
🎯 Namo Turn Detector v1 - MultiLingual
![]()
🚀 Namo Turn Detection Model for Multiple Languages
🇸🇦 Arabic, 🇮🇳 Bengali, 🇨🇳 Chinese, 🇩🇰 Danish, 🇳🇱 Dutch, 🇩🇪 German, 🇬🇧🇺🇸 English, 🇫🇮 Finnish, 🇫🇷 French, 🇮🇳 Hindi, 🇮🇩 Indonesian, 🇮🇹 Italian, 🇯🇵 Japanese, 🇰🇷 Korean, 🇮🇳 Marathi, 🇳🇴 Norwegian, 🇵🇱 Polish, 🇵🇹 Portuguese, 🇷🇺 Russian, 🇪🇸 Spanish, 🇹🇷 Turkish, 🇺🇦 Ukrainian, and 🇻🇳 Vietnamese
📋 Overview
The Namo Turn Detector is a specialized AI model designed to solve one of the most challenging problems in conversational AI: knowing when a user has finished speaking.
This Multilingual model uses advanced natural language understanding to distinguish between:
- ✅ Complete utterances (user is done speaking)
- 🔄 Incomplete utterances (user will continue speaking)
Built on mmBERT architecture and optimized with quantized ONNX format, it delivers enterprise-grade performance with minimal latency.
🔑 Key Features
- Turn Detection Specialist: Detects end-of-turn vs. continuation in multilingual speech transcripts.
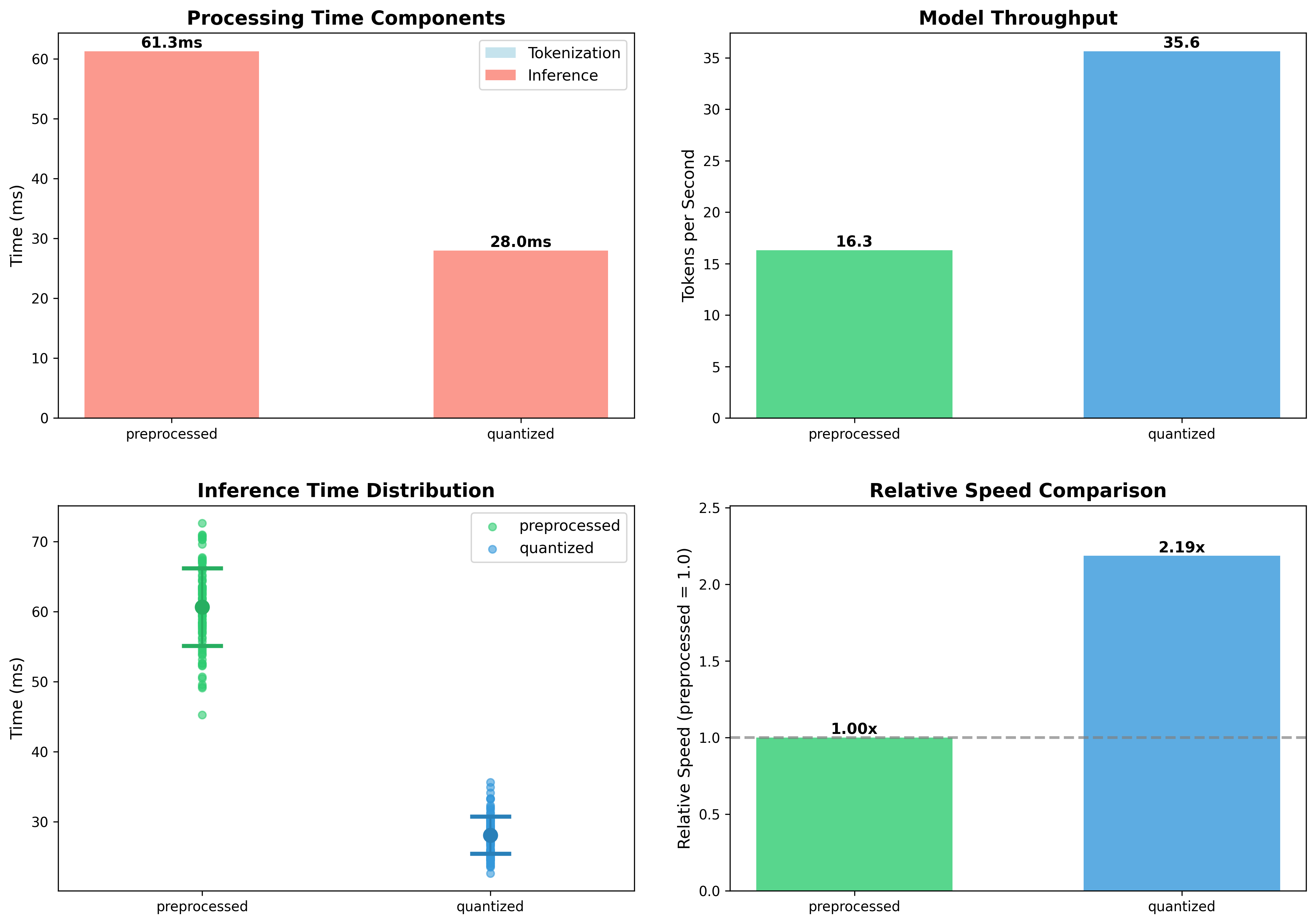
- Low Latency: Optimized with quantized ONNX for <29ms inference.
- Robust Performance: Average 90.25% accuracy on multilingual utterances.
- Easy Integration: Compatible with Python, ONNX Runtime, and VideoSDK Agents SDK.
- Enterprise Ready: Supports real-time conversational AI and voice assistants.
📊 Performance Metrics
| Metric | Score |
|---|---|
| ⚡ Latency | <29ms |
| 💾 Model Size | ~295MB |
| Language | Accuracy | Precision | Recall | F1 Score | Samples |
