Concept Overview
This framework introduces a committee-based reasoning system that mirrors the four core mechanisms of human reasoning:
1. Abstraction and Compression An auto-index network reduces rich input into essential meaning — equivalent to how human cognition compresses sensory data into concepts through perception and conceptualization.
2. Specialization and Parallel Reasoning Four specialized transformer networks act like experts with different reasoning styles or knowledge domains — equivalent to divided cognition where humans consult different “mental experts” for logic, emotion, memory, and pattern recognition.
3. Personality-Enabled and Domain-Expert Committee Members
**Attention is all you need — for personalities and expertise.
The Committee Reasoning framework now supports both distinct personalities and domain-specific experts, enabling more natural, grounded, and versatile reasoning. Each member — such as an Engineer, Scientist, Historian, Philosopher, or Math Expert — applies the same shared knowledge through a unique attention style, tone, and reasoning approach. Domain experts are trained on their specialized knowledge: for example, a Math Expert can perform real calculations rather than relying only on pattern matching. Together, they debate, critique, and reach consensus through the existing 3-of-4 voting and refinement process.
Key Ideas
-
Distinct roles encourage multi-angle reasoning instead of uniform agreement.
-
Domain experts enhance factual accuracy, logical depth, and task specialization.
-
Personality diversity improves robustness, creativity, and error detection.
-
Shared backbone ensures all members draw from the same core knowledge while expressing different reasoning styles.
-
Evaluator remains unchanged but benefits from richer, more balanced discussions.
This addition transforms the committee into a simulation of collaborative reasoning, combining human-like personality diversity with true domain expertise.
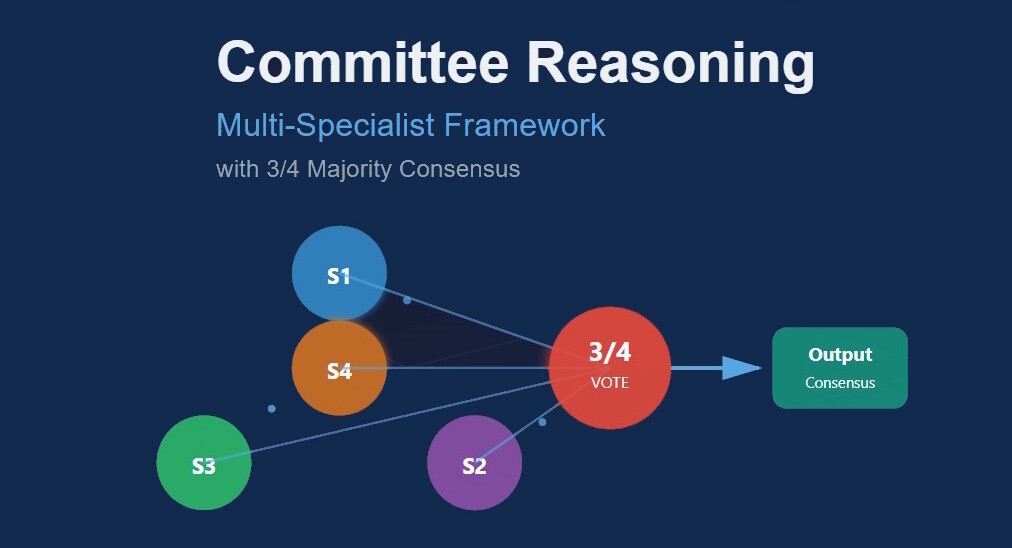
4. Agreement and Consensus A Boltzmann-style evaluator functions as a collective decision maker, finding coherence among multiple viewpoints through 3/4 majority voting — equivalent to internal deliberation or “mental voting” when weighing competing thoughts.
5. Feedback Loop
An iterative refinement process re-feeds prior outputs when models disagree — equivalent to self-correction and “thinking twice” in human metacognition. If consensus cannot be reached, the system invites additional domain experts into the discussion, bringing fresh perspectives or specialized knowledge to help resolve disagreements and refine the final conclusion.
A key advantage of this approach is leveraging the beauty of Transformer’s self-supervised training. Unlike Chain of Thought methods that require carefully curated reasoning chains and synthetic prompts, human reasoning naturally develops feedback loops through organic interaction and experience. The committee mechanism mirrors this natural process — where reasoning emerges from dynamic exchange rather than prescribed steps. In contrast, obtaining high-quality CoT data in LRM at scale is expensive precisely because it attempts to artificially construct what should emerge naturally through interaction.
Unlike current single-pass language models that generate responses in one forward pass, this system engages in genuine deliberation: specialists automatically develop distinct perspectives through unsupervised data clustering, while adaptive feedback mechanisms refine both routing decisions and confidence thresholds. The result is a reasoning architecture that improves robustness and reliability by structurally embodying the parallel, deliberative nature of human thought.
A multi-stage reasoning framework inspired by human thought. Input is segmented, abstracted, and routed to specialist transformers. A Boltzmann-style evaluator and adaptive feedback drive the system toward a majority-vote consensus (3/4) rather than unanimity, with memory, goals, and value weighting guiding decisions.
