
Trendyol/Trendyol-Cybersecurity-LLM-v2-70B-Q4_K_M (Llama‑3.3‑70B Finetuned)
v2-Max is a defense-focused, alignment-safe cybersecurity language model based on Llama-3.3-70B. It was trained via SFT from scratch on the v2 dataset and ranked near the top on CS-Eval in the EN and EN-ZH tracks. Developed by the Trendyol Group Security Team.
Developed Trendyol Group Security Team
- Alican Kiraz
- İsmail Yavuz
- Melih Yılmaz
- Mertcan Kondur
- Rıza Sabuncu
- Özgün Kultekin
We thank Ahmet Gökhan Yalçın, Cenk Çivici, Nezir Alp, Yiğit Darçın for all their support.
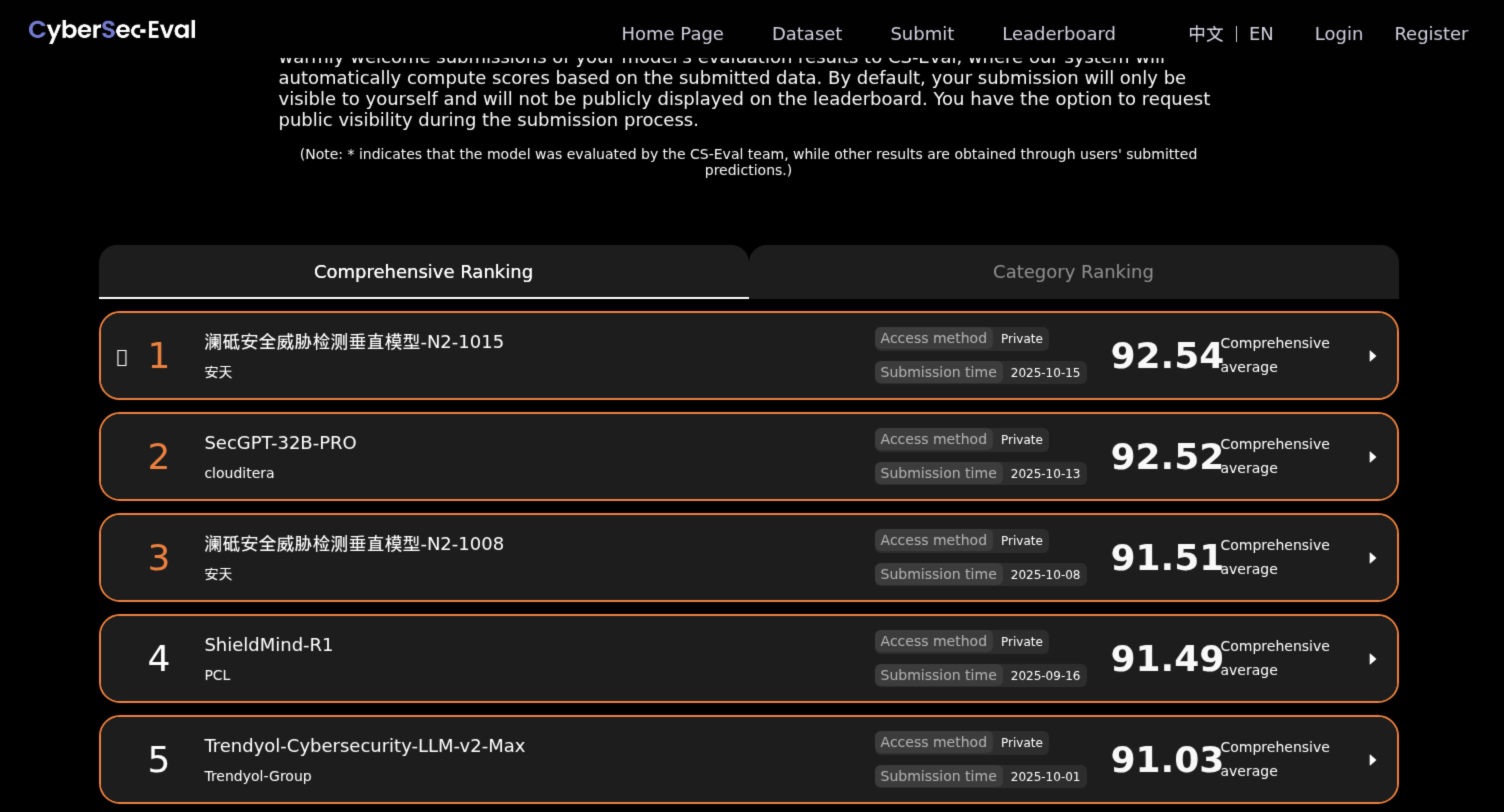
🏆 CS‑Eval Benchmark Results
- English: 3rd place
- English–Chinese: 5th place
- Comprehensive average: 91.03

| Category | Score |
|---|---|
| Fundamentals of System Security and Software Security | 91.33 |
| Access Control and Identity Management | 90.23 |
| Encryption Technology and Key Management | 92.70 |
| Infrastructure Security | 91.85 |
| AI and Network Security | 94.55 |
| Vulnerability Management and Penetration Testing | 90.78 |
| Threat Detection and Prevention | 92.44 |
| Data Security and Privacy Protection | 90.48 |
| Supply Chain Security | 93.69 |
| Security Architecture Design | 87.80 |
| Business Continuity & Emergency Response / Recovery | 85.00 |
| Chinese Task | 91.07 |
🔁 Why v2-Max?
Differences: Old model (Qwen3-14B, “BaronLLM v2.0”) → New model (Llama-3.3-70B, “v2-Max”):
- Base model leap: 14B → 70B (stronger reasoning, long-range context, and standards-compliant answers).