|---|---|---|---|---|---|
| 🇹🇷 Turkish | 0.9731 | 0.9611 | 0.9853 | 0.9730 | 966 |
| 🇰🇷 Korean | 0.9685 | 0.9541 | 0.9842 | 0.9690 | 890 |
| 🇩🇪 German | 0.9425 | 0.9135 | 0.9772 | 0.9443 | 1322 |
| 🇯🇵 Japanese | 0.9436 | 0.9099 | 0.9857 | 0.9463 | 834 |
| 🇮🇳 Hindi | 0.9398 | 0.9276 | 0.9603 | 0.9436 | 1295 |
| 🇳🇱 Dutch | 0.9279 | 0.8959 | 0.9738 | 0.9332 | 1401 |
| 🇳🇴 Norwegian | 0.9165 | 0.8717 | 0.9801 | 0.9227 | 1976 |
| 🇨🇳 Chinese | 0.9164 | 0.8859 | 0.9608 | 0.9219 | 945 |
| 🇫🇮 Finnish | 0.9158 | 0.8746 | 0.9702 | 0.9199 | 1010 |
| 🇬🇧 English | 0.9086 | 0.8507 | 0.9801 | 0.9108 | 2845 |
| 🇮🇩 Indonesian | 0.9022 | 0.8514 | 0.9707 | 0.9071 | 971 |
| 🇮🇹 Italian | 0.9015 | 0.8562 | 0.9640 | 0.9069 | 782 |
| 🇵🇱 Polish | 0.9068 | 0.8619 | 0.9568 | 0.9069 | 976 |
| 🇵🇹 Portuguese | 0.8956 | 0.8410 | 0.9676 | 0.8999 | 1398 |
| 🇩🇰 Danish | 0.8973 | 0.8517 | 0.9644 | 0.9045 | 779 |
| 🇪🇸 Spanish | 0.8888 | 0.8304 | 0.9681 | 0.8940 | 1295 |
| 🇮🇳 Marathi | 0.8850 | 0.8762 | 0.9008 | 0.8883 | 774 |
| 🇷🇺 Russian | 0.8748 | 0.8318 | 0.9547 | 0.8890 | 1470 |
| 🇺🇦 Ukrainian | 0.8794 | 0.8164 | 0.9587 | 0.8819 | 929 |
| 🇻🇳 Vietnamese | 0.8645 | 0.8135 | 0.9439 | 0.8738 | 1004 |
| 🇸🇦 Arabic | 0.8490 | 0.7965 | 0.9439 | 0.8639 | 947 |
| 🇮🇳 Bengali | 0.7940 | 0.7874 | 0.7939 | 0.7907 | 1000 |
📊 Evaluated on 25,000+ Multilingual utterances from diverse conversational contexts
⚡️ Speed Analysis
🔧 Train & Test Scripts
🛠️ Installation
To use this model, you will need to install the following libraries.
