
Add initial dataset card for World-in-World
#1
by
nielsr
HF Staff
- opened
README.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
task_categories:
|
| 3 |
+
- robotics
|
| 4 |
+
tags:
|
| 5 |
+
- world-model
|
| 6 |
+
- embodied-ai
|
| 7 |
+
- benchmark
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# World-in-World Dataset
|
| 11 |
+
|
| 12 |
+
World-in-World is the first open platform designed to benchmark visual world models (WMs) in a **closed-loop world** that rigorously mirrors real agent-environment interactions. This dataset is part of a unified framework that provides a standardized action API and an online planning strategy, enabling the evaluation of diverse WMs for decision-making in embodied tasks. The benchmark prioritizes **task success** and **embodied utility** over mere visual quality.
|
| 13 |
+
|
| 14 |
+
- **Paper**: [World-in-World: World Models in a Closed-Loop World](https://huggingface.co/papers/2510.18135)
|
| 15 |
+
- **Project Page**: [https://world-in-world.github.io/](https://world-in-world.github.io/)
|
| 16 |
+
- **Code Repository**: [https://github.com/World-In-World/world-in-world](https://github.com/World-In-World/world-in-world)
|
| 17 |
+
|
| 18 |
+
## Overview
|
| 19 |
+
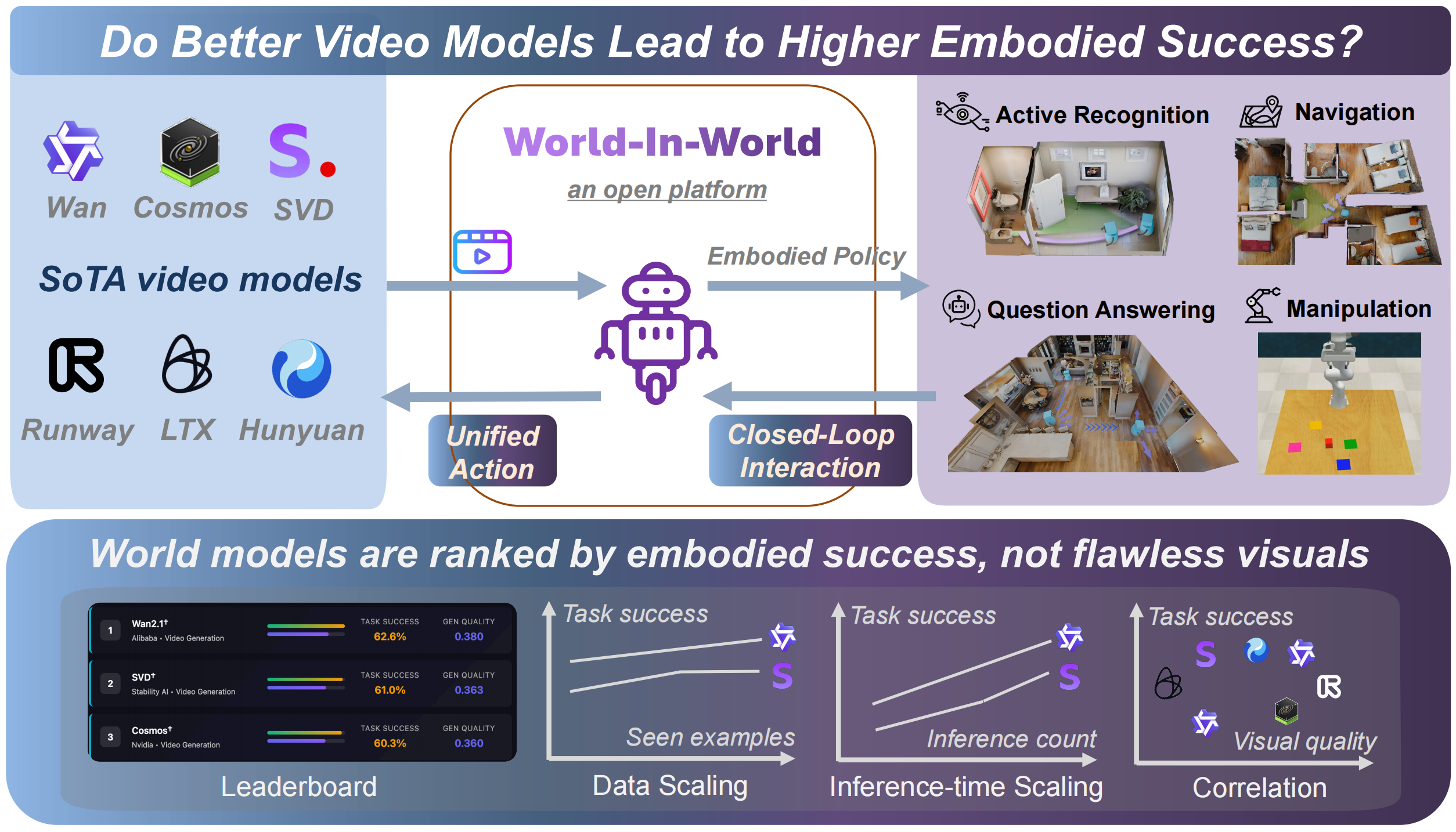
|
| 20 |
+
|
| 21 |
+
This platform wraps generative World models In a closed-loop World interface to measure their practical utility for embodied agents. It is designed to test whether generated worlds actually enhance embodied reasoning and task performance—for example, helping an agent perceive the environment, plan and execute actions, and re-plan based on new observations within such a closed loop. This framework is crucial for tracking genuine progress in visual world models and embodied AI.
|
| 22 |
+
|
| 23 |
+
## Tasks and Environments
|
| 24 |
+
The World-in-World benchmark includes datasets and evaluation episodes for a suite of closed-loop environments, covering:
|
| 25 |
+
- **Active Recognition (AR)**
|
| 26 |
+
