
+
benchmark_cls = BENCHMARK_CLASSES[benchmark]
|
| 87 |
+
return benchmark_cls(root, subdir, apply_car)
|
fine_tuning/utils.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import csv
|
| 3 |
+
from fine_tuning.wrappers import NeuroRVQWrapper
|
| 4 |
+
|
| 5 |
+
class CSVLogger():
|
| 6 |
+
def __init__(self, output_dir, ex_id):
|
| 7 |
+
self.log_dir = os.path.join(output_dir, f"{ex_id}_log")
|
| 8 |
+
if not os.path.exists(self.log_dir):
|
| 9 |
+
os.makedirs(self.log_dir)
|
| 10 |
+
self._files = set()
|
| 11 |
+
|
| 12 |
+
def report_scalar(self, title, series, value, iteration):
|
| 13 |
+
'''
|
| 14 |
+
Mimics clearml report_scalar() function to log values to CSV file
|
| 15 |
+
'''
|
| 16 |
+
if 'train' in series:
|
| 17 |
+
filepath = os.path.join(self.log_dir, f"{title}_train.csv")
|
| 18 |
+
else:
|
| 19 |
+
filepath = os.path.join(self.log_dir, f"{title}_val.csv")
|
| 20 |
+
|
| 21 |
+
write_header = filepath not in self._files
|
| 22 |
+
|
| 23 |
+
with open(filepath, mode="a", newline="") as f:
|
| 24 |
+
writer = csv.writer(f)
|
| 25 |
+
if 'MEAN' in title:
|
| 26 |
+
if write_header:
|
| 27 |
+
writer.writerow(["Series", "Iteration", "Value"])
|
| 28 |
+
self._files.add(filepath)
|
| 29 |
+
writer.writerow([series, iteration, value])
|
| 30 |
+
else:
|
| 31 |
+
if write_header:
|
| 32 |
+
writer.writerow(["Fold", "Iteration", "Value"])
|
| 33 |
+
self._files.add(filepath)
|
| 34 |
+
writer.writerow([series.split(' ')[-1], iteration, value])
|
| 35 |
+
|
| 36 |
+
def get_logger():
|
| 37 |
+
logger = CSVLogger("results", 0)
|
| 38 |
+
return logger
|
| 39 |
+
|
| 40 |
+
def get_model(ch_names, n_times, n_outputs, args, foundation_model, train_head_only=False):
|
| 41 |
+
"""
|
| 42 |
+
Returns: FinetuningWrapper for the specified model
|
| 43 |
+
"""
|
| 44 |
+
return NeuroRVQWrapper(
|
| 45 |
+
n_time=n_times,
|
| 46 |
+
ch_names=ch_names,
|
| 47 |
+
n_outputs=n_outputs,
|
| 48 |
+
train_head_only=train_head_only,
|
| 49 |
+
args = args,
|
| 50 |
+
foundation_model = foundation_model
|
| 51 |
+
)
|
fine_tuning/wrappers.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Wrapper classes of foundation model modules for use in main benchmarking script
|
| 3 |
+
'''
|
| 4 |
+
import torch
|
| 5 |
+
from abc import ABC, abstractmethod
|
| 6 |
+
from fine_tuning.NeuroRVQ_EEG_FM_FineTuning import NeuroRVQModule
|
| 7 |
+
|
| 8 |
+
class FinetuningWrapper(ABC):
|
| 9 |
+
"""
|
| 10 |
+
Wrapper class for initializing model, fitting and evaluating on benchmark data, and storing results
|
| 11 |
+
"""
|
| 12 |
+
def __init__(self):
|
| 13 |
+
self.model = None
|
| 14 |
+
self.results = {}
|
| 15 |
+
|
| 16 |
+
@abstractmethod
|
| 17 |
+
def fit(self, train_dataset, validation_dataset, batch_size, epochs):
|
| 18 |
+
print("fit function not implemented")
|
| 19 |
+
|
| 20 |
+
def size(self):
|
| 21 |
+
""" Returns number of trainable parameters in model """
|
| 22 |
+
if self.model is None:
|
| 23 |
+
print("model not initialised")
|
| 24 |
+
else:
|
| 25 |
+
return self.model.size()
|
| 26 |
+
|
| 27 |
+
class NeuroRVQWrapper(FinetuningWrapper):
|
| 28 |
+
def __init__(self, n_time, ch_names, n_outputs, train_head_only, args, foundation_model):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.model = NeuroRVQModule(
|
| 31 |
+
sample_length=n_time,
|
| 32 |
+
chnames=ch_names,
|
| 33 |
+
n_out=n_outputs,
|
| 34 |
+
train_head_only=train_head_only,
|
| 35 |
+
args = args,
|
| 36 |
+
foundation_model = foundation_model
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
def fit(self, train_dataset, validation_dataset, batch_size, epochs):
|
| 40 |
+
self.model.fit(train_dataset, validation_dataset, batch_size, epochs)
|
| 41 |
+
self.results = self.model.results
|
| 42 |
+
|
| 43 |
+
def save_model(self, path):
|
| 44 |
+
print(f'Saving checkpoint to {path}...')
|
| 45 |
+
torch.save(self.model.model.state_dict(), path)
|
flags/NeuroRVQ_EEG_v1.yml
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
patch_size: 200
|
| 2 |
+
n_patches: 256
|
| 3 |
+
num_classes: 5
|
| 4 |
+
n_code: 8192
|
| 5 |
+
code_dim: 128
|
| 6 |
+
embed_dim: 200
|
| 7 |
+
|
| 8 |
+
weight_decay_finetuning: 1e-2
|
| 9 |
+
warmup_epochs_finetuning: 4
|
| 10 |
+
lr_finetuning: 5e-4
|
| 11 |
+
layer_decay_finetuning: 0.975
|
| 12 |
+
train_head_only_finetuning: False
|
| 13 |
+
batch_size_finetuning: 32
|
| 14 |
+
epoch_finetuning: 20
|
| 15 |
+
model_name: NeuroRVQ
|
| 16 |
+
|
| 17 |
+
in_chans_encoder: 1
|
| 18 |
+
out_chans_encoder: 8
|
| 19 |
+
depth_encoder: 12
|
| 20 |
+
depth_decoder: 3
|
| 21 |
+
decoder_out_dim: 200
|
| 22 |
+
|
| 23 |
+
num_heads_tokenizer: 10
|
| 24 |
+
mlp_ratio_tokenizer: 4
|
| 25 |
+
qkv_bias_tokenizer: True
|
| 26 |
+
drop_rate_tokenizer: 0.
|
| 27 |
+
attn_drop_rate_tokenizer: 0.
|
| 28 |
+
drop_path_rate_tokenizer: 0.
|
| 29 |
+
init_values_tokenizer: 0.
|
| 30 |
+
init_scale_tokenizer: 0.001
|
| 31 |
+
|
| 32 |
+
use_for_pretraining: True
|
| 33 |
+
|
| 34 |
+
in_chans_second_stage: 1
|
| 35 |
+
out_chans_second_stage: 8
|
| 36 |
+
depth_second_stage: 12
|
| 37 |
+
num_heads_second_stage: 10
|
| 38 |
+
mlp_ratio_second_stage: 4.
