

Upload folder using huggingface_hub
Browse files
.gitattributes
CHANGED
|
@@ -34,3 +34,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
figure/before_after_train_lcb_02.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
figure/benchmark_accuracy_1130.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
figure/inference_pipeline_teaser_02.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
figure/teaser_draft_02.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
figure/train_reward_response_length_1130.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
|
| 5 |
+
[**Read the Paper**](https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf) | [**Download Models**](https://huggingface.co/stepfun-ai/PaCoRe-8B) | [**Training Data**](https://huggingface.co/datasets/stepfun-ai/PaCoRe-Train-8k)
|
| 6 |
+
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
## 📖 Overview
|
| 10 |
+
|
| 11 |
+
We introduce **PaCoRe (Parallel Coordinated Reasoning)**, a framework that shifts the driver of inference from sequential depth to **coordinated parallel breadth**, breaking the model context limitation and massively scaling test time compute:
|
| 12 |
+
* **Think in Parallel:** PaCoRe launches massive parallel exploration trajectories.
|
| 13 |
+
* **Coordinate in Multi-rounds:** It employs a message-passing architecture to compact these thoughts into concise messages and synthesize them to guide the next round.
|
| 14 |
+
|
| 15 |
+
Trained via large-scale, outcome-based reinforcement learning, PaCoRe masters the **Reasoning Synthesis** capabilities required to reconcile diverse parallel insights.
|
| 16 |
+
|
| 17 |
+
The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5\% on HMMT 2025, surpassing GPT-5’s 93.2\% by scaling effective TTC to roughly two million tokens.
|
| 18 |
+
|
| 19 |
+
We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work!
|
| 20 |
+
|
| 21 |
+
------
|
| 22 |
