
license: apache-2.0
Introduction
The goal of Qwen3-VL is not just to “see” images or videos — but to truly understand the world, interpret events, and take action. To achieve this, we’ve systematically upgraded key capabilities, pushing visual models from simple “perception” toward deeper “cognition,” and from basic “recognition” to advanced “reasoning and execution.”

Key Highlights:
Visual Agent Capabilities: Qwen3-VL can operate computer and mobile interfaces — recognize GUI elements, understand button functions, call tools, and complete tasks. It achieves top global performance on benchmarks like OS World, and using tools significantly improves its performance on fine-grained perception tasks.
Greatly Improved Visual Coding: It can now generate code from images or videos — for example, turning a design mockup into Draw.io, HTML, CSS, or JavaScript code — making “what you see is what you get” visual programming a reality.
Much Better Spatial Understanding: It can judge object positions, viewpoint changes, and occlusion relationships. It supports 3D grounding, laying the foundation for complex spatial reasoning and embodied AI applications.
Long Context & Long Video Understanding: All models natively support 256K tokens of context, expandable up to 1 million tokens. This means you can input hundreds of pages of technical documents, entire textbooks, or even two-hour meeting recordings or lecture videos — and the model will remember everything and retrieve details accurately, down to the exact second in videos.
Stronger Multimodal Reasoning (Thinking Version): The Thinking model is specially optimized for STEM and math reasoning. When facing complex subject questions, it can notice fine details, break down problems step by step, analyze cause and effect, and give logical, evidence-based answers. It achieves SOTA performance on authoritative benchmarks like MathVision, MMMU, and MathVista.