|
| 39 |
+
qkv_bias_second_stage: True
|
| 40 |
+
drop_rate_second_stage: 0.
|
| 41 |
+
attn_drop_rate_second_stage: 0.
|
| 42 |
+
drop_path_rate_second_stage: 0.
|
| 43 |
+
init_values_second_stage: 1.e-5
|
| 44 |
+
init_scale_second_stage: 0.001
|
| 45 |
+
embed_dim_second_stage: 200
|
| 46 |
+
|
| 47 |
+
|
images/banner.png
ADDED

|
Git LFS Details
|
images/ecg.png
ADDED

|
Git LFS Details
|
images/eeg.png
ADDED
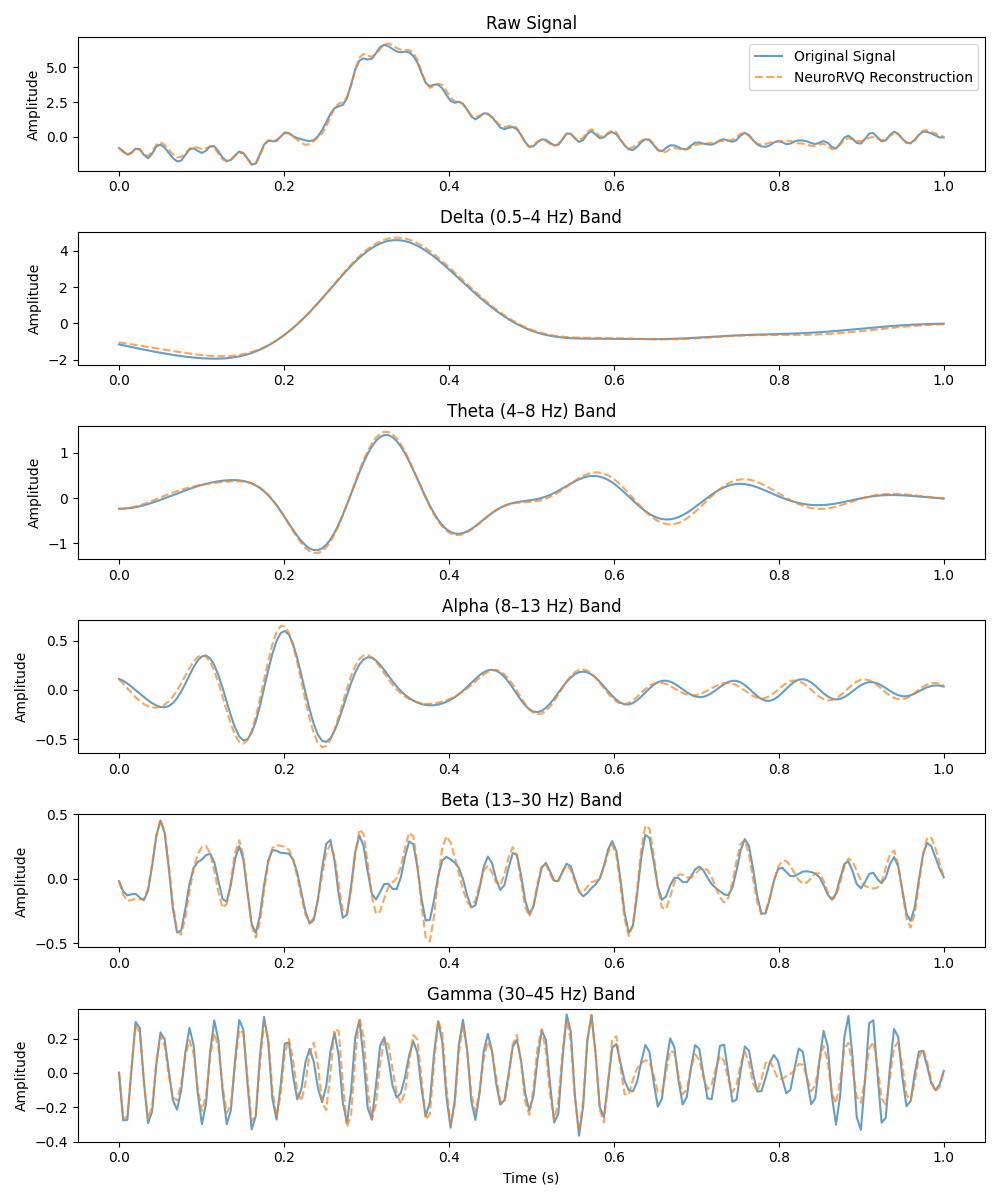
|
Git LFS Details
|
images/emg.png
ADDED
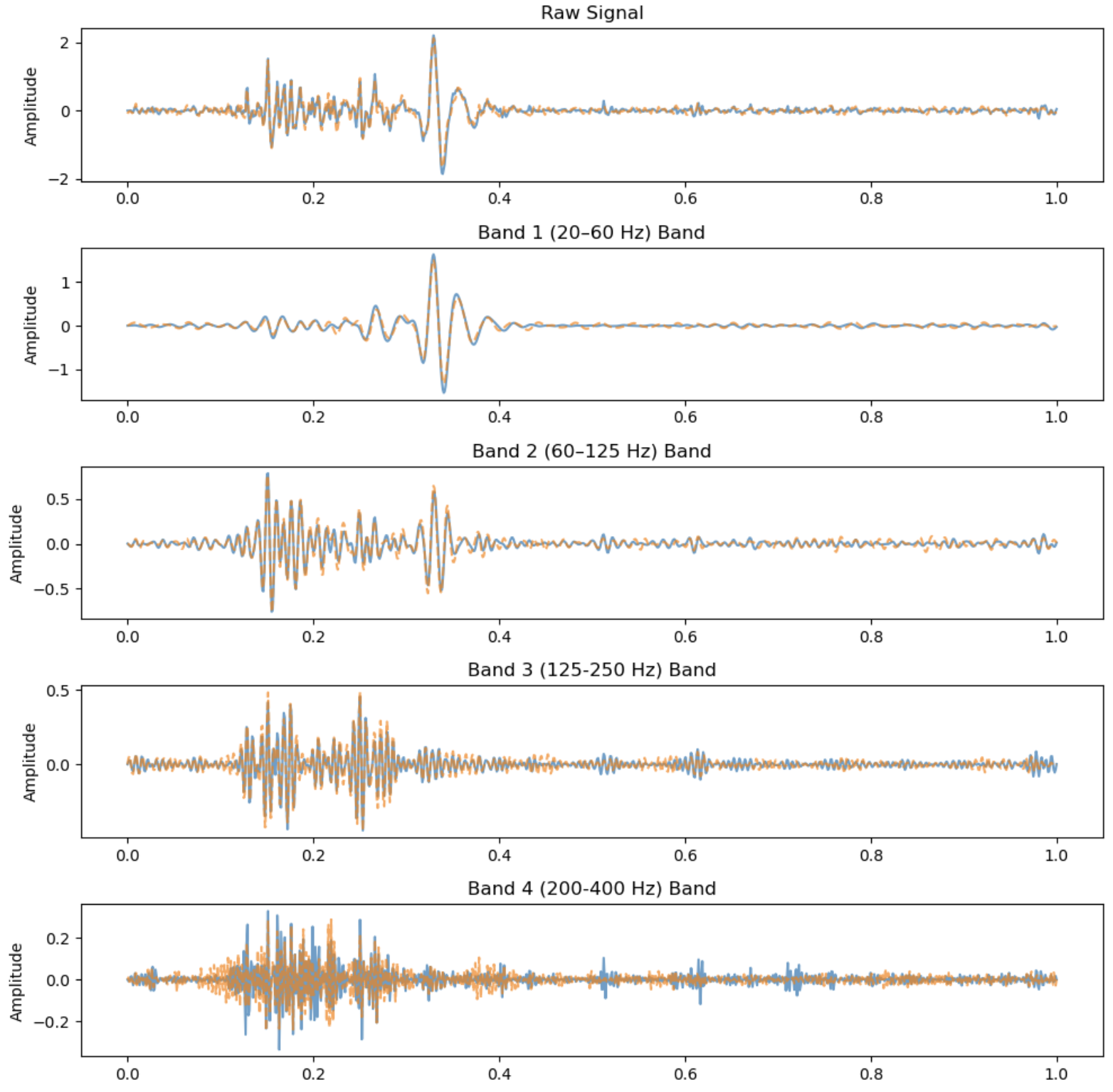
|
Git LFS Details
|
inference/modules/NeuroRVQ_EEG_FM_inference_modules.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
# List of all channels used in the pre-training of "NeuroRVQ_EEG_v1" model
|
| 5 |
+
ch_names_global = np.array([b'a1', b'a2', b'af3', b'af4', b'af7', b'af8', b'afz', b'c1', b'c2',
|
| 6 |
+
b'c3', b'c4', b'c5', b'c6', b'ccp1', b'ccp2', b'ccp3', b'ccp4',
|
| 7 |
+
b'ccp5', b'ccp6', b'ccp7', b'ccp8', b'cfc1', b'cfc2', b'cfc3',
|
| 8 |
+
b'cfc4', b'cfc5', b'cfc6', b'cfc7', b'cfc8', b'cp1', b'cp2',
|
| 9 |
+
b'cp3', b'cp4', b'cp5', b'cp6', b'cpz', b'cz', b'eog', b'f1',
|
| 10 |
+
b'f10', b'f2', b'f3', b'f4', b'f5', b'f6', b'f7', b'f8', b'f9',
|
| 11 |
+
b'fc1', b'fc2', b'fc3', b'fc4', b'fc5', b'fc6', b'fcz', b'fp1',
|
| 12 |
+
b'fp2', b'fpz', b'ft7', b'ft8', b'fz', b'iz', b'loc', b'o1', b'o2',
|
| 13 |
+
b'oz', b'p08', b'p1', b'p10', b'p2', b'p3', b'p4', b'p5', b'p6',
|
| 14 |
+
b'p7', b'p8', b'p9', b'po1', b'po10', b'po2', b'po3', b'po4',
|
| 15 |
+
b'po7', b'po8', b'po9', b'poz', b'pz', b'roc', b'sp1', b'sp2',
|
| 16 |
+
b't1', b't10', b't2', b't3', b't4', b't5', b't6', b't7', b't8',
|
| 17 |
+
b't9', b'tp10', b'tp7', b'tp8', b'tp9'])
|
| 18 |
+
|
| 19 |
+
def check_model_eval_mode(model):
|
| 20 |
+
for name, module in model.named_modules():
|
| 21 |
+
if hasattr(module, 'training'):
|
| 22 |
+
if module.training:
|
| 23 |
+
print(f"[WARNING] Module {name} is still in training mode.")
|
| 24 |
+
else:
|
| 25 |
+
print(f"[OK] Module {name} is in eval mode.")
|
| 26 |
+
|
| 27 |
+
def create_embedding_ix(n_time, max_n_patches, ch_names_sample, ch_names_global):
|
| 28 |
+
"""Creates temporal and spatial embedding indices for a sample with given regular shape.
|
| 29 |
+
Args:
|
| 30 |
+
n_time: Int. Number of patches along the time dimension
|
| 31 |
+