+
|
| 23 |
+
<p align="center">
|
| 24 |
+
<img src="figure/teaser_draft_02.png" width="48%" />
|
| 25 |
+
<img src="figure/before_after_train_lcb_02.png" width="48%" />
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
*Figure 1 | Parallel Coordinated Reasoning (PaCoRe) performance. Left: On HMMT 2025, PaCoRe-8B demonstrates remarkable test-time scaling, yielding steady gains and ultimately surpassing GPT-5. Right: On LiveCodeBench, the RLVR-8B model fails to leverage increased test-time compute, while PaCoRe-8B model effectively unlocks substantial gains as the test-time compute increases.*
|
| 29 |
+
|
| 30 |
+
<p align="center">
|
| 31 |
+
<img src="figure/train_reward_response_length_1130.png" width="48%" />
|
| 32 |
+
<img src="figure/benchmark_accuracy_1130.png" width="48%" />
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
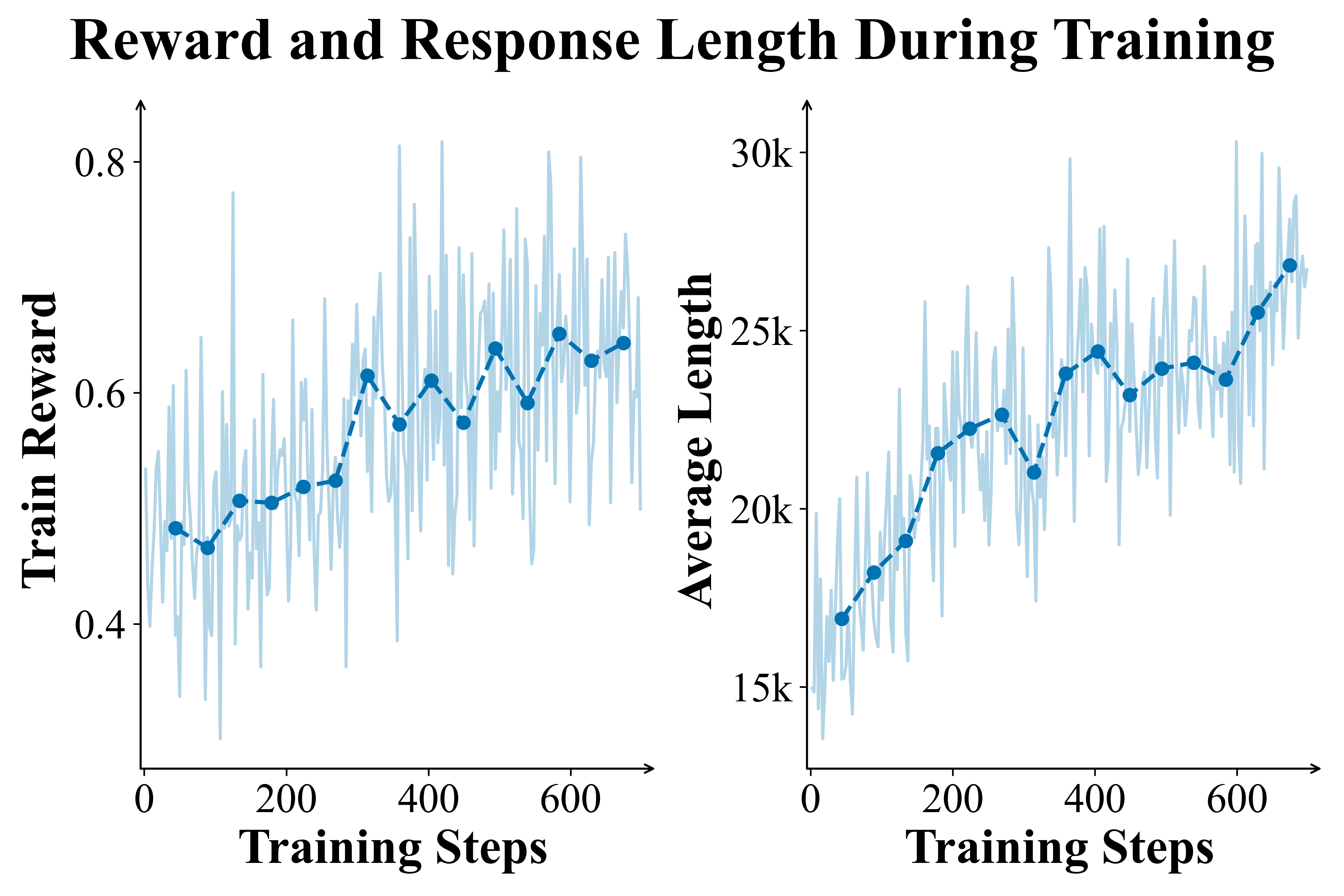
*Figure 2 | PaCoRe Training dynamics. Left panels: The Training Reward and Response Length steadily increase, demonstrating the training stability and effectiveness. Right panels: Evaluation on HMMT 2025 and LiveCodeBench (2408-2505). Performance is reported using single round coordinated reasoning in PaCoRe inference setting with $\vec{K} = [16]$.*
|
| 36 |
+
|
| 37 |
+
## 🔥 Releases
|
| 38 |
+
|
| 39 |
+
**[2025/12/09]** We are excited to release the **PaCoRe-8B** ecosystem:
|
| 40 |
+
|
| 41 |
+
* 📝 **In-depth Technical Report:** [**PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning.**](https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf)
|
| 42 |
+
* 🤖 **Model:**
|
| 43 |
+
* [PaCoRe-8B](https://huggingface.co/stepfun-ai/PaCoRe-8B): Our final PaCoRe-trained model checkpoint!
|
| 44 |
+
* [RLVR-8B-0926](https://huggingface.co/stepfun-ai/RLVR-8B-0926): The initial checkpoint of our study, conducted strong reasoning-oriented post-trained on [Qwen3-8B-Base](https://huggingface.co/Qwen/Qwen3-8B-Base).