Upgraded Visual Perception & Recognition: By improving the quality and diversity of pre-training data, the model can now recognize a much wider range of objects — from celebrities, anime characters, products, and landmarks, to animals and plants — covering both everyday life and professional “recognize anything” needs.
Better OCR Across More Languages & Complex Scenes: OCR now supports 32 languages (up from 19), covering more countries and regions. It performs more reliably under challenging real-world conditions like poor lighting, blur, or tilted text. Recognition accuracy for rare characters, ancient scripts, and technical terms has also improved significantly. Its ability to understand long documents and reconstruct fine structures is further enhanced.
This is the weight repository for Qwen3-VL-235B-A22B-Thinking.
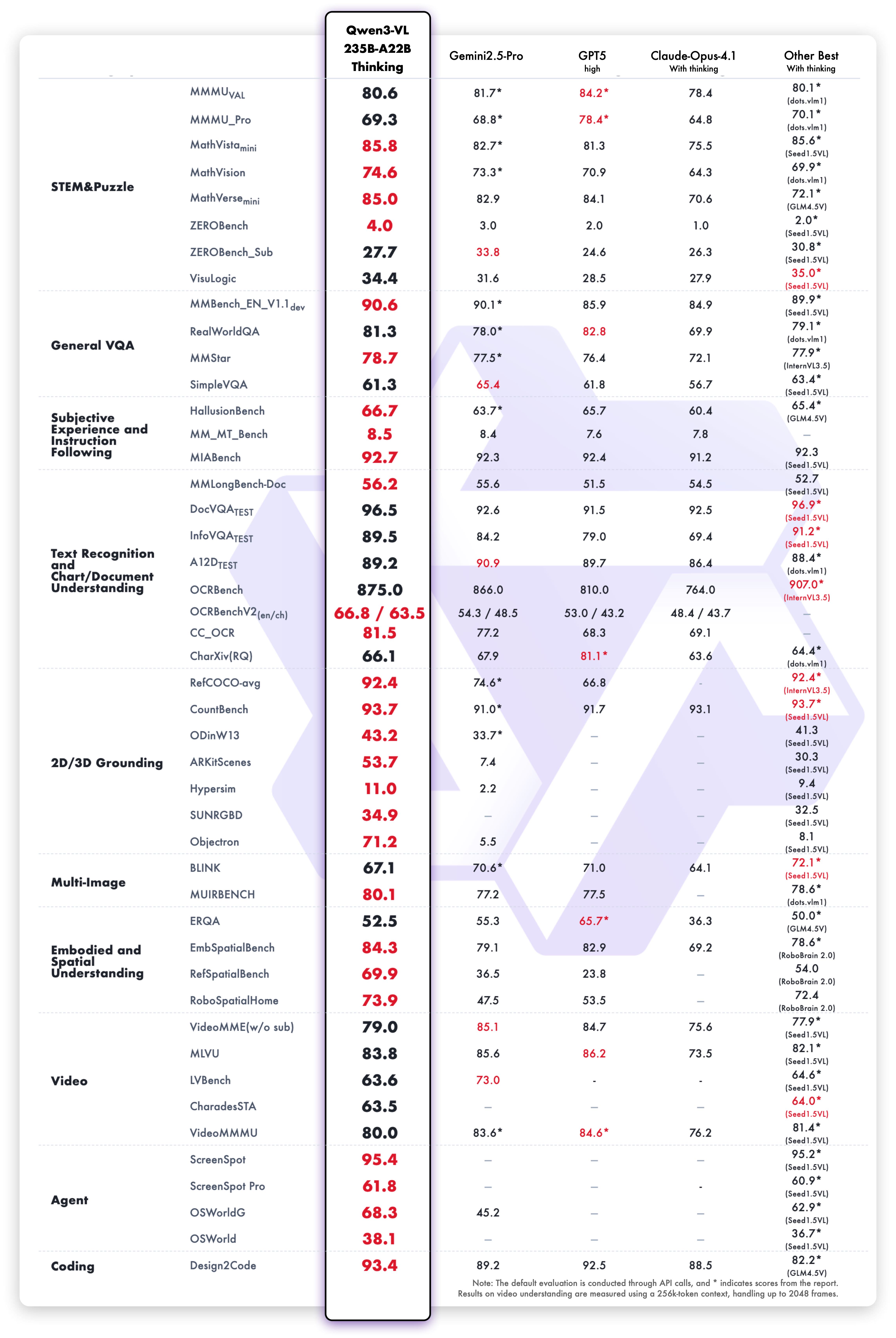
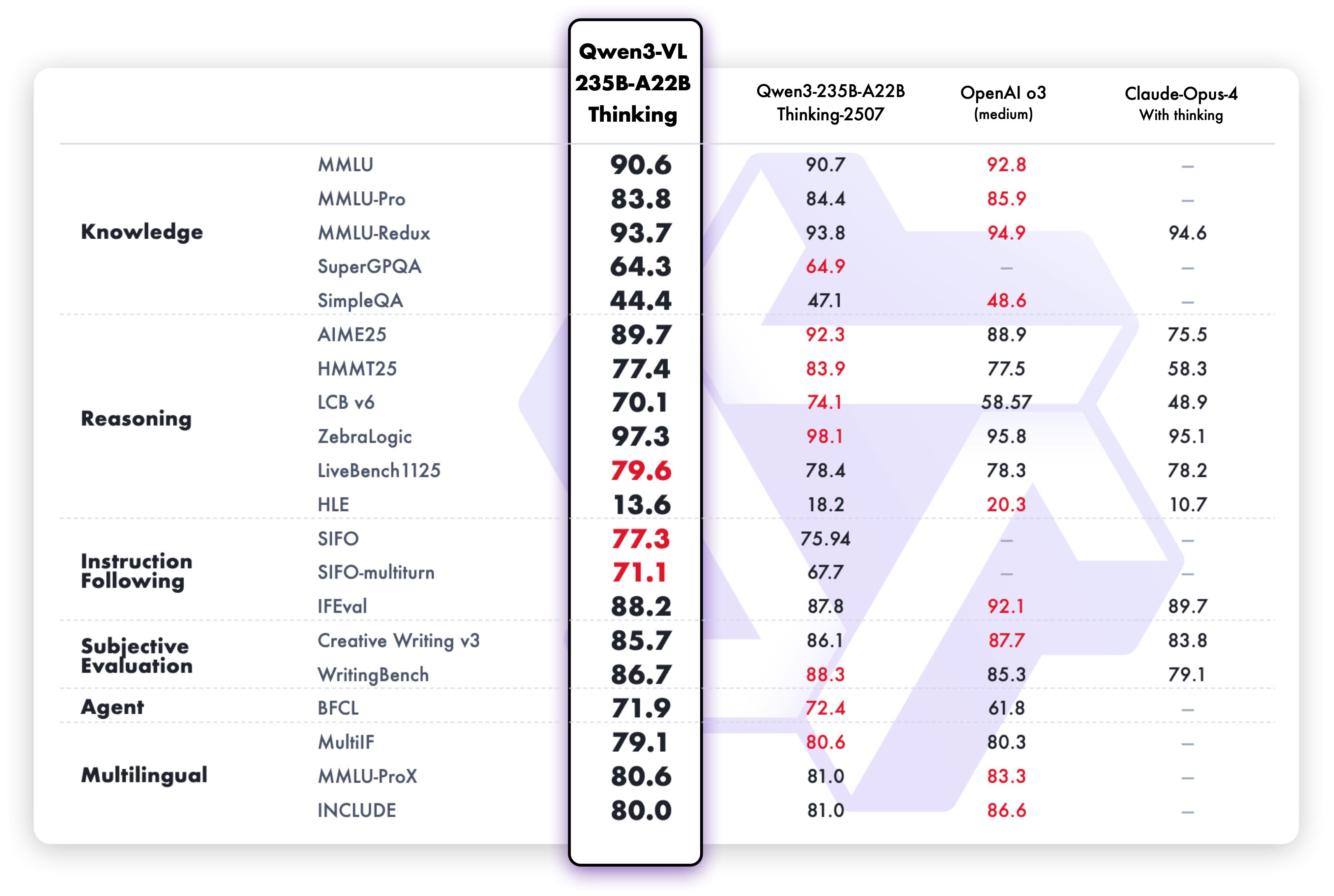
Model Performance
Multimodal performance
Pure text performance
Quickstart
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
The code of Qwen3-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
pip install git+https://github.com/huggingface/transformers
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
Using 🤗 Transformers to Chat
Here we show a code snippet to show you how to use the chat model with transformers:
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
# default: Load the model on the available device(s)
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Thinking", dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
# "Qwen/Qwen3-VL-235B-A22B-Thinking",
# dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Thinking")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen2.5-VL,
title = {Qwen2.5-VL},
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}