TRL documentation
Reducing Memory Usage
Reducing Memory Usage
Training workflows can often be optimized to reduce memory consumption, and TRL provides several built-in features to help achieve this.
Below, we outline these techniques and recommend experimenting with different combinations to figure out which configuration works best for your specific setup.
Each method includes examples for the supported trainers. If you’re unsure whether a technique is compatible with your trainer, please take a look at the corresponding trainer documentation.
For additional strategies, such as gradient checkpointing, which is supported across all trainers, see the transformers performance guide.
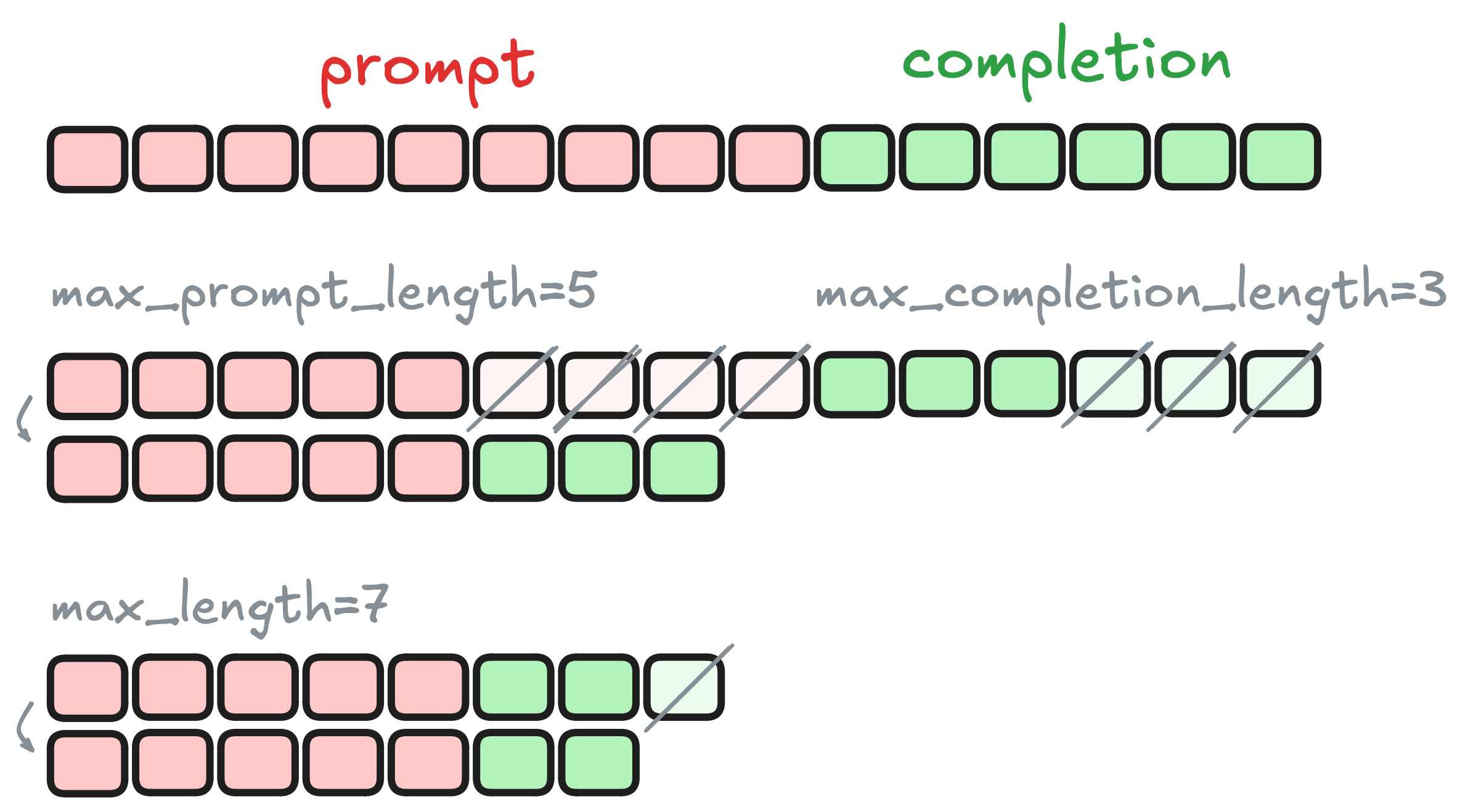
Truncation
Sequence lengths in the dataset can vary widely. When data is batched, sequences are padded to match the longest one in the batch, which can cause high memory usage, even if most sequences are relatively short.

To reduce memory usage, it’s important to truncate sequences to a reasonable length. While TRL trainers truncate sequences by default, you may want to adjust the default truncation length to better align with your specific use case.
DPO truncation is applied first to the prompt and to the completion via the max_prompt_length and max_completion_length parameters. The max_length parameter is then used to truncate the resulting sequence.