|
| 45 |
+
* 📚 **Data:** [PaCoRe-Train-8k](https://huggingface.co/datasets/stepfun-ai/PaCoRe-Train-8k) The high-quality training corpus, including `opensource_math`, `public_mathcontest`, `synthetic_math` and `code`:
|
| 46 |
+
* 🤗 Stage1-3k: [PaCoRe-Train-Stage1-3k](https://huggingface.co/datasets/stepfun-ai/PaCoRe-Train-8k/stage1)
|
| 47 |
+
* 🤗 Stage2-5k: [PaCoRe-Train-Stage2-5k](https://huggingface.co/datasets/stepfun-ai/PaCoRe-Train-8k/stage2)
|
| 48 |
+
|
| 49 |
+
## 🔍 Experiments
|
| 50 |
+
|
| 51 |
+
<table class="tg">
|
| 52 |
+
<thead>
|
| 53 |
+
<tr>
|
| 54 |
+
<th class="tg-header"></th>
|
| 55 |
+
<th class="tg-data">HMMT 2025</th>
|
| 56 |
+
<th class="tg-data">LiveCodeBench</th>
|
| 57 |
+
<th class="tg-data">HLE<sub>text</sub></th>
|
| 58 |
+
<th class="tg-data">MultiChallenge</th>
|
| 59 |
+
</tr>
|
| 60 |
+
</thead>
|
| 61 |
+
<tbody>
|
| 62 |
+
<tr>
|
| 63 |
+
<td class="tg-header">GPT-5</td>
|
| 64 |
+
<td class="tg-data">93.2 (16k)</td>
|
| 65 |
+
<td class="tg-data"><b>83.5</b> (13k)</td>
|
| 66 |
+
<td class="tg-data"><b>26.0</b> (14k)</td>
|
| 67 |
+
<td class="tg-data"><b>71.1</b> (5.0k)</td>
|
| 68 |
+
</tr>
|
| 69 |
+
<tr>
|
| 70 |
+
<td class="tg-header">Qwen3-235B-Thinking</td>
|
| 71 |
+
<td class="tg-data">82.3 (32k)</td>
|
| 72 |
+
<td class="tg-data">74.5 (21k)</td>
|
| 73 |
+
<td class="tg-data">18.2 (23k)</td>
|
| 74 |
+
<td class="tg-data">60.3 (1.6k)</td>
|
| 75 |
+
</tr>
|
| 76 |
+
<tr>
|
| 77 |
+
<td class="tg-header">GLM-4.6</td>
|
| 78 |
+
<td class="tg-data">88.7 (25k)</td>
|
| 79 |
+
<td class="tg-data">79.5 (19k)</td>
|
| 80 |
+
<td class="tg-data">17.2 (21k)</td>
|
| 81 |
+
<td class="tg-data">54.9 (2.2k)</td>
|
| 82 |
+
</tr>
|
| 83 |
+
<tr>
|
| 84 |
+
<td class="tg-header">DeepSeek-v3.1-Terminus</td>
|
| 85 |
+
<td class="tg-data">86.1 (20k)</td>
|
| 86 |
+
<td class="tg-data">74.9 (11k)</td>
|
| 87 |
+
<td class="tg-data">19.3 (18k)</td>
|
| 88 |
+
<td class="tg-data">54.4 (1.1k)</td>
|
| 89 |
+
</tr>
|
| 90 |
+
<tr class="tg-midrule">
|
| 91 |
+
<td class="tg-header">Kimi-K2-Thinking</td>
|
| 92 |
+
<td class="tg-data">86.5 (33k)</td>
|
| 93 |
+
<td class="tg-data">79.2 (25k)</td>
|
| 94 |
+
<td class="tg-data">23.9 (29k)</td>
|
| 95 |
+
<td class="tg-data">66.4 (1.7k)</td>
|
| 96 |
+
</tr>
|
| 97 |
+
|
| 98 |
+
<tr class="tg-midrule">
|
| 99 |
+
<td class="tg-header">RLVR-8B</td>
|
| 100 |
+
<td class="tg-data">75.4 (48k)</td>
|
| 101 |
+
<td class="tg-data">70.6 (34k)</td>
|
| 102 |
+
<td class="tg-data">9.3 (35k)</td>
|
| 103 |
+
<td class="tg-data">33.3 (1.7k)</td>
|
| 104 |
+
</tr>
|
| 105 |
+
|
| 106 |
+
<tr>
|
| 107 |
+
<td class="tg-header"><b>PaCoRe-8B (low)</b></td>
|
| 108 |
+
<td class="tg-data">88.2 (243k)</td>
|
| 109 |
+
<td class="tg-data">75.8 (188k)</td>
|
| 110 |
+