max_n_patches: The maximum number of patches, for aligning the current time-point to the right.
|
| 32 |
+
ch_names_sample (n_channels_sample,): The specific channel names of the sample
|
| 33 |
+
ch_names_global (n_channels_global): The reference channel names of the model
|
| 34 |
+
Returns:
|
| 35 |
+
temp_embed_ix (1, n_patches): tensor
|
| 36 |
+
spat_embed_ix (1, n_patches): tensor
|
| 37 |
+
"""
|
| 38 |
+
# Temporal embedding ix
|
| 39 |
+
temp_embed_ix = torch.arange(max_n_patches - n_time, max_n_patches)
|
| 40 |
+
temp_embed_ix = temp_embed_ix.repeat(len(ch_names_sample))
|
| 41 |
+
temp_embed_ix = temp_embed_ix.reshape(1, -1)
|
| 42 |
+
|
| 43 |
+
# Spatial embedding ix
|
| 44 |
+
spat_embed_ix = torch.tensor([np.where(ch_names_global == c)[0][0] for c in ch_names_sample])
|
| 45 |
+
spat_embed_ix = torch.repeat_interleave(spat_embed_ix, n_time)
|
| 46 |
+
spat_embed_ix = spat_embed_ix.reshape(1, -1)
|
| 47 |
+
|
| 48 |
+
return temp_embed_ix, spat_embed_ix
|
inference/modules/NeuroRVQ_EEG_tokenizer_inference_modules.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
# List of all channels used in the pre-training of "NeuroRVQ_EEG_v1" model
|
| 5 |
+
ch_names_global = np.array([b'a1', b'a2', b'af3', b'af4', b'af7', b'af8', b'afz', b'c1', b'c2',
|
| 6 |
+
b'c3', b'c4', b'c5', b'c6', b'ccp1', b'ccp2', b'ccp3', b'ccp4',
|
| 7 |
+
b'ccp5', b'ccp6', b'ccp7', b'ccp8', b'cfc1', b'cfc2', b'cfc3',
|
| 8 |
+
b'cfc4', b'cfc5', b'cfc6', b'cfc7', b'cfc8', b'cp1', b'cp2',
|
| 9 |
+
b'cp3', b'cp4', b'cp5', b'cp6', b'cpz', b'cz', b'eog', b'f1',
|
| 10 |
+
b'f10', b'f2', b'f3', b'f4', b'f5', b'f6', b'f7', b'f8', b'f9',
|
| 11 |
+
b'fc1', b'fc2', b'fc3', b'fc4', b'fc5', b'fc6', b'fcz', b'fp1',
|
| 12 |
+
b'fp2', b'fpz', b'ft7', b'ft8', b'fz', b'iz', b'loc', b'o1', b'o2',
|
| 13 |
+
b'oz', b'p08', b'p1', b'p10', b'p2', b'p3', b'p4', b'p5', b'p6',
|
| 14 |
+
b'p7', b'p8', b'p9', b'po1', b'po10', b'po2', b'po3', b'po4',
|
| 15 |
+
b'po7', b'po8', b'po9', b'poz', b'pz', b'roc', b'sp1', b'sp2',
|
| 16 |
+
b't1', b't10', b't2', b't3', b't4', b't5', b't6', b't7', b't8',
|
| 17 |
+
b't9', b'tp10', b'tp7', b'tp8', b'tp9'])
|
| 18 |
+
|
| 19 |
+
def check_model_eval_mode(model):
|
| 20 |
+
for name, module in model.named_modules():
|
| 21 |
+
if hasattr(module, 'training'):
|
| 22 |
+
if module.training:
|
| 23 |
+
print(f"[WARNING] Module {name} is still in training mode.")
