
zRzRzRzRzRzRzR
commited on
Commit
·
5e8d194
1
Parent(s):
6be8071
update for new format config of transformers lib / sglang lib
Browse files- README.md +6 -8
- config.json +36 -32
- generation_config.json +1 -1
README.md
CHANGED
|
@@ -4,7 +4,7 @@ language:
|
|
| 4 |
- en
|
| 5 |
- zh
|
| 6 |
base_model:
|
| 7 |
-
-
|
| 8 |
pipeline_tag: image-text-to-text
|
| 9 |
library_name: transformers
|
| 10 |
tags:
|
|
@@ -14,13 +14,11 @@ tags:
|
|
| 14 |
# GLM-4.1V-9B-Base
|
| 15 |
|
| 16 |
<div align="center">
|
| 17 |
-
<img src=https://raw.githubusercontent.com/
|
| 18 |
</div>
|
| 19 |
<p align="center">
|
| 20 |
📖 View the GLM-4.1V-9B-Thinking <a href="https://arxiv.org/abs/2507.01006" target="_blank">paper</a>.
|
| 21 |
<br>
|
| 22 |
-
💡 Try the <a href="https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo" target="_blank">Hugging Face</a> or <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo" target="_blank">ModelScope</a> online demo for GLM-4.1V-9B-Thinking.
|
| 23 |
-
<br>
|
| 24 |
📍 Using GLM-4.1V-9B-Thinking API at <a href="https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking">Zhipu Foundation Model Open Platform</a>
|
| 25 |
</p>
|
| 26 |
|
|
@@ -31,14 +29,14 @@ increasingly complex, VLMs must evolve beyond basic multimodal perception to enh
|
|
| 31 |
complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as
|
| 32 |
complex problem solving, long-context understanding, and multimodal agents.
|
| 33 |
|
| 34 |
-
Based on the [GLM-4-9B-0414](https://github.com/
|
| 35 |
**GLM-4.1V-9B-Thinking**, designed to explore the upper limits of reasoning in vision-language models. By introducing
|