pip install onnxruntime transformers huggingface_hub
🚀 Quick Start
You can run inference directly from Hugging Face repository.
import numpy as np
import onnxruntime as ort
from transformers import AutoTokenizer
from huggingface_hub import hf_hub_download
class TurnDetector:
def __init__(self, repo_id="videosdk-live/Namo-Turn-Detector-v1-Multilingual"):
"""
Initializes the detector by downloading the model and tokenizer
from the Hugging Face Hub.
"""
print(f"Loading model from repo: {repo_id}")
# Download the model and tokenizer from the Hub
# Authentication is handled automatically if you are logged in
model_path = hf_hub_download(repo_id=repo_id, filename="model_quant.onnx")
self.tokenizer = AutoTokenizer.from_pretrained(repo_id)
# Set up the ONNX Runtime inference session
self.session = ort.InferenceSession(model_path)
self.max_length = 8192
print("✅ Model and tokenizer loaded successfully.")
def predict(self, text: str) -> tuple:
"""
Predicts if a given text utterance is the end of a turn.
Returns (predicted_label, confidence) where:
- predicted_label: 0 for "Not End of Turn", 1 for "End of Turn"
- confidence: confidence score between 0 and 1
"""
# Tokenize the input text
inputs = self.tokenizer(
text,
truncation=True,
max_length=self.max_length,
return_tensors="np"
)
# Prepare the feed dictionary for the ONNX model
feed_dict = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"]
}
# Run inference
outputs = self.session.run(None, feed_dict)
logits = outputs[0]
probabilities = self._softmax(logits[0])
predicted_label = np.argmax(probabilities)
confidence = float(np.max(probabilities))
return predicted_label, confidence
def _softmax(self, x, axis=None):
if axis is None:
axis = -1
exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
# --- Example Usage ---
if __name__ == "__main__":
detector = TurnDetector()
sentences = [
"They're often made with oil or sugar.", # Expected: End of Turn
"I think the next logical step is to", # Expected: Not End of Turn
"What are you doing tonight?", # Expected: End of Turn
"The Revenue Act of 1862 adopted rates that increased with", # Expected: Not End of Turn
]
for sentence in sentences:
predicted_label, confidence = detector.predict(sentence)
result = "End of Turn" if predicted_label == 1 else "Not End of Turn"
print(f"'{sentence}' -> {result} (confidence: {confidence:.3f})")
print("-" * 50)
🤖 VideoSDK Agents Integration
Integrate this turn detector directly with VideoSDK Agents for production-ready conversational AI applications.
from videosdk_agents import NamoTurnDetectorV1, pre_download_namo_turn_v1_model
#download model
pre_download_namo_turn_v1_model()
# Initialize Multilingual turn detector for VideoSDK Agents
turn_detector = NamoTurnDetectorV1()
📚 Complete Integration Guide - Learn how to use
NamoTurnDetectorV1with VideoSDK Agents
📖 Citation
@model{namo_turn_detector_en_2025,
title={Namo Turn Detector v1: Multilingual},
author={VideoSDK Team},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/videosdk-live/Namo-Turn-Detector-v1-Multilingual},
note={ONNX-optimized mmBERT for turn detection in 23 Languages}
}
📄 License
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
Made with ❤️ by the VideoSDK Team
- Downloads last month
- 42
Model tree for videosdk-live/Namo-Turn-Detector-v1-Multilingual
Base model
jhu-clsp/mmBERT-baseEvaluation results
- accuracy on Namo Turn Detector v1 Test - Multilingualself-reported0.902