- Dataset: v1.1 (21,258) → v2.0 (83,920) rows (≈4×); coverage includes OWASP, MITRE ATT&CK, NIST CSF, CIS, ASD Essential 8, modern identity (OAuth2/OIDC/SAML), TLS, Cloud & DevSecOps, Cryptography, and AI Security.
- Security gates: adversarial refusal tests against jailbreak/prompt injection, static policy linting, content risk taxonomy; refuse-or-report strategies in system prompts.
- Orientation: offensive examples were removed; defensive, safe outputs are preferred.
📚 v2 Dataset Summary (Alignment-Safe SFT)
Size: 83,920 system/user/assistant triplets
License: Apache-2.0
Language: English
Split: train (100%)
Format: Parquet (columns: system, user, assistant)
Quality Gates: Deduplication, PII scrubbing, hallucination screening, adversarial refusal tests, static policy linting, risk taxonomy, strict schema validations (stable row IDs).
Coverage (key topics):
- OWASP Top 10, MITRE ATT&CK, NIST CSF, CIS Controls, ASD Essential 8
- Modern identity: OAuth 2.0 / OIDC / SAML
- SSL/TLS practices and certificate hygiene
- Cloud & DevSecOps: IAM, secrets management, CI/CD, container/K8s hardening, logging/SIEM, IR runbooks
- Cryptography implementation hygiene
- AI Security (prompt injection, data poisoning, model/embedding security, etc.)
The dataset is commercial-friendly: Apache-2.0. Harmful/exploitative content and high-risk materials such as raw shellcode were excluded during dataset construction; patterns for generating safe alternatives to harmful requests were included.
✨ Features
- Defense-Focused Reasoning: Standards-aligned (OWASP/ATT&CK/NIST/CIS) recommendations with step-by-step explanations that include the “why/evidence.”
- Policy & Architecture Guides: Identity/access, encryption, network segmentation, cloud control sets, data classification, and alert logic.
- IR & Threat Hunting Support: Incident flow, triage checklists, safe log query patterns, playbook skeletons.
- Cloud & DevSecOps: CI/CD security gates, IaC misconfiguration patterns, K8s hardening checklists.
- Refusal-by-Design: Safe alternatives and compliance-aligned response patterns for exploitative/malicious prompts.
Note: This model is SFT-based; it has no tool use, web browsing, or access to an executable environment. In expert operations it is an assistant; it does not, by itself, constitute evidence.
🛠️ Quick Start
Transformers (HF)
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "Trendyol/Trendyol-Cybersecurity-LLM-v2-70B-Q4_K_M"
tok = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
def generate(prompt, max_new_tokens=512, temperature=0.3, top_p=0.9):
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=max_new_tokens,
do_sample=(temperature>0), temperature=temperature, top_p=top_p)
return tok.decode(out[0], skip_special_tokens=True)
print(generate("Map a PCI DSS v4.0 compliance checklist for a multi-account AWS environment."))
vLLM
vllm serve Trendyol/Trendyol-Cybersecurity-LLM-v2-70B-Q4_K_M --dtype bfloat16
GGUF / llama.cpp
For practical single-machine use with a 70B model, Q4_K_M is recommended; higher-quality GGUF variants require much more memory.
🧪 Recommended Prompt Patterns
| Goal | Template | Note |
|---|---|---|
| Risk Assessment | ROLE: Security Architect\nCONTEXT: ...\nTASK: Produce a control-by-control gap analysis against NIST CSF v2.0... |
temperature=0.2–0.4, top_p=0.9 |
| IR Playbook | Create a phase-by-phase incident response playbook for ransomware in hybrid (Azure+on-prem) AD. |
Ask for a validation checklist in the final step. |
| Identity Security | Propose hardened OAuth2/OIDC configs for a multi-tenant SPA+API. |
Request an "abuse cases" list at the end of the response. |
| Cloud Guardrails | Generate K8s hardening controls mapped to CIS + NSA/CISA. |
Include “rationale” and “validation” columns. |
⚖️ Intended Use, Limits, and Safety
Intended Use: Enterprise defense consulting, architectural guidance, control mappings, IR/TI support outputs, training, and documentation.
Prohibited / Limitations:
- Unauthorized penetration testing, PoC exploit/payload generation, instructions that harm live systems.
- Training or enriching outputs with personal data or confidential information.
Model Behavior:
- Explicit refusal for harmful requests + safe alternative suggestions.
- Content policies are tested within the dataset (against jailbreak/prompt injection).
Disclaimer: Model outputs should not be applied automatically without expert review; corporate policy and regulation take precedence.
🔍 Technical Notes
- Training Method: SFT (instruction tuning) + system-prompt guardrails.
- Context Window: Llama-3.3-70B’s default (same as Meta’s release).
- Languages: Training language is English; EN-ZH evaluation is supported.
- Release: Weights under the Meta Llama 3.3 License; dataset under Apache-2.0.
👥 Contributions & Contact
- Issues / Feedback: HF or GitHub Issues
- Research Collaboration: Trendyol Group Security Team
- Acknowledgments: Trendyol Security Team, community contributors, and independent evaluators
🧾 Changelog
- 2025-10-06 — v2-Max: Migration to the Llama-3.3-70B base; v2 dataset with 83,920 rows; alignment security gates; CS-Eval EN #3 / EN-ZH #5, average score 91.03.
- Downloads last month
- 734
4-bit
Model tree for Trendyol/Trendyol-Cybersecurity-LLM-v2-70B-Q4_K_M
Base model
meta-llama/Llama-3.1-70B