| 36 |
a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It
|
| 37 |
achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter
|
| 38 |
Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to
|
| 39 |
support further research into the boundaries of VLM capabilities.
|
| 40 |
|
| 41 |
-
 foundation model, we present the new open-source VLM model
|
| 33 |
**GLM-4.1V-9B-Thinking**, designed to explore the upper limits of reasoning in vision-language models. By introducing
|
| 34 |
a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It
|
| 35 |
achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter
|
| 36 |
Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to
|
| 37 |
support further research into the boundaries of VLM capabilities.
|
| 38 |
|
| 39 |
+
|
| 40 |
|
| 41 |
Compared to the previous generation models CogVLM2 and the GLM-4V series, **GLM-4.1V-Thinking** offers the
|
| 42 |
following improvements:
|
|
|
|
| 54 |
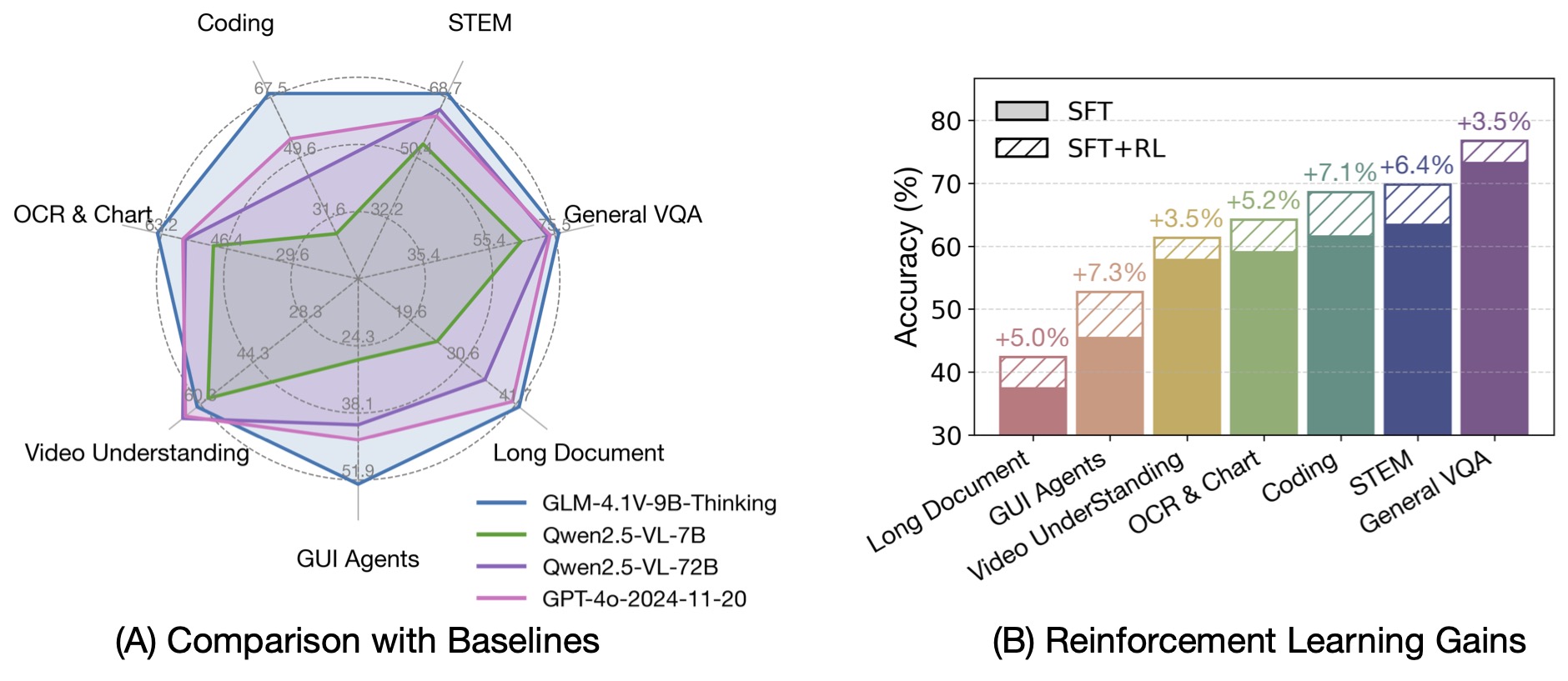
Out of 28 benchmark tasks, it achieved the best performance among 10B-level models on 23 tasks,
|
| 55 |
and even outperformed the 72B-parameter Qwen-2.5-VL-72B on 18 tasks.
|
| 56 |
|
| 57 |
+
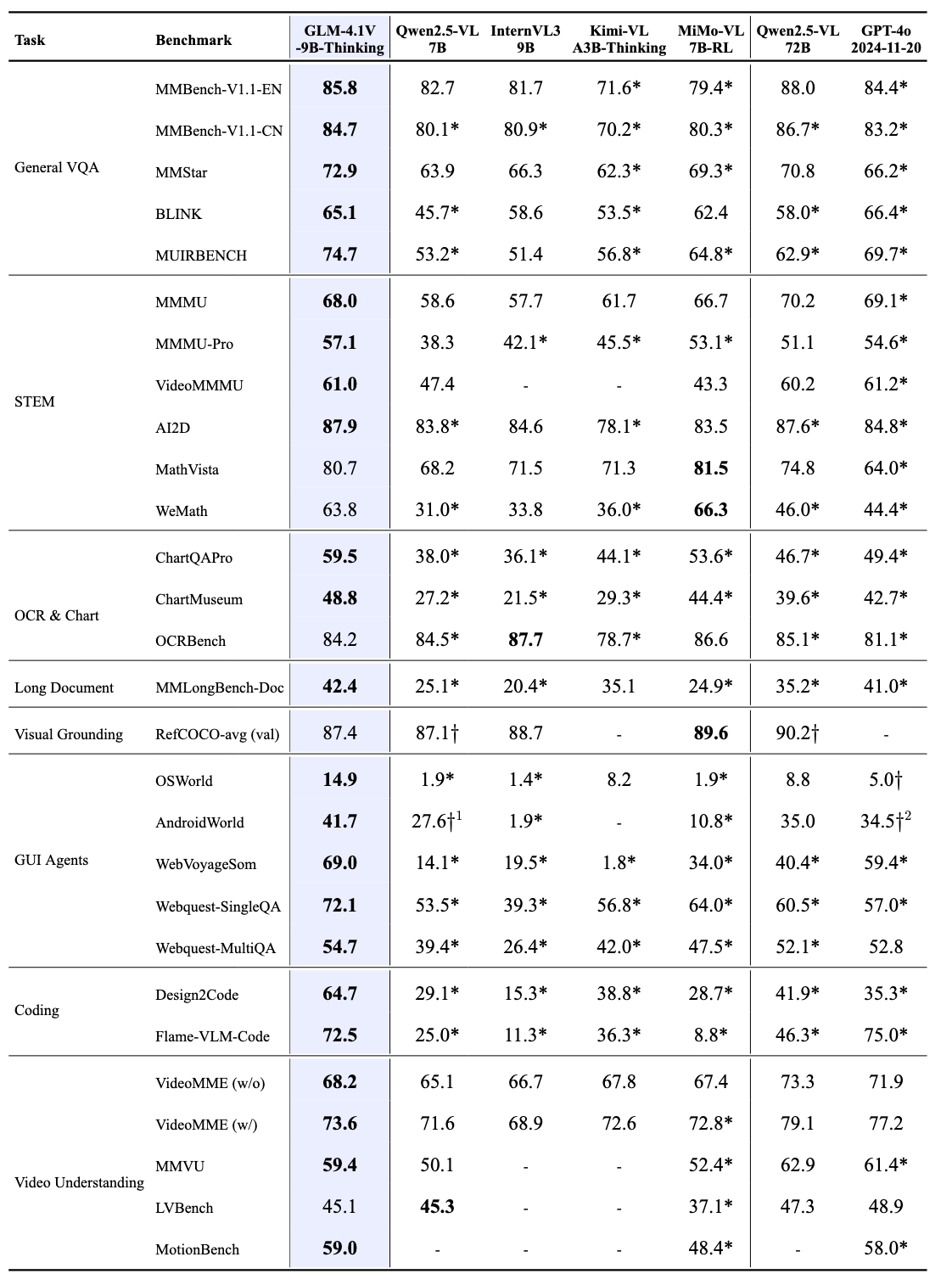
|
| 58 |
|
| 59 |
|
| 60 |
+
For video reasoning, web demo deployment, and more code, please check our [GitHub](https://github.com/zai-org/GLM-V).
|
config.json
CHANGED
|
@@ -3,38 +3,50 @@
|
|
| 3 |
"Glm4vForConditionalGeneration"
|
| 4 |
],
|
| 5 |
"model_type": "glm4v",
|
| 6 |
-
"attention_bias": true,
|
| 7 |
-
"attention_dropout": 0.0,
|
| 8 |
-
"pad_token_id": 151329,
|
| 9 |
-
"eos_token_id": [
|
| 10 |
-