|
| 24 |
+
else:
|
| 25 |
+
print(f"[OK] Module {name} is in eval mode.")
|
| 26 |
+
|
| 27 |
+
def create_embedding_ix(n_time, max_n_patches, ch_names_sample, ch_names_global):
|
| 28 |
+
"""Creates temporal and spatial embedding indices for a sample with given regular shape.
|
| 29 |
+
Args:
|
| 30 |
+
n_time: Int. Number of patches along the time dimension
|
| 31 |
+
max_n_patches: The maximum number of patches, for aligning the current time-point to the right.
|
| 32 |
+
ch_names_sample (n_channels_sample,): The specific channel names of the sample
|
| 33 |
+
ch_names_global (n_channels_global): The reference channel names of the model
|
| 34 |
+
Returns:
|
| 35 |
+
temp_embed_ix (1, n_patches): tensor
|
| 36 |
+
spat_embed_ix (1, n_patches): tensor
|
| 37 |
+
"""
|
| 38 |
+
# Temporal embedding ix
|
| 39 |
+
temp_embed_ix = torch.arange(max_n_patches - n_time, max_n_patches)
|
| 40 |
+
temp_embed_ix = temp_embed_ix.repeat(len(ch_names_sample))
|
| 41 |
+
temp_embed_ix = temp_embed_ix.reshape(1, -1)
|
| 42 |
+
|
| 43 |
+
# Spatial embedding ix
|
| 44 |
+
spat_embed_ix = torch.tensor([np.where(ch_names_global == c)[0][0] for c in ch_names_sample])
|
| 45 |
+
spat_embed_ix = torch.repeat_interleave(spat_embed_ix, n_time)
|
| 46 |
+
spat_embed_ix = spat_embed_ix.reshape(1, -1)
|
| 47 |
+
|
| 48 |
+
return temp_embed_ix, spat_embed_ix
|
inference/run/NeuroRVQ_EEG_FM_example.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import yaml
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from NeuroRVQ.NeuroRVQ import NeuroRVQFM
|
| 5 |
+
from NeuroRVQ.NeuroRVQ_modules import get_encoder_decoder_params
|
| 6 |
+
from inference.modules.NeuroRVQ_EEG_tokenizer_inference_modules import ch_names_global, create_embedding_ix, check_model_eval_mode
|
| 7 |
+
from functools import partial
|
| 8 |
+
from torch import nn
|
| 9 |
+
from fine_tuning.utils import get_logger, get_model
|
| 10 |
+
from fine_tuning.data import load_benchmark
|
| 11 |
+
import skorch
|
| 12 |
+
|
| 13 |
+
def perform_finetuning(benchmarks, metrics, args, foundation_model):
|
| 14 |
+
'''
|
| 15 |
+
Performs full finetuning on benchmarks using all data for training (no folds, no validation set)
|
| 16 |
+
Saves finetuned model, no metrics returned
|
| 17 |
+
'''
|
| 18 |
+
logger = get_logger()
|
| 19 |
+
results = {}
|
| 20 |
+
for benchmark in benchmarks:
|
| 21 |
+
# Load data stored in "./fine_tuning/data" folder - see example in data.py
|
| 22 |
+
b = load_benchmark(benchmark, './', "NeuroRVQ")
|
| 23 |
+
X, sbj_id, y, ch_names = b.get_data()
|
| 24 |
+
n_outputs = len(np.unique(y))
|
| 25 |
+
n, c, t = X.shape
|
| 26 |
+
dataset = skorch.dataset.Dataset(X[:-1], y[:-1])
|
| 27 |
+
dummy_val = skorch.dataset.Dataset(np.array([X[0]]), np.array([y[0]]))
|
| 28 |
+
|
| 29 |
+
# Make model
|
| 30 |
+
model = get_model(
|
| 31 |
+
ch_names=ch_names,
|
| 32 |
+
n_times=t,
|
| 33 |
+
n_outputs=n_outputs,
|
| 34 |
+
args = args,
|
| 35 |
+
foundation_model = foundation_model,
|
| 36 |
+
train_head_only=args['train_head_only_finetuning']
|
| 37 |
+
)
|
| 38 |
+
print(f"No. Trainable Parameters: {model.size()}")
|
| 39 |
+
|
| 40 |
+
# Finetune model
|
| 41 |
+
model.fit(
|
| 42 |
+
dataset,
|
| 43 |
+
dummy_val,
|
| 44 |
+
batch_size=args['batch_size_finetuning'],
|
| 45 |
+
epochs=args['epoch_finetuning']
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
# Log training results (per epoch)
|
| 49 |
+
for m in metrics:
|
| 50 |
+
results = model.results[f'train_{m}']
|
| 51 |
+
for i in range(args['epoch_finetuning']):
|
| 52 |
+
logger.report_scalar(title="Fine-Tuning NeuroRVQ", series=f'train',
|
| 53 |
+
value=results[i], iteration=i)
|
| 54 |
+
|
| 55 |
+
# Save model
|
| 56 |
+
torch.save(model.state_dict(), './fine_tuned_model.pt')
|
| 57 |
+
|
| 58 |
+
return
|
| 59 |
+
|
| 60 |
+
def load_neurorqv_fm(fine_tuning=False, verbose=False,
|
| 61 |
+
model_path='./pretrained_models/foundation_models/NeuroRVQ_EEG_foundation_model_v1.pt'):
|
| 62 |
+
# Load experiment parameters from config file
|
| 63 |
+
config_stream = open("./flags/NeuroRVQ_EEG_v1.yml", 'r')
|
| 64 |
+
args = yaml.safe_load(config_stream)
|
| 65 |
+
|
| 66 |
+
# Fix the seeds for reproducibility
|
| 67 |
+
seed = 123
|
| 68 |
+
torch.manual_seed(seed)
|
| 69 |
+
np.random.seed(seed)
|
| 70 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 71 |
+
# Get configuration params
|
| 72 |
+
args['n_global_electrodes'] = len(ch_names_global)
|
| 73 |
+