- **Active Embodied QA (A-EQA)**
|
| 27 |
+
- **Image-Goal Navigation (IGNav)**
|
| 28 |
+
- **Robotic Manipulation**
|
| 29 |
+
|
| 30 |
+
These tasks are designed to evaluate how well world models contribute to an agent's ability to perceive, plan, and act effectively within dynamic environments.
|
| 31 |
+
|
| 32 |
+
## Getting Started
|
| 33 |
+
The World-in-World dataset components, including scene datasets (e.g., MP3D, HM3D) and pre-defined evaluation episodes for various tasks, are available and described in detail within the [official GitHub repository's documentation](https://github.com/World-In-World/world-in-world).
|
| 34 |
+
|
| 35 |
+
For comprehensive instructions on environment setup, downloading specific scene and evaluation datasets, deploying policies, and running evaluation scripts, please refer to the following documentation files in the GitHub repository:
|
| 36 |
+
- [01_setup_env.md](https://github.com/World-In-World/world-in-world/blob/main/docs/01_setup_env.md): Environment setup for all environments.
|
| 37 |
+
- [02_evaluation_datasets.md](https://github.com/World-In-World/world-in-world/blob/main/docs/02_evaluation_datasets.md): Datasets used for evaluation.
|
| 38 |
+
- [03_run_commands.md](https://github.com/World-In-World/world-in-world/blob/main/docs/03_run_commands.md): How to deploy servers and run evaluation scripts.
|
| 39 |
+
|
| 40 |
+
## Citation
|
| 41 |
+
If you find this work useful, please cite:
|
| 42 |
+
```bibtex
|
| 43 |
+
@misc{zhang2025worldinworld,
|
| 44 |
+
title = {World-in-World: World Models in a Closed-Loop World},
|
| 45 |
+
author = {Zhang, Jiahan and Jiang, Muqing and Dai, Nanru and Lu, Taiming and Uzunoglu, Arda and Zhang, Shunchi and Wei, Yana and Wang, Jiahao and Patel, Vishal M. and Liang, Paul Pu and Khashabi, Daniel and Peng, Cheng and Chellappa, Rama and Shu, Tianmin and Yuille, Alan and Du, Yilun and Chen, Jieneng},
|
| 46 |
+
year = {2025},
|
| 47 |
+
eprint = {2510.18135},
|
| 48 |
+
archivePrefix= {arXiv},
|
| 49 |
+
}
|
| 50 |
+
```
|