151329,
|
| 11 |
-
151336,
|
| 12 |
-
151338,
|
| 13 |
-
151348
|
| 14 |
-
],
|
| 15 |
"image_start_token_id": 151339,
|
| 16 |
"image_end_token_id": 151340,
|
| 17 |
"video_start_token_id": 151341,
|
| 18 |
"video_end_token_id": 151342,
|
| 19 |
"image_token_id": 151343,
|
| 20 |
"video_token_id": 151344,
|
| 21 |
-
"hidden_act": "silu",
|
| 22 |
-
"hidden_size": 4096,
|
| 23 |
-
"initializer_range": 0.02,
|
| 24 |
-
"intermediate_size": 13696,
|
| 25 |
-
"max_position_embeddings": 65536,
|
| 26 |
-
"num_attention_heads": 32,
|
| 27 |
-
"num_hidden_layers": 40,
|
| 28 |
-
"num_key_value_heads": 2,
|
| 29 |
-
"rms_norm_eps": 1e-05,
|
| 30 |
-
"rope_theta": 10000.0,
|
| 31 |
"tie_word_embeddings": false,
|
| 32 |
-
"
|
| 33 |
-
"
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
"vision_config": {
|
|
|
|
| 38 |
"hidden_size": 1536,
|
| 39 |
"depth": 24,
|
| 40 |
"num_heads": 12,
|
|
@@ -49,13 +61,5 @@
|
|
| 49 |
"rms_norm_eps": 1e-05,
|
| 50 |
"spatial_merge_size": 2,
|
| 51 |
"temporal_patch_size": 2
|
| 52 |
-
},
|
| 53 |
-
"rope_scaling": {
|
| 54 |
-
"type": "default",
|
| 55 |
-
"mrope_section": [
|
| 56 |
-
8,
|
| 57 |
-
12,
|
| 58 |
-
12
|
| 59 |
-
]
|
| 60 |
}
|
| 61 |
}
|
|
|
|
| 3 |
"Glm4vForConditionalGeneration"
|
| 4 |
],
|
| 5 |
"model_type": "glm4v",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
"image_start_token_id": 151339,
|
| 7 |
"image_end_token_id": 151340,
|
| 8 |
"video_start_token_id": 151341,
|
| 9 |
"video_end_token_id": 151342,
|
| 10 |
"image_token_id": 151343,
|
| 11 |
"video_token_id": 151344,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
"tie_word_embeddings": false,