To set the truncation parameters, use the following code snippet:
from trl import DPOConfig
training_args = DPOConfig(..., max_prompt_length=..., max_length=...)You can also use the max_completion_length parameter to truncate the completion, though this is less common since the goal is typically to preserve the completion’s full length whenever possible.
from trl import DPOConfig
training_args = DPOConfig(..., max_completion_length=...)How to choose the max_length value?
If max_length is too small, a significant portion of your tokens will be discarded and won’t contribute to training. If it’s too large, memory usage can spike, potentially leading to out-of-memory (OOM) errors. Without packing or padding-free, a large max_length may also result in inefficient training, as many tokens will be padding.
To help you choose an appropriate value, we provide a utility to visualize the sequence length distribution in your dataset.
Packing
This technique is available only for SFT training and setups that use FlashAttention (or its variants).
Truncation has several drawbacks:
- Loss of information: Key data at the end of a sequence may be discarded.
- Choosing truncation length: Too short loses data; too long undermines efficiency.
Packing, introduced in Raffel et al., 2020, addresses these issues by grouping sequences instead of truncating. It concatenates and splits dataset sequences into the desired lengths.

Packing reduces padding by merging several sequences in one row when possible. We use an advanced method to be near-optimal in the way we pack the dataset. To enable packing, use packing=True in the SFTConfig.
In TRL 0.18 and earlier, packing used a more aggressive method that reduced padding to almost nothing, but had the downside of breaking sequence continuity for a large fraction of the dataset. To revert to this strategy, use
packing_strategy="wrapped"in SFTConfig.
from trl import SFTConfig
training_args = SFTConfig(..., packing=True, max_length=512)PEFT for parameter-efficient fine-tuning
Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA are among the most effective techniques for reducing memory usage during training. Instead of training all model parameters, PEFT methods train only a small number of adapter parameters, significantly reducing memory requirements and enabling fine-tuning of larger models on limited hardware.
For comprehensive details on using PEFT with TRL, including various adapter methods, quantization options, and advanced configurations, see PEFT Integration.
To use PEFT for reducing memory usage:
from datasets import load_dataset
from peft import LoraConfig
from trl import SFTTrainer
dataset = load_dataset("trl-lib/Capybara", split="train")
peft_config = LoraConfig()
trainer = SFTTrainer(
model="Qwen/Qwen2.5-0.5B",
train_dataset=dataset,
peft_config=peft_config,
)PEFT can be combined with other memory reduction techniques such as quantization (4-bit or 8-bit) for even greater memory savings. See PEFT Integration for quantization examples.
Liger for reducing peak memory usage
Liger Kernel is a collection of Triton kernels designed specifically for LLM training. It can effectively increase multi-GPU training throughput by 20% and reduce memory usage by 60%.
For more information, see Liger Kernel Integration.
To use Liger for reducing peak memory usage, use the following code snippet:
from trl import SFTConfig
training_args = SFTConfig(..., use_liger_kernel=True)Padding-free
Padding-free batching is an alternative approach for reducing memory usage. In this method, a batch is first sampled and then flattened into a single sequence, avoiding padding. Unlike packing, which can result in incomplete sequences by combining parts of different samples, padding-free batching ensures that all sequences remain complete and intact.