<td class="tg-data">13.0 (196k)</td>
|
| 111 |
+
<td class="tg-data">41.8 (13k)</td>
|
| 112 |
+
</tr>
|
| 113 |
+
<tr>
|
| 114 |
+
<td class="tg-header"><b>PaCoRe-8B (medium)</b></td>
|
| 115 |
+
<td class="tg-data">92.9 (869k)</td>
|
| 116 |
+
<td class="tg-data">76.7 (659k)</td>
|
| 117 |
+
<td class="tg-data">14.6 (694k)</td>
|
| 118 |
+
<td class="tg-data">45.7 (45k)</td>
|
| 119 |
+
</tr>
|
| 120 |
+
<tr class="tg-bottom">
|
| 121 |
+
<td class="tg-header"><b>PaCoRe-8B (high)</b></td>
|
| 122 |
+
<td class="tg-data"><b>94.5</b> (1796k)</td>
|
| 123 |
+
<td class="tg-data">78.2 (1391k)</td>
|
| 124 |
+
<td class="tg-data">16.2 (1451k)</td>
|
| 125 |
+
<td class="tg-data">47.0 (95k)</td>
|
| 126 |
+
</tr>
|
| 127 |
+
</tbody>
|
| 128 |
+
</table>
|
| 129 |
+
|
| 130 |
+
*Table 1 | For each benchmark, we report accuracy together with total TTC (in thousands). For *Low*, *Medium*, and *High*, we apply the inference trajectory configuration as $\vec{K}=[4]$, $[16]$, and $[32, 4]$ separately.*
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
### Key Findings
|
| 134 |
+
* **Message Passing Unlocks Scaling.** Without compaction, performance flatlines at the context limit. PaCoRe breaks the memory barrier and lets reasoning scale freely.
|
| 135 |
+
* **Breadth > Depth.** All compute is not equal. Coordinated parallel reasoning delivers far higher returns than extending a single chain.
|
| 136 |
+
* **Data as a Force Multiplier.** The PaCoRe corpus provides exceptionally valuable supervision—even baseline models see substantial gains when trained on it.
|
| 137 |
+
|
| 138 |
+
## Getting Started 🚀
|
| 139 |
+
### Data
|
| 140 |
+
The data is provided as a `list[dict]`, where each entry represents a training instance:
|
| 141 |
+
* `conversation`: The original problem/prompt messages.
|
| 142 |
+
* `responses`: A list of cached generated responses (trajectories). These serve as the **input messages ($M$)** used during PaCoRe training.
|
| 143 |
+
* `ground_truth`: The verifiable answer used for correctness evaluation.
|
| 144 |
+
|
| 145 |
+
### Model Serving
|
| 146 |
+
You can directly use `vllm serve` to serve the model! More inference details of PaCoRe will be handled in Inference Pipeline.
|
| 147 |
+
|
| 148 |
+
### Inference Pipeline
|
| 149 |
+

|
| 150 |
+
|
| 151 |
+
*Figure 3 | Inference pipeline of PaCoRe. Each round launches broad parallel exploration, compacts the resulting trajectories into compacted messages, and feeds these messages together with the question forward to coordinate the next round. Repeating this process $\hat{R}$ times yields multi-million-token effective TTC while respecting fixed context limits, with the final compacted message serving as the system’s answer.*
|
| 152 |
+
|
| 153 |
+
Inference code coming soon!
