
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/model-cards#model-card-metadata)
GGUF Header Edit Benchmark
Benchmark script for measuring how long it takes to edit GGUF headers in-place on Hugging Face with streaming blobs (xet) and create a pull request per file.
It fetches metadata, rebuilds the header with a small change, commits an edit (header slice only), and records timings to a CSV.
Result from benchmark.ts
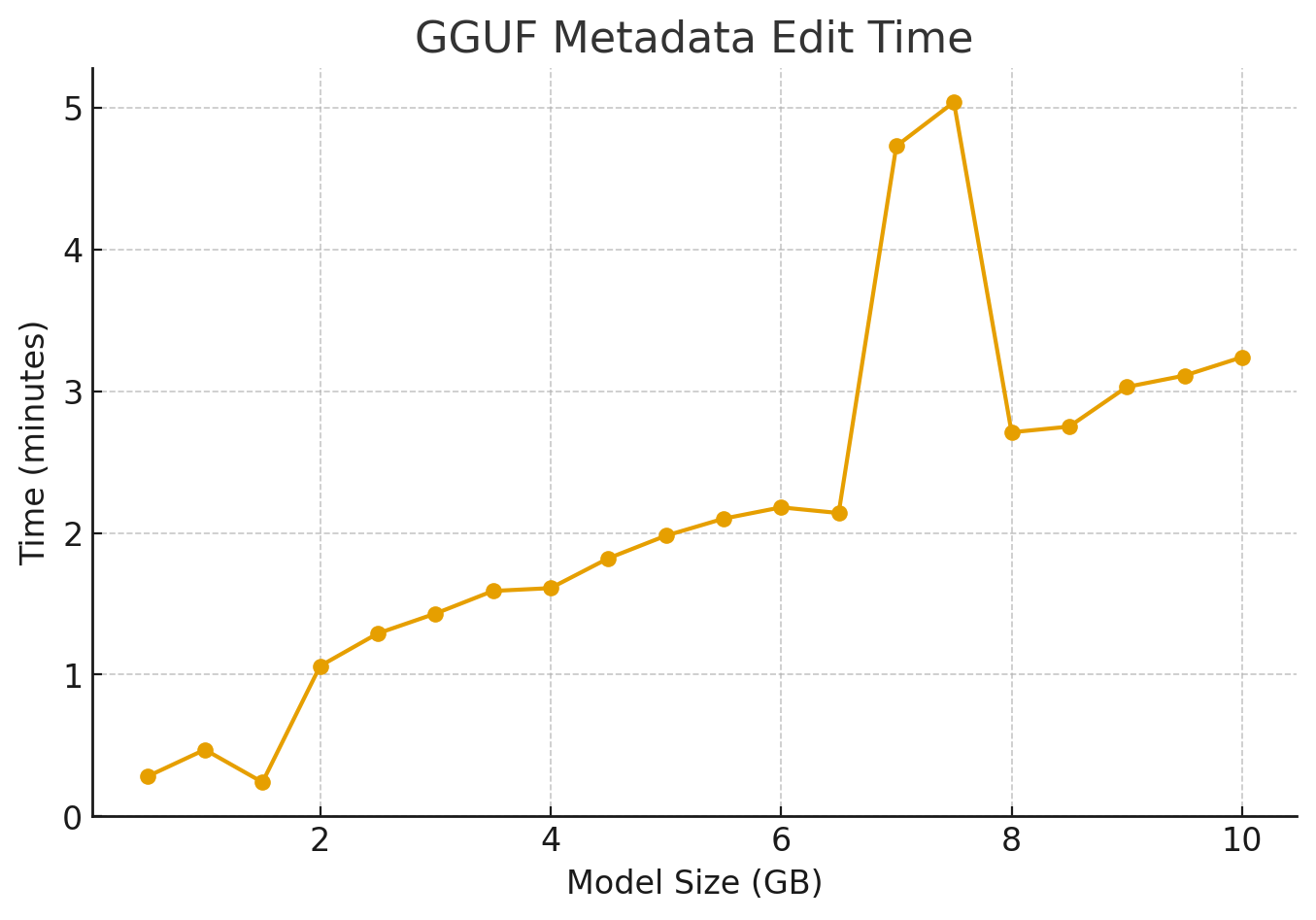
Rule of thumb (linear fit):
time_minutes ≈ 0.36 × size_GB + 0.25
✨ What this does
For each *.gguf file in a model repo:
- Discover files via the Hugging Face model tree API.
- Fetch GGUF + typed metadata with
@huggingface/gguf. - Rebuild the header using
buildGgufHeader(preserving endianness, alignment, and tensor info range). - Commit a slice edit (header bytes only) using
commitIterwithuseXet: trueto avoid full re-uploads. - Create a PR titled
benchmark. - Record timing (wall-clock) to
benchmark-results.csv.
🧱 Requirements
- Node 18+
- A Hugging Face token with read + write on the target repo:
HF_TOKEN - NPM packages:
@huggingface/gguf@huggingface/hub
- Network access to
huggingface.co
🔧 Setup
npm i
npm run benchmark
- Downloads last month
- 4,375
Hardware compatibility
Log In
to view the estimation
We're not able to determine the quantization variants.
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support