
EnAnchored-X2X
Collection
5 items
•
Updated
Llama-2-7B-EAX is a language model specifically enhanced for inter non-English language pairs. The model is built on top of Llama 2, following a two-stage training approach: first, an English-centric parallel data supervised fine-tuning stage (the SFT model is available at Llama-2-7b-MT-SFT), followed by a dedicated x2x optimization stage. This approach strategically leverages the established English-centric capabilities of large language models to bootstrap comprehensive multilingual translation capabilities.
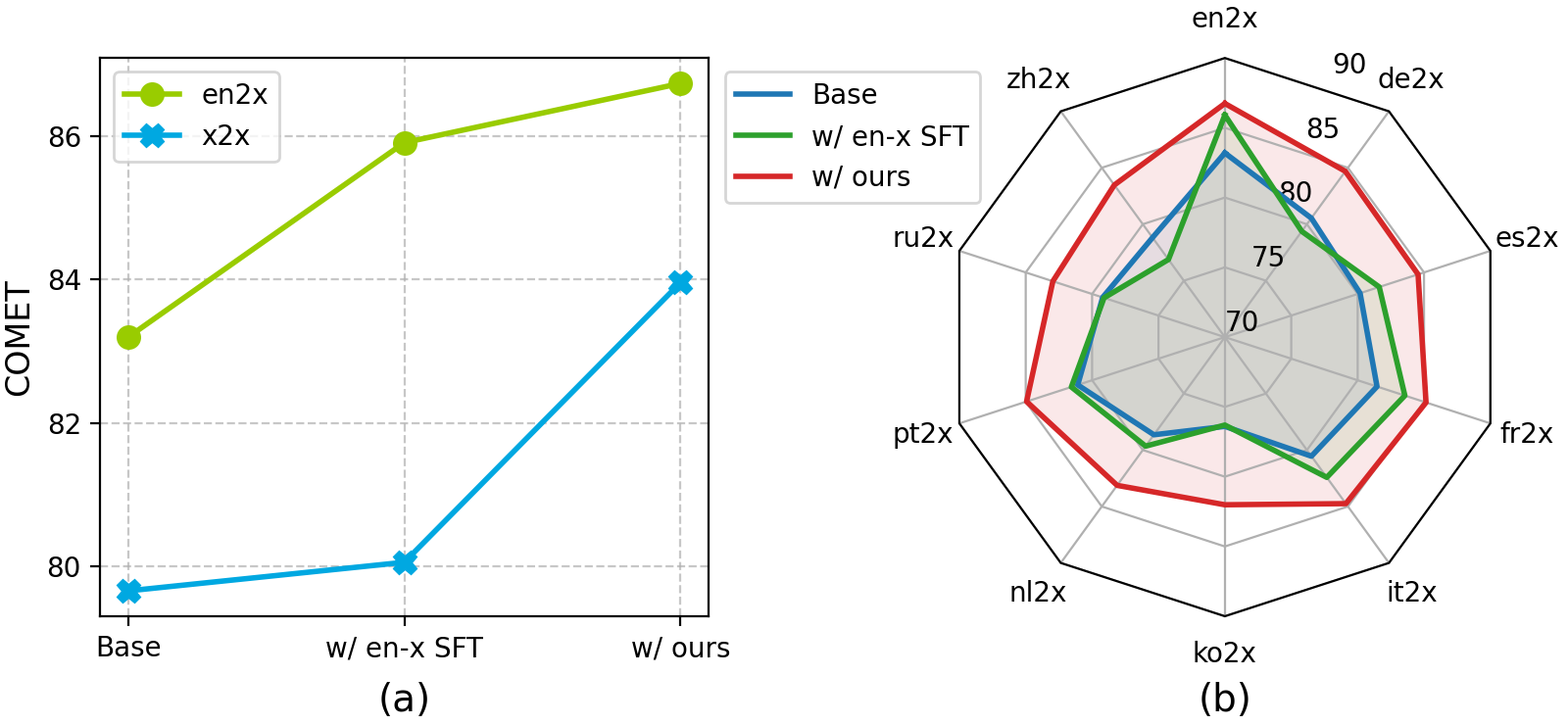
Llama-2-7B-EAX is designed for direct translation between non-English language pairs, addressing a significant gap in current LLM translation capabilities. The model maintains strong performance on English-centric translation while significantly improving x2x translation quality.
Here's how you can run the model with Huggingface Transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_PATH = "double7/Llama-2-7b-EAX"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH, device_map="auto", torch_dtype="auto"
)
src_lang = "German"
trg_lang = "Chinese"
src_text = "Filmkarriere Collinges Filmdebüt in Die kleinen Füchse von 1941 brachte ihr eine Nominierung für den Academy Award als beste Nebendarstellerin ein."
prompt = f"Translate the following text from {src_lang} into {trg_lang}:\n{src_lang}: {src_text}\n{trg_lang}:"
# We use the tokenizer’s chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{"role": "user", "content": prompt},
]
input_text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=256)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=False)[0]
print(output_text)
# <s><|im_start|> user
# Translate the following text from German into Chinese:
# German: Filmkarriere Collinges Filmdebüt in Die kleinen Füchse von 1941 brachte ihr eine Nominierung für den Academy Award als beste Nebendarstellerin ein.
# Chinese:<|im_end|>
# <|im_start|> assistant
# 科林格的电影生涯开始于 1941 年的《小狐狸》,她因此获得了奥斯卡最佳女配角提名。<|im_end|>
Following TowerInstruct, we use diverse translation instructions in training, you can use natural language to describe translation requests, such as:
prompt1 = f"Translate the following text from {src_lang} into {trg_lang}:\n{src_lang}: {src_text}\n{trg_lang}:"
prompt1 = f"Please provide a translation from {src_lang} to {trg_lang} for the following text:\n{src_text}\nTarget:",
prompt2 = f"Translate this {src_lang} text into {trg_lang}:\nSource: {src_text}\nTranslation:",
We use prompt1 for the evaluation.
The model is not guaranteed to perform for languages other than the 10 languages it supports.
Llama-2-7B-EAX has not been aligned to human preferences, so the model may generate problematic outputs (e.g., hallucinations, harmful content, or false statements).
Llama-2-7B-EAX was trained using the ChatML prompt templates without any system prompts. An example follows below:
<|im_start|>user
{USER PROMPT}<|im_end|>
<|im_start|>assistant
{MODEL RESPONSE}<|im_end|>
<|im_start|>user
[...]
We use ~140k high-confidence synthetic data for optimization. This data is based on Llama-2-7b and the translation data from TowerBlocks as seeds, and was curated through our specialized pipeline. See our paper for more details.
The following hyperparameters were used during x2x training:
@misc{yang2025enanchoredx2xenglishanchoredoptimizationmanytomany,
title={EnAnchored-X2X: English-Anchored Optimization for Many-to-Many Translation},
author={Sen Yang and Yu Bao and Yu Lu and Jiajun Chen and Shujian Huang and Shanbo Cheng},
year={2025},
eprint={2509.19770},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.19770},
}