encoder_config, decoder_config = get_encoder_decoder_params(args)
|
| 74 |
+
|
| 75 |
+
# Load the foundation model
|
| 76 |
+
foundation_model = NeuroRVQFM(n_patches=args['n_patches'],
|
| 77 |
+
patch_size=args['patch_size'],
|
| 78 |
+
in_chans=args['in_chans_second_stage'],
|
| 79 |
+
out_chans=args['out_chans_second_stage'],
|
| 80 |
+
num_classes=0,
|
| 81 |
+
embed_dim=args['embed_dim_second_stage'],
|
| 82 |
+
depth=args['depth_second_stage'],
|
| 83 |
+
num_heads=args['num_heads_second_stage'],
|
| 84 |
+
mlp_ratio=args['mlp_ratio_second_stage'], qkv_bias=args['qkv_bias_second_stage'],
|
| 85 |
+
qk_norm=partial(nn.LayerNorm, eps=1e-6), drop_rate=args['drop_rate_second_stage'],
|
| 86 |
+
attn_drop_rate=args['attn_drop_rate_second_stage'],
|
| 87 |
+
drop_path_rate=args['drop_path_rate_second_stage'],
|
| 88 |
+
init_values=args['init_values_second_stage'],
|
| 89 |
+
init_scale=args['init_scale_second_stage'],
|
| 90 |
+
n_global_electrodes=args['n_global_electrodes'],
|
| 91 |
+
use_as_encoder = True, vocab_size=args['n_code'],
|
| 92 |
+
use_for_pretraining = False).to(device)
|
| 93 |
+
|
| 94 |
+
missing_keys, unexpected_keys = foundation_model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')), strict=False)
|
| 95 |
+
total_params = sum(p.numel() for p in foundation_model.parameters())
|
| 96 |
+
print(f"Total parameters: {total_params}")
|
| 97 |
+
|
| 98 |
+
if (verbose):
|
| 99 |
+
print(f"Missing keys: {missing_keys},\nUnexpected keys: {unexpected_keys}")
|
| 100 |
+
|
| 101 |
+
if (fine_tuning):
|
| 102 |
+
# Select benchmark datasets
|
| 103 |
+
benchmarks = ["High Gamma"]
|
| 104 |
+
# Select evaluation metrics
|
| 105 |
+
# NOTE: metrics not included in this list will need to be implemented in the module for each model
|
| 106 |
+
metrics = ["accuracy", "bacc"]
|
| 107 |
+
perform_finetuning(benchmarks, metrics, args, foundation_model)
|
inference/run/NeuroRVQ_EEG_tokenizer_example.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import yaml
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from NeuroRVQ.NeuroRVQ import NeuroRVQTokenizer
|
| 5 |
+
from NeuroRVQ.NeuroRVQ_modules import get_encoder_decoder_params
|
| 6 |
+
from preprocessing.preprocessing_eeg_example import preprocessing_eeg
|
| 7 |
+
from plotting.plotting_example import process_and_plot
|
| 8 |
+
from preprocessing.preprocessing_eeg_example import create_patches
|
| 9 |
+
from inference.modules.NeuroRVQ_EEG_tokenizer_inference_modules import ch_names_global, create_embedding_ix, check_model_eval_mode
|
| 10 |
+
|
| 11 |
+
def load_neurorqv_tokenizer(run_example=False, plot_results=False, verbose=False,
|
| 12 |
+
model_path='./pretrained_models/tokenizers/NeuroRVQ_EEG_tokenizer_v1.pt'):
|
| 13 |
+
# Load experiment parameters from config file
|
| 14 |
+
config_stream = open("./flags/NeuroRVQ_EEG_v1.yml", 'r')
|
| 15 |
+
args = yaml.safe_load(config_stream)
|
| 16 |
+
|
| 17 |
+
# Fix the seeds for reproducibility
|
| 18 |
+
seed = 123
|
| 19 |
+
torch.manual_seed(seed)
|
| 20 |
+
np.random.seed(seed)
|
| 21 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 22 |
+
|
| 23 |
+
# Get configuration params for tokenizer
|
| 24 |
+
args['n_global_electrodes'] = len(ch_names_global)
|
| 25 |
+
encoder_config, decoder_config = get_encoder_decoder_params(args)
|
| 26 |
+
|
| 27 |
+
# Load the tokenizer
|
| 28 |
+
tokenizer = NeuroRVQTokenizer(encoder_config, decoder_config, n_code=args['n_code'],
|
| 29 |
+
code_dim=args['code_dim'], decoder_out_dim=args['decoder_out_dim']).to(device)
|
| 30 |
+
|
| 31 |
+
tokenizer.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
|
| 32 |
+
tokenizer.eval()
|
| 33 |
+
|
| 34 |
+
if (verbose):
|
| 35 |
+
check_model_eval_mode(tokenizer)
|
| 36 |
+
|
| 37 |
+
if (run_example):
|
| 38 |
+
x, ch_names = preprocessing_eeg('example_files/eeg_sample/example_eeg_file.xdf')
|
| 39 |
+
ch_mask = np.isin(ch_names, ch_names_global)
|
| 40 |
+
ch_names = ch_names[ch_mask]
|
| 41 |
+
x = x[:, ch_mask, :]
|
| 42 |
+
|
| 43 |
+
x, n_time = create_patches(x, maximum_patches=args['n_patches'], patch_size=args['patch_size'], channels_use=ch_mask)
|
| 44 |
+
x = torch.from_numpy(x).float().to(device)
|
| 45 |
+
|
| 46 |
+
temporal_embedding_ix, spatial_embedding_ix = create_embedding_ix(n_time, args['n_patches'], ch_names, ch_names_global)
|
| 47 |
+
oringal_signal_std, reconstructed_signal_std = tokenizer(x, temporal_embedding_ix.int().to(device), spatial_embedding_ix.int().to(device))
|
| 48 |