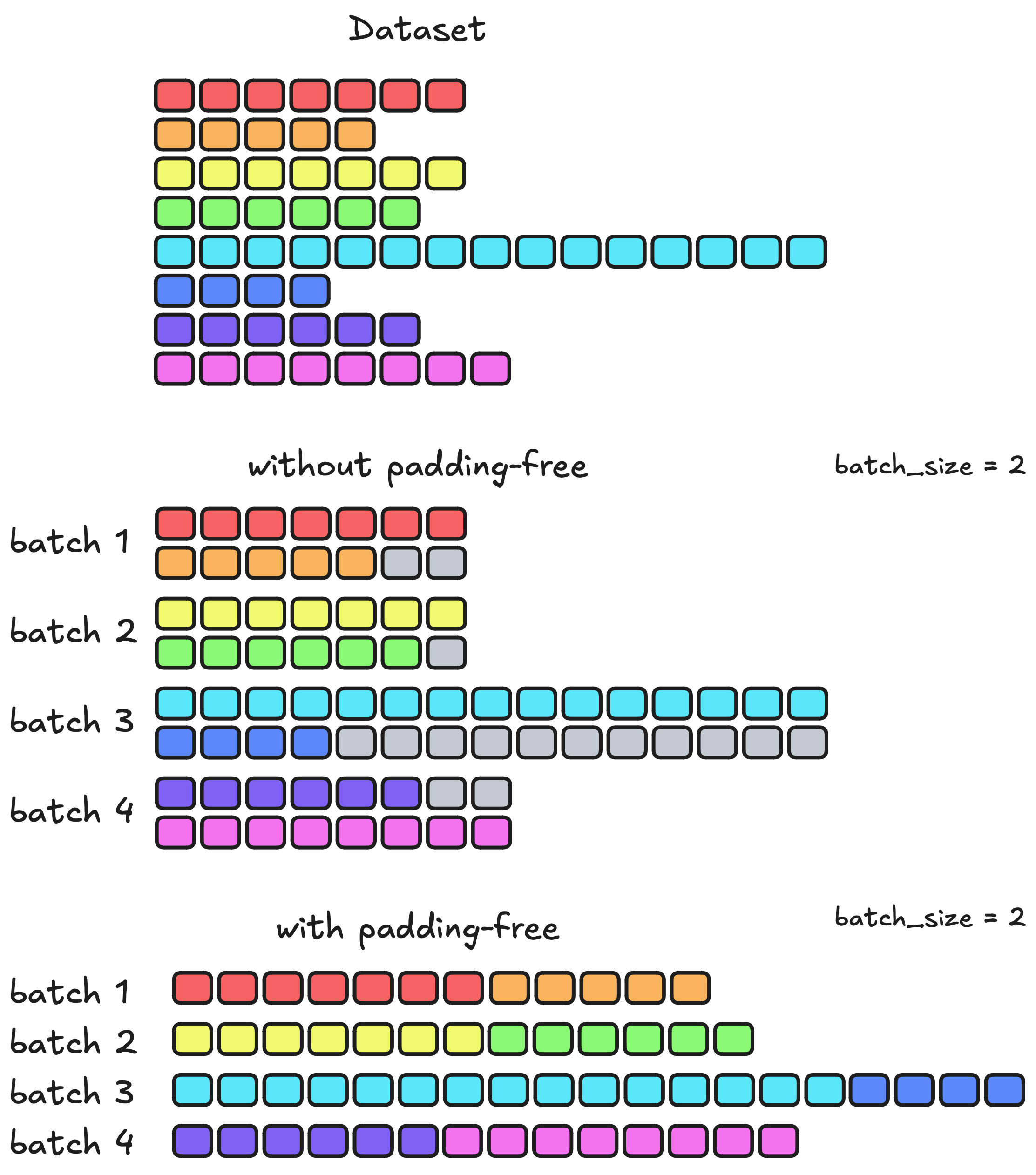
It’s highly recommended to use padding-free batching with FlashAttention 2 or FlashAttention 3. Otherwise, you may encounter batch contamination issues.
from trl import DPOConfig
training_args = DPOConfig(..., padding_free=True, model_init_kwargs={"attn_implementation": "kernels-community/flash-attn2"})Activation offloading
Activation offloading is a memory efficiency technique that reduces GPU VRAM usage by temporarily moving activation tensors to CPU RAM during the forward pass and bringing them back only when needed for the backward pass. This significantly reduces peak memory usage at the cost of slightly increased training time.
To enable activation offloading in your SFT training configuration:
from trl import SFTConfig
training_args = SFTConfig(..., activation_offloading=True)Under the hood, activation offloading implements PyTorch’s saved_tensors_hooks to intercept activations during the forward pass. It intelligently manages which tensors to offload based on size and context, avoiding offloading output tensors that would be inefficient. For performance optimization, it can, via a flag (which is true by default), use CUDA streams to overlap computation with CPU-GPU transfers.
Padding Sequences to a Multiple
This technique is supported for SFT and Reward trainers currently.
When enabled, this option ensures that all sequences are padded to a multiple of the specified value.
This can improve computational efficiency on some hardware by aligning sequence lengths to memory-friendly boundaries.
from trl import SFTConfig
training_args = SFTConfig(..., pad_to_multiple_of=2048)Disabling model gathering for generation in online methods
When using DeepSpeed ZeRO-3, model weights are sharded across multiple GPUs. Online methods involve generating completions from the model as part of the training process. During this step, the model weights are temporarily gathered on a single GPU for generation. For very large models, this gathering can lead to OOM errors, as described in this issue: #2250.
If you encounter this issue, you can disable the gathering of model weights for generation by setting the following parameter:
from trl import GRPOConfig
training_args = GRPOConfig(..., ds3_gather_for_generation=False)This adjustment prevents model weights from being gathered, avoiding OOM errors, but it may result in slower generation speeds.
vLLM sleep mode
When using vLLM as the generation backend for online training methods, you can enable sleep mode to offload vLLM parameters and cache to CPU RAM during the optimization step and reload them back to GPU VRAM when needed for weight synchronization and generation.
from trl import GRPOConfig
training_args = GRPOConfig(..., vllm_enable_sleep_mode=True)Offloading the vLLM weights and cache helps keep GPU memory usage low, which can be particularly beneficial when training large models or using limited GPU resources. However, waking the vLLM engine from sleep mode introduces some host–device transfer latency, which may slightly impact training speed.
Gradient checkpointing
Gradient checkpointing trades compute for memory by not storing all intermediate activations during the forward pass, recomputing them during the backward pass instead.
from trl import SFTConfig
training_args = SFTConfig(..., gradient_checkpointing=True)Gradient checkpointing is available and activated by default across all TRL trainers. For more memory optimization techniques, see the Transformers Performance Guide.
Update on GitHub