|
| 13 |
+
"transformers_version": "4.57.1",
|
| 14 |
+
"text_config": {
|
| 15 |
+
"model_type": "glm4v_text",
|
| 16 |
+
"attention_bias": true,
|
| 17 |
+
"attention_dropout": 0.0,
|
| 18 |
+
"pad_token_id": 151329,
|
| 19 |
+
"eos_token_id": [
|
| 20 |
+
151329,
|
| 21 |
+
151336,
|
| 22 |
+
151338,
|
| 23 |
+
151348
|
| 24 |
+
],
|
| 25 |
+
"hidden_act": "silu",
|
| 26 |
+
"hidden_size": 4096,
|
| 27 |
+
"initializer_range": 0.02,
|
| 28 |
+
"intermediate_size": 13696,
|
| 29 |
+
"max_position_embeddings": 65536,
|
| 30 |
+
"num_attention_heads": 32,
|
| 31 |
+
"num_hidden_layers": 40,
|
| 32 |
+
"num_key_value_heads": 2,
|
| 33 |
+
"rms_norm_eps": 1e-05,
|
| 34 |
+
"dtype": "bfloat16",
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 151552,
|
| 37 |
+
"partial_rotary_factor": 0.5,
|
| 38 |
+
"rope_theta": 10000,
|
| 39 |
+
"rope_scaling": {
|
| 40 |
+
"rope_type": "default",
|
| 41 |
+
"mrope_section": [
|
| 42 |
+
8,
|
| 43 |
+
12,
|
| 44 |
+
12
|
| 45 |
+
]
|
| 46 |
+
}
|
| 47 |
+
},
|
| 48 |
"vision_config": {
|
| 49 |
+
"model_type": "glm4v",
|
| 50 |
"hidden_size": 1536,
|
| 51 |
"depth": 24,
|
| 52 |
"num_heads": 12,
|
|
|
|
| 61 |
"rms_norm_eps": 1e-05,
|
| 62 |
"spatial_merge_size": 2,
|
| 63 |
"temporal_patch_size": 2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
}
|
| 65 |
}
|
generation_config.json
CHANGED
|
@@ -11,5 +11,5 @@
|
|
| 11 |
"top_p": 0.6,
|
| 12 |
"temperature": 0.8,
|
| 13 |
"top_k": 2,
|
| 14 |
-
"transformers_version": "4.
|
| 15 |
}
|
|
|
|
| 11 |
"top_p": 0.6,
|
| 12 |
"temperature": 0.8,
|
| 13 |
"top_k": 2,
|
| 14 |
+
"transformers_version": "4.57.1"
|
| 15 |
}
|