Hello, I have some problem making some program and here is the code I made below
%pip install --upgrade pip
%pip install --upgrade transformers datasets[audio] accelerate
import os
os.environ["PATH"] += os.pathsep + r"C:\GPT_AGENT_2025_BOOK\chap05\ffmpeg-2025-10-16-git\bin"
import transformers
print(transformers.__version__)
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
# from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
return_timestamps=True,
chunk_length_s=10,
stride_length_s=2,
)
# dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
# sample = dataset[0]["audio"]
sample = "./lsy_audio_2023_58s.mp3"
result = pipe(sample)
# print(result["text"])
print(result)
and this code gives me error below
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[8], line 36
32 # dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
33 # sample = dataset[0]["audio"]
34 sample = "./lsy_audio_2023_58s.mp3"
---> 36 result = pipe(sample)
37 # print(result["text"])
39 print(result)
File c:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\transformers\pipelines\automatic_speech_recognition.py:275, in AutomaticSpeechRecognitionPipeline.__call__(self, inputs, **kwargs)
218 def __call__(self, inputs: Union[np.ndarray, bytes, str, dict], **kwargs: Any) -> list[dict[str, Any]]:
219 """
220 Transcribe the audio sequence(s) given as inputs to text. See the [`AutomaticSpeechRecognitionPipeline`]
221 documentation for more information.
(...) 273 `"".join(chunk["text"] for chunk in output["chunks"])`.
274 """
--> 275 return super().__call__(inputs, **kwargs)
File c:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\transformers\pipelines\base.py:1459, in Pipeline.__call__(self, inputs, num_workers, batch_size, *args, **kwargs)
1457 return self.iterate(inputs, preprocess_params, forward_params, postprocess_params)
1458 elif self.framework == "pt" and isinstance(self, ChunkPipeline):
-> 1459 return next(
1460 iter(
1461 self.get_iterator(
...
FFmpeg version 7: Could not load this library: C:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\torchcodec\libtorchcodec_core7.dll
FFmpeg version 6: Could not load this library: C:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\torchcodec\libtorchcodec_core6.dll
FFmpeg version 5: Could not load this library: C:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\torchcodec\libtorchcodec_core5.dll
FFmpeg version 4: Could not load this library: C:\Users\majh0\AppData\Local\Programs\Python\Python312\Lib\site-packages\torchcodec\libtorchcodec_core4.dll
[end of libtorchcodec loading traceback].
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
It says it cannot load some .dll files… there are dll files it needs like picture below….
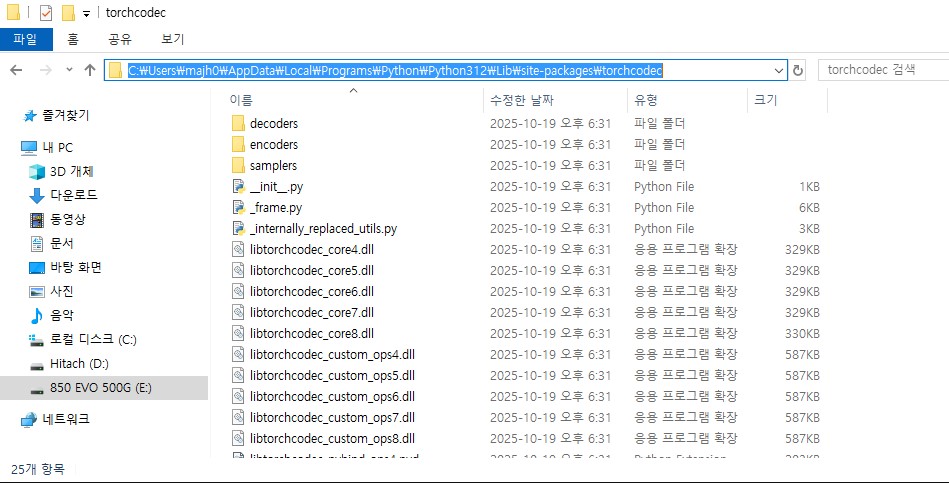
It is really hard to find out that why this thing cannot load the .dll files even if the files are in the proper directory…
Thank you so much for the help in advance…