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
## 🙏 Acknowledgements
|
| 157 |
+
- This work was supported by computing resources and infrastructure provided by [StepFun](https://www.stepfun.com/) and Tsinghua University.
|
| 158 |
+
- We are deeply grateful to our colleagues for their support:
|
| 159 |
+
* Inference: Song Yuan, Wuxun Xie, Mingliang Li, Bojun Wang.
|
| 160 |
+
* Training: Xing Chen, Yuanwei Lu, Changyi Wan, Yu Zhou.
|
| 161 |
+
* Infra Operations: Shaoliang Pang, Changxin Miao, Xu Zhao, Wei Zhang, Zidong Yang, Junzhe Lin, Yuxiang Yang, Chen Xu, Xin Li, Bin Wang.
|
| 162 |
+
* Data Management: Xiaoxiao Ren, Zhiguo Huang, and Kang An.
|
| 163 |
+
* Helpful Discussions: Liang Zhao, Jianjian Sun, Zejia Weng, JingJing Xie.
|
| 164 |
+
- We are grateful for colleagues from StepFun and Tsinghua University for their valuable feedback and contributions.
|
| 165 |
+
- Our work is built on amazing open source models and data; thanks again!
|
| 166 |
+
|
| 167 |
+
## 🔮 Future Work
|
| 168 |
+
We are just scratching the surface of parallel coordinated reasoning. Our roadmap includes:
|
| 169 |
+
- **Scaling the Extremes**: We plan to apply PaCoRe to stronger foundation models, expanding the task domains, and further scaling up both the breadth (parallel trajectories) and depth (coordination rounds) to tackle challenges currently deemed unsolvable.
|
| 170 |
+
- **Boosting Token Intelligence Density**: While we currently scale by volume, we aim to maximize the utility of every unit of compute spent. This involves enabling more efficient parallel exploration through better organization, cooperation, and division of labor among trajectories.
|
| 171 |
+
- **Emergent Multi-Agent Intelligence**: We are interested in exploring the joint training of both the synthesis policy and the message-passing mechanism, laying minimal yet rich cooperative multi-agent learning environment, offering a valuable playground for studying emergent communication, self-organization, and collective intelligence.
|
| 172 |
+
- **Ouroboros for Pre- and Post-Training**: we intend to investigate the development of advanced synthetic data generation techniques with PaCoRe pipeline to improve both current pretraining and post-training processes.
|
| 173 |
+
|
| 174 |
+
## Advertisement Time 📣
|
| 175 |
+
We are currently seeking self-motivated engineers and reseachers.
|
| 176 |
+
If you are interested in our project and would like to contribute to the reasoner scale-up all the way to AGI, please feel free to reach out to us at [email protected]
|
| 177 |
+
|
| 178 |
+
## 📜 Citation
|
| 179 |
+
|
| 180 |
+
```bibtex
|
| 181 |
+
@misc{pacore2025,
|
| 182 |
+
title={PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning},
|
| 183 |
+
author={Jingcheng Hu and Yinmin Zhang and Shijie Shang and Xiaobo Yang and Yue Peng and Zhewei Huang and Hebin Zhou and Xin Wu and Jie Cheng and Fanqi Wan and Xiangwen Kong and Chengyuan Yao and Ailin Huang and Hongyu Zhou and Qi Han and Zheng Ge and Daxin Jiang and Xiangyu Zhang and Heung-Yeung Shum},
|
| 184 |
+
year={2025},
|
| 185 |
+
url={[https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf](https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf)},
|
| 186 |
+
}
|
| 187 |
+
```
|
figure/before_after_train_lcb_02.png
ADDED

|
Git LFS Details
|
figure/benchmark_accuracy_1130.png
ADDED

|
Git LFS Details
|
figure/inference_pipeline_teaser_02.png
ADDED

|
Git LFS Details
|
figure/teaser_draft_02.png
ADDED

|
Git LFS Details
|
figure/train_reward_response_length_1130.png
ADDED
|
Git LFS Details
|