+
|
| 49 |
+
if (plot_results):
|
| 50 |
+
process_and_plot(oringal_signal_std, reconstructed_signal_std, fs=args['patch_size'])
|
plotting/plotting_example.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from scipy.signal import butter, filtfilt
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
# Define EEG bands
|
| 8 |
+
bands = {
|
| 9 |
+
"Delta (0.5–4 Hz)": (0.5, 4),
|
| 10 |
+
"Theta (4–8 Hz)": (4, 8),
|
| 11 |
+
"Alpha (8–13 Hz)": (8, 13),
|
| 12 |
+
"Beta (13–30 Hz)": (13, 30),
|
| 13 |
+
"Gamma (30–45 Hz)": (30, 45),
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
# Bandpass filter function
|
| 17 |
+
def bandpass_filter(data, lowcut, highcut, fs, order=2):
|
| 18 |
+
nyq = 0.5 * fs
|
| 19 |
+
low, high = lowcut / nyq, highcut / nyq
|
| 20 |
+
b, a = butter(order, [low, high], btype='band')
|
| 21 |
+
return filtfilt(b, a, data)
|
| 22 |
+
|
| 23 |
+
def plot_reconstructions(originals_list, reconstructions_list, fs,
|
| 24 |
+
labels=["NeuroRVQ"], save_dir="./figures"):
|
| 25 |
+
|
| 26 |
+
if not os.path.exists(save_dir):
|
| 27 |
+
os.makedirs(save_dir)
|
| 28 |
+
|
| 29 |
+
N, T = originals_list[0].shape
|
| 30 |
+
time = np.linspace(0, T / fs, T)
|
| 31 |
+
|
| 32 |
+
for i in tqdm(range(N), desc="Samples"):
|
| 33 |
+
plt.figure(figsize=(10, 12))
|
| 34 |
+
|
| 35 |
+
# Plot raw signals
|
| 36 |
+
plt.subplot(6, 1, 1)
|
| 37 |
+
orig = originals_list[0][i]
|
| 38 |
+
recon = reconstructions_list[0][i]
|
| 39 |
+
label = labels[0]
|
| 40 |
+
|
| 41 |
+
plt.plot(time, orig, label=f"Original Signal", alpha=0.7)
|
| 42 |
+
plt.plot(time, recon, linestyle='--', label=f"{label} Reconstruction", alpha=0.7)
|
| 43 |
+
|
| 44 |
+
plt.title(f"Raw Signal")
|
| 45 |
+
plt.legend()
|
| 46 |
+
plt.ylabel("Amplitude")
|
| 47 |
+
|
| 48 |
+
# Plot filtered bands
|
| 49 |
+
for j, (band_name, (low, high)) in enumerate(bands.items()):
|
| 50 |
+
plt.subplot(6, 1, j + 2)
|
| 51 |
+
orig = originals_list[0][i]
|
| 52 |
+
recon = reconstructions_list[0][i]
|
| 53 |
+
label = labels[0]
|
| 54 |
+
|
| 55 |
+
orig_band = bandpass_filter(orig, low, high, fs)
|
| 56 |
+
recon_band = bandpass_filter(recon, low, high, fs)
|
| 57 |
+
|
| 58 |
+
plt.plot(time, orig_band, label=f"{label} Original Signal", alpha=0.7)
|
| 59 |
+
plt.plot(time, recon_band, linestyle='--', label=f"{label} Reconstruction", alpha=0.7)
|
| 60 |
+
|
| 61 |
+
plt.title(f"{band_name} Band")
|
| 62 |
+
plt.ylabel("Amplitude")
|
| 63 |
+
|
| 64 |
+
plt.xlabel("Time (s)")
|
| 65 |
+
plt.tight_layout()
|
| 66 |
+
|
| 67 |
+
plt.savefig(f"{save_dir}/sample_{i}.png")
|
| 68 |
+
plt.close()
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def process_and_plot(originals, reconstructions, fs):
|
| 72 |
+
P, T = reconstructions[0].shape
|
| 73 |
+
|
| 74 |
+
originals_np = [
|
| 75 |
+
original.detach().cpu().numpy().reshape(P, T)
|
| 76 |
+
for original in originals
|
| 77 |
+
]
|
| 78 |
+
reconstructions_np = [
|
| 79 |
+
reconstruction.detach().cpu().numpy().reshape(P, T)
|
| 80 |
+
for reconstruction in reconstructions
|
| 81 |
+
]
|
| 82 |
+
|
| 83 |
+
# Plot
|
| 84 |
+
plot_reconstructions(originals_np, reconstructions_np, fs)
|
preprocessing/preprocessing_eeg_example.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pyxdf
|
| 2 |
+
from scipy import signal
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
'''
|
| 6 |
+
Example of how to preprocess an EEG recording
|
| 7 |
+
Notch filter: 50., 60., 100.Hz
|
| 8 |
+
High Pass: 45Hz
|
| 9 |
+
Low Pass: 0.5Hz
|
| 10 |
+
Resample at: 200Hz
|
| 11 |
+
'''
|
| 12 |
+
def preprocessing_eeg(data_path):
|
| 13 |
+
notch = [50., 60., 100.]
|
| 14 |
+
target_fs = 200
|
| 15 |
+
highpass = 0.5
|
| 16 |
+
lowpass = 45
|
| 17 |
+
clip = 500
|
| 18 |
+
streams, header = pyxdf.load_xdf(data_path, verbose=False,
|
| 19 |
+
synchronize_clocks=True, dejitter_timestamps=True,
|
| 20 |
+
select_streams=[{'name': 'Quick-32r_R2_EEG'}])
|
| 21 |
+
# Get sample rate
|
| 22 |
+
fs = float(streams[0]['info']['nominal_srate'][0])
|
| 23 |
+
channel_information = streams[0]["info"]["desc"][0]["channels"][0]["channel"]
|
| 24 |
+
ch_names = [x["label"][0] for x in channel_information][:29]
|
| 25 |
+
|
| 26 |
+
# Get EEG
|
| 27 |
+
x = streams[0]["time_series"][:, :29].T.astype(np.float64) # (channels, time) comes as float32
|
| 28 |
+
|
| 29 |
+
# Filter and clip
|
| 30 |
+
for f_notch in notch:
|
| 31 |
+
if fs / 2 > f_notch:
|
| 32 |
+
[b_notch, a_notch] = signal.iirnotch(w0=f_notch, Q=f_notch / 2, fs=fs)