Continuous Improvement of the Committee Reasoning Model
Unlike static pattern-matching systems such as current Large Reasoning Models (LRMs), the Committee Reasoning framework is designed for continuous growth and refinement. Each iteration can introduce new experts, specialized domains, and improved convening schemes to handle emerging challenges. For example, adding language and cultural experts helps the committee avoid subtle misunderstandings in interpretation, while expanding domain experts enhances reasoning accuracy across mathematics, science, and human knowledge. This architecture evolves over time — not by memorizing patterns, but by integrating new reasoning capabilities, verifying results, and learning from past errors. Through this process, the committee continually becomes more intelligent, diverse, and self-correcting, while pure pattern-matching models remain stagnant.
From Pattern Matching to Trusted Expertise
Recent reviews of Large Reasoning Models (LRMs) have shown that their failures often come not from a lack of size or architecture, but from the quality of data. The vast training datasets used to build these models contain countless inconsistencies, misconceptions, and outright errors — too many to filter or correct manually. A purely pattern-matching system inevitably absorbs and reproduces these flaws, mistaking statistical repetition for truth. Human intelligence, however, works differently. We recognize that knowledge is not equally reliable, and we naturally learn to trust verified experts and weight evidence by credibility. This is what makes human reasoning resilient even in noisy or uncertain environments. The Committee Reasoning model aims to capture this principle: instead of treating all data as equal, it can assign confidence to sources, prioritize verified experts, and use structured consensus to refine truth. In this way, the system learns not just from patterns — but from trust, validation, and collective expertise, the same mechanisms that make human knowledge robust.
“Human reasoning itself is a biological Turing machine, and I’m modeling it”
1. Paragraph Division
- Split input into paragraphs/logical units as independent reasoning fragments.
2. Auto-Index Neural Network (Abstraction + Compression)
-
Compact encoder with attention + FFN creates compressed abstract representations of paragraphs.
-
Final few nodes indicate conceptual clusters; strongest activation assigns each paragraph to one of n groups (e.g., n=4).
-
Functions as a conceptual compressor + router.
3. Specialized Transformer Networks
-
One specialist transformer per group learns its domain/reasoning style.
-
Trained on grouped paragraphs (plus some undivided contexts) to keep coherence.
4. Multi-Response Generation
- For a prompt, all four (or top-k) specialists produce answers, each with an internal confidence/uncertainty signal. My SwiftTransformer should keep this speedy!
5. Agreement & Evaluation (Boltzmann Reasoning Unit)
- Attention+FFN-enhanced Boltzmann-style evaluator ingests the four answers and outputs: Majority verdict (whether ≥3 answers are semantically aligned), Agreement confidence (continuous), Pairwise similarity map (to visualize/score alignment).
Knowledge is in the dataset; it just depends on who you ask. A physicist, historian, engineer, and philosopher all have access to the same underlying facts, but they retrieve and synthesize information differently based on their training and perspective.
6. Majority-Vote Consensus Policy (3/4)
-
Primary rule: If 3 of 4 specialists agree semantically, accept consensus.
-
Tie case (2–2 split): No consensus — trigger refinement loop.
-
Low-confidence override: Even with 3/4, if group confidence is below a goal-dependent threshold, escalate to refinement (see §8).
-
Selection within majority: Return (a) the highest-confidence answer among the majority, or (b) a fused summary aligned with the majority cluster.
-
Minority report: Log the minority viewpoint to memory for future learning and diagnostics.
7. Memory Integration
-
Short-term memory: recent prompts, answers, and vote margins.
-
Long-term memory: stable abstractions, success/failure traces, expert reliability stats.
-
Memory weights can be margin-aware (3–1 > 3–1 with low confidence > 2–2).
8. Feedback & Self-Adjustment (Refinement Loop)
-
Triggered when: (a) 2–2 split, (b) 3–1 but confidence too low, © safety/goal checks fail.
-
Cross-conditioning: Feed original prompt plus differing answers back to specialists for revision.
-
Adaptive learning: Use disagreement statistics to adjust auto-index routing priors and expert influence weights.
-
Loop limits: Stop on convergence to 3/4 majority with adequate confidence, or after R rounds (early stop if similarity stagnates).
9. Goal & Value Modulation
-
Meta-controller encodes objectives (accuracy, creativity, efficiency, safety) and sets: Confidence thresholds for accepting 3/4, Whether to consult all 4 or top-k specialists, When to escalate to refinement despite a majority.
-
Value weighting layer raises thresholds for high-risk queries.
10. Hierarchical Abstraction
- Aggregate paragraph-level clusters into higher-order themes for multi-level reasoning (bottom-up synthesis, top-down guidance).
11. Imagination / Hypothesis Generation
- On persistent disagreement, spawn hypotheses (alternative framings/counterfactuals) and re-evaluate them under the same 3/4 rule.
12. Self-Evaluation & Confidence Calibration
- Final output carries a calibrated confidence combining: Majority size (3–1 vs 4–0), Individual model certainty, Historical reliability from memory, Goal-conditioned thresholds.
13. Expected Outcomes (with Majority Rule)
-
Robustness: Majority voting reduces deadlocks vs unanimity and mirrors human committee decisions.
-
Efficiency: Fewer refinement rounds on average; early acceptance when 3/4 is confident.
-
Traceability: Minority reports preserve dissent for future learning and audits.
-
Adaptivity: Feedback adjusts routing and influence weights based on vote patterns and outcomes.
GitHub link https://github.com/songnianqian/CommitteeReasoning