|
| 33 |
+
x = signal.filtfilt(b_notch, a_notch, x, axis=-1)
|
| 34 |
+
lowpass_applied = min(lowpass, fs / 2) - 0.5
|
| 35 |
+
[b, a] = signal.butter(N=3, Wn=[highpass, lowpass_applied], btype='bandpass', fs=fs)
|
| 36 |
+
x = signal.filtfilt(b, a, x, axis=-1)
|
| 37 |
+
x = x.clip(min=-clip, max=clip)
|
| 38 |
+
# Resampling
|
| 39 |
+
if target_fs != fs:
|
| 40 |
+
x = signal.resample(x, num=int(x.shape[-1] / fs * target_fs), axis=-1)
|
| 41 |
+
# Convert to float16 only after filtering
|
| 42 |
+
x = x.astype('float16')
|
| 43 |
+
x = x.reshape(1, x.shape[0], x.shape[1])
|
| 44 |
+
ch_names = np.array([c.lower().encode() for c in ch_names])
|
| 45 |
+
return x, ch_names
|
| 46 |
+
|
| 47 |
+
'''
|
| 48 |
+
Function to create patches for NeuroRVQ
|
| 49 |
+
'''
|
| 50 |
+
def create_patches(eeg_signal, maximum_patches, patch_size, channels_use):
|
| 51 |
+
n, c, t = eeg_signal.shape # Batch / trials, channels, time
|
| 52 |
+
n_time = (maximum_patches // len(channels_use))
|
| 53 |
+
eeg_signal = eeg_signal[:, :, :n_time * patch_size]
|
| 54 |
+
eeg_signal_patches = eeg_signal[:, channels_use, :]
|
| 55 |
+
return eeg_signal_patches, n_time
|
pretrained_models/foundation_models/NeuroRVQ_EEG_foundation_model_v1.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d14ef4eae2d4594d5f1f709226a3bb5f362afd84b68050d5da0fa0586aea886a
|
| 3 |
+
size 234352952
|
pretrained_models/tokenizers/NeuroRVQ_EEG_tokenizer_v1.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d3e850e160b1a558c529466b1c0b8cebe8888a5e02824979886dd226187b2725
|
| 3 |
+
size 304130106
|
requirements.txt
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This file may be used to create an environment using:
|
| 2 |
+
# $ conda create --name <env> --file <this file>
|
| 3 |
+
# platform: linux-64
|
| 4 |
+
# created-by: conda 25.3.1
|
| 5 |
+
_libgcc_mutex=0.1=main
|
| 6 |
+
_openmp_mutex=5.1=1_gnu
|
| 7 |
+
attrs=25.3.0=pypi_0
|
| 8 |
+
blas=1.0=mkl
|
| 9 |
+
bottleneck=1.4.2=py311hf4808d0_0
|
| 10 |
+
brotli-python=1.0.9=py311h6a678d5_9
|
| 11 |
+
bzip2=1.0.8=h5eee18b_6
|
| 12 |
+
c-ares=1.19.1=h5eee18b_0
|
| 13 |
+
ca-certificates=2025.2.25=h06a4308_0
|
| 14 |
+
certifi=2025.4.26=py311h06a4308_0
|
| 15 |
+
charset-normalizer=3.3.2=pyhd3eb1b0_0
|
| 16 |
+
clearml=1.18.0=pypi_0
|
| 17 |
+
contourpy=1.3.1=py311hdb19cb5_0
|
| 18 |
+
cuda-cudart=11.8.89=0
|
| 19 |
+
cuda-cupti=11.8.87=0
|
| 20 |
+
cuda-libraries=11.8.0=0
|
| 21 |
+
cuda-nvrtc=11.8.89=0
|
| 22 |
+
cuda-nvtx=11.8.86=0
|
| 23 |
+
cuda-runtime=11.8.0=0
|
| 24 |
+
cuda-version=12.9=3
|
| 25 |
+
cycler=0.11.0=pyhd3eb1b0_0
|
| 26 |
+
cyrus-sasl=2.1.28=h52b45da_1
|
| 27 |
+
decorator=5.2.1=pypi_0
|
| 28 |
+
einops=0.8.1=pypi_0
|
| 29 |
+
expat=2.7.1=h6a678d5_0
|
| 30 |
+
ffmpeg=4.3=hf484d3e_0
|
| 31 |
+
filelock=3.17.0=py311h06a4308_0
|
| 32 |
+
fontconfig=2.14.1=h55d465d_3
|
| 33 |
+
fonttools=4.55.3=py311h5eee18b_0
|
| 34 |
+
freetype=2.13.3=h4a9f257_0
|
| 35 |
+
furl=2.1.4=pypi_0
|
| 36 |
+
giflib=5.2.2=h5eee18b_0
|
| 37 |
+
gmp=6.3.0=h6a678d5_0
|
| 38 |
+
gmpy2=2.2.1=py311h5eee18b_0
|
| 39 |
+
gnutls=3.6.15=he1e5248_0
|
| 40 |
+
h5py=3.12.1=py311h5842655_1
|
| 41 |
+
hdf5=1.14.5=h2b7332f_2
|
| 42 |
+
icu=73.1=h6a678d5_0
|
| 43 |
+
idna=3.7=py311h06a4308_0
|
| 44 |
+
intel-openmp=2023.1.0=hdb19cb5_46306
|
| 45 |
+
jinja2=3.1.6=py311h06a4308_0
|
| 46 |
+
joblib=1.4.2=py311h06a4308_0
|
| 47 |
+
jpeg=9e=h5eee18b_3
|
| 48 |
+
jsonschema=4.23.0=pypi_0
|
| 49 |
+
jsonschema-specifications=2025.4.1=pypi_0
|
| 50 |
+
kiwisolver=1.4.8=py311h6a678d5_0
|
| 51 |
+
krb5=1.20.1=h143b758_1
|
| 52 |
+
lame=3.100=h7b6447c_0
|
| 53 |
+
lazy-loader=0.4=pypi_0
|
| 54 |
+
lcms2=2.16=h92b89f2_1
|
| 55 |
+
ld_impl_linux-64=2.40=h12ee557_0
|
| 56 |
+
lerc=4.0.0=h6a678d5_0
|
| 57 |
+
libabseil=20250127.0=cxx17_h6a678d5_0
|
| 58 |
+
libcublas=11.11.3.6=0
|
| 59 |
+
libcufft=10.9.0.58=0
|
| 60 |
+
libcufile=1.14.0.30=4
|
| 61 |
+
libcups=2.4.2=h2d74bed_1
|
| 62 |
+
libcurand=10.3.10.19=0
|
| 63 |
+
libcurl=8.12.1=hc9e6f67_0
|
| 64 |
+
libcusolver=11.4.1.48=0
|
| 65 |
+
libcusparse=11.7.5.86=0
|
| 66 |
+
libdeflate=1.22=h5eee18b_0
|
| 67 |
+
libedit=3.1.20230828=h5eee18b_0
|
| 68 |
+
libev=4.33=h7f8727e_1
|
| 69 |
+
libffi=3.4.4=h6a678d5_1
|
| 70 |
+
libgcc-ng=11.2.0=h1234567_1
|
| 71 |
+
libgfortran-ng=11.2.0=h00389a5_1
|
| 72 |
+
libgfortran5=11.2.0=h1234567_1
|
| 73 |
+
libglib=2.78.4=hdc74915_0
|
| 74 |
+
libgomp=11.2.0=h1234567_1
|
| 75 |
+
libiconv=1.16=h5eee18b_3
|
| 76 |
+
libidn2=2.3.4=h5eee18b_0
|
| 77 |
+
libjpeg-turbo=2.0.0=h9bf148f_0
|
| 78 |
+
libnghttp2=1.57.0=h2d74bed_0
|
| 79 |
+
libnpp=11.8.0.86=0
|
| 80 |
+
libnvjpeg=11.9.0.86=0
|
| 81 |
+
libpng=1.6.39=h5eee18b_0
|
| 82 |
+
libpq=17.4=hdbd6064_0
|
| 83 |
+
libprotobuf=5.29.3=hc99497a_0
|
| 84 |
+
libssh2=1.11.1=h251f7ec_0
|
| 85 |
+
libstdcxx-ng=11.2.0=h1234567_1
|
| 86 |
+
libtasn1=4.19.0=h5eee18b_0
|
| 87 |
+
libtiff=4.7.0=hde9077f_0
|
| 88 |
+
libunistring=0.9.10=h27cfd23_0
|
| 89 |
+
libuuid=1.41.5=h5eee18b_0
|
| 90 |
+
libwebp=1.3.2=h9f374a3_1
|
| 91 |
+
libwebp-base=1.3.2=h5eee18b_1
|
| 92 |
+
libxcb=1.17.0=h9b100fa_0
|
| 93 |
+
libxkbcommon=1.9.1=h69220b7_0
|
| 94 |
+
libxml2=2.13.8=hfdd30dd_0
|
| 95 |
+
llvm-openmp=14.0.6=h9e868ea_0
|
| 96 |
+
lz4-c=1.9.4=h6a678d5_1
|
| 97 |
+
markupsafe=3.0.2=py311h5eee18b_0
|
| 98 |
+
matplotlib=3.10.0=py311h06a4308_0
|
| 99 |
+
matplotlib-base=3.10.0=py311hbfdbfaf_0
|
| 100 |
+
mkl=2023.1.0=h213fc3f_46344
|
| 101 |
+
mkl-service=2.4.0=py311h5eee18b_2
|
| 102 |
+
mkl_fft=1.3.11=py311h5eee18b_0
|
| 103 |
+
mkl_random=1.2.8=py311ha02d727_0
|
| 104 |
+
mne=1.9.0=pypi_0
|
| 105 |
+
mpc=1.3.1=h5eee18b_0
|
| 106 |
+
mpfr=4.2.1=h5eee18b_0
|
| 107 |
+
mpmath=1.3.0=py311h06a4308_0
|
| 108 |
+
mysql=8.4.0=h721767e_2
|
| 109 |
+
ncurses=6.4=h6a678d5_0
|
| 110 |
+
nettle=3.7.3=hbbd107a_1
|
| 111 |
+
networkx=3.4.2=py311h06a4308_0
|
| 112 |
+
numexpr=2.10.1=py311h3c60e43_0
|
| 113 |
+
numpy=2.0.1=py311h08b1b3b_1
|
| 114 |
+
numpy-base=2.0.1=py311hf175353_1
|
| 115 |
+
openh264=2.1.1=h4ff587b_0
|
| 116 |
+
openjpeg=2.5.2=h0d4d230_1
|
| 117 |
+
openldap=2.6.4=h42fbc30_0
|
| 118 |
+
openssl=3.0.16=h5eee18b_0
|
| 119 |
+
orderedmultidict=1.0.1=pypi_0
|
| 120 |
+
packaging=24.2=py311h06a4308_0
|
| 121 |
+
pandas=2.2.3=py311h6a678d5_0
|
| 122 |
+
pathlib2=2.3.7.post1=pypi_0
|
| 123 |
+
pcre2=10.42=hebb0a14_1
|
| 124 |
+
pillow=11.1.0=py311hac6e08b_1
|
| 125 |
+
pip=25.1=pyhc872135_2
|
| 126 |
+
platformdirs=4.3.8=pypi_0
|
| 127 |
+
pooch=1.8.2=pypi_0
|
| 128 |
+
psutil=5.9.0=py311h5eee18b_1
|
| 129 |
+
pthread-stubs=0.3=h0ce48e5_1
|
| 130 |
+
pyjwt=2.9.0=pypi_0
|
| 131 |
+
pyparsing=3.2.0=py311h06a4308_0
|
| 132 |
+
pyqt=6.7.1=py311h6a678d5_1
|
| 133 |
+
pyqt6-sip=13.9.1=py311h5eee18b_1
|
| 134 |
+
pysocks=1.7.1=py311h06a4308_0
|
| 135 |
+
python=3.11.11=he870216_0
|
| 136 |
+
python-dateutil=2.9.0post0=py311h06a4308_2
|
| 137 |
+
python-tzdata=2025.2=pyhd3eb1b0_0
|
| 138 |
+
pytorch=2.5.1=py3.11_cuda11.8_cudnn9.1.0_0
|
| 139 |
+
pytorch-cuda=11.8=h7e8668a_6
|
| 140 |
+
pytorch-mutex=1.0=cuda
|
| 141 |
+
pytz=2024.1=py311h06a4308_0
|
| 142 |
+
pyyaml=6.0.2=py311h5eee18b_0
|
| 143 |
+
qtbase=6.7.3=hdaa5aa8_0
|
| 144 |
+
qtdeclarative=6.7.3=h6a678d5_0
|
| 145 |
+
qtsvg=6.7.3=he621ea3_0
|
| 146 |
+
qttools=6.7.3=h80c7b02_0
|
| 147 |
+
qtwebchannel=6.7.3=h6a678d5_0
|
| 148 |
+
qtwebsockets=6.7.3=h6a678d5_0
|
| 149 |
+
readline=8.2=h5eee18b_0
|
| 150 |
+
referencing=0.36.2=pypi_0
|
| 151 |
+
requests=2.32.3=py311h06a4308_1
|
| 152 |
+
rpds-py=0.25.0=pypi_0
|
| 153 |
+
scikit-learn=1.6.1=py311h6a678d5_0
|
| 154 |
+
scipy=1.15.3=py311h525edd1_0
|
| 155 |
+
setuptools=78.1.1=py311h06a4308_0
|
| 156 |
+
sip=6.10.0=py311h6a678d5_0
|
| 157 |
+
six=1.17.0=py311h06a4308_0
|
| 158 |
+
sqlite=3.45.3=h5eee18b_0
|
| 159 |
+
sympy=1.13.3=py311h06a4308_1
|
| 160 |
+
tbb=2021.8.0=hdb19cb5_0
|
| 161 |
+
threadpoolctl=3.5.0=py311h92b7b1e_0
|
| 162 |
+
tk=8.6.14=h39e8969_0
|
| 163 |
+
torchaudio=2.5.1=py311_cu118
|
| 164 |
+
torchtriton=3.1.0=py311
|
| 165 |
+
torchvision=0.20.1=py311_cu118
|
| 166 |
+
tornado=6.4.2=py311h5eee18b_0
|
| 167 |
+
tqdm=4.67.1=py311h92b7b1e_0
|
| 168 |
+
typing_extensions=4.12.2=py311h06a4308_0
|
| 169 |
+
tzdata=2025b=h04d1e81_0
|
| 170 |
+
unicodedata2=15.1.0=py311h5eee18b_1
|
| 171 |
+
urllib3=2.3.0=py311h06a4308_0
|
| 172 |
+
wheel=0.45.1=py311h06a4308_0
|
| 173 |
+
xcb-util=0.4.1=h5eee18b_2
|
| 174 |
+
xcb-util-cursor=0.1.5=h5eee18b_0
|
| 175 |
+
xcb-util-image=0.4.0=h5eee18b_2
|
| 176 |
+
xcb-util-renderutil=0.3.10=h5eee18b_0
|
| 177 |
+
xkeyboard-config=2.44=h5eee18b_0
|
| 178 |
+
xorg-libx11=1.8.12=h9b100fa_1
|
| 179 |
+
xorg-libxau=1.0.12=h9b100fa_0
|
| 180 |
+
xorg-libxdmcp=1.1.5=h9b100fa_0
|
| 181 |
+
xorg-xorgproto=2024.1=h5eee18b_1
|
| 182 |
+
xz=5.6.4=h5eee18b_1
|
| 183 |
+
yaml=0.2.5=h7b6447c_0
|
| 184 |
+
zlib=1.2.13=h5eee18b_1
|
| 185 |
+
zstd=1.5.6=hc292b87_0
|
| 186 |
+
numpy
|
| 187 |
+
pandas
|
| 188 |
+
skorch==0.15.0
|
| 189 |
+
braindecode==